VALLOIS & JULLIEN: Is Experimental Economics Really Doing Better? The Case of Public Goods Experiments
[From the working paper, “Replication in experimental economics: A historical and quantitative approach focused on public good game experiments” by Nicolas Vallois and Dorian Jullien]
The current “replication crisis” concerns the inability of scientists to “replicate”, i.e. to reproduce a great number of their empirical findings. Many disciplines are concerned. Yet things appear to be better in experimental economics (EE). 61,1% of experimental results were successfully replicated in a large, collaborative project recently published by eminent experimental economists in Science (Camerer et al., 2016). The authors suggest that EE’s results are relatively more reproducible and robust than in psychology, where a similar study found a replication rate of 38% (Collaboration et al., 2015).
In our article, “Replication in experimental economics: A historical and quantitative approach focused on public good game experiments”, we provide a different perspective on the place of EE within the replication crisis. Our methodological innovation consists of looking at what we call “baseline replication”. The idea is straightforward. Experimental results are usually reported as a significant difference between a so-called “baseline condition” (or “control group”) and a treatment condition (usually similar to the baseline expect for one detail). For a given type of experiments in economics, most studies will have a baseline condition that is similar or very close to another baseline condition, so that, overall, it make sense to check whether the observation in a given baseline condition is close to the average observation across all baseline conditions. “Baseline replication” refers to the fact that results in baseline conditions of similar experiments are converging toward the same level. In other words, while most studies investigate replications of “effects” between baseline and treatment conditions, we abstract from treatment conditions to look only at baseline replication.
Our observations are restricted to a specific type of economic experiments: public goods (PG) game experiments. We chose the PG game because the field is relatively homogeneous and representative of the whole discipline of EE. A typical PG game consists of a group of subjects, each of which has money (experimental tokens) that can be used either to contribute to a PG (yielding returns to all the subjects in the group) or to invest in a private good (yielding returns only to the investor).
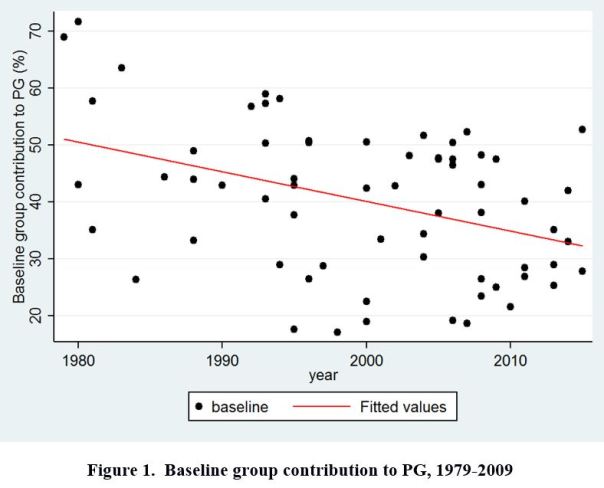
Our data set consists of 66 published papers on PG game experiments. Sampling methods are described in the paper. We collected the baseline result of each study, i.e. mean contribution rate in the baseline condition. Figure 1 (below) provides a graphical display of our data.
 Our results are twofold:
Our results are twofold:
– First, there is a slight yet significant tendency for baseline results to converge over time. But the effect is very noisy and still allows for a substantial amount of between-studies variation in the more recent time period.
– Second, there is also a strongly significant decline of baseline results over time. The size effect is large: results in control conditions have decreased on average by 20% from 1979 to 2015.
The first result (slight convergence) suggests that baseline replication over time plays the role of a “weak constraint” on experimental results. Very high contribution rates (superior to 60%) are less likely to be found in the 2000’s-2010’s. But the fluctuation range remains important and a 50% baseline contribution rate might still seem acceptable in the 2010’s (where average baseline is 32,9%).
The second result (decrease of baseline results over time) was unexpected and seemingly unrelated to our initial question, since we were investigating convergence between experimental results, and not their decrease or increase over time. The 20% decrease in baseline contribution from 1979 to 2015 might suggest that early results were overestimated. A classical explanation for overestimation of size effect in empirical sciences is publication bias. Impressive results are easier to get published at first; once the research domain gets legitimized, publication practices favor more “normal” size effects
Hence, a first optimistic interpretation of both results is that lab experiments are “self-correcting” over time. Less and less exceptionally high control results are found in later time periods, meaning that initial overestimation of size effects is then corrected.
A second, less optimistic (though not pessimistic per se) interpretation, is that both convergence and decrease in baseline results are the effect of a tendency toward standardization in experimental designs. Experimental protocols in the 2000’s-2010’s for baseline conditions indeed seem to be more and more similar. Similar experiments can be expected to yield similar results. But it does not necessarily constitute a scientific improvement. More homogeneous experimental methods might be the result of mimetic dynamics in research and might not measure the “real” contribution to PG in the “real world”. If we suppose that the real rate is somewhere around 70%, initial high results in the 1980’s would be actually closer to the real size effect than the 32,91% average contribution rate found in the 2010’s
To test this hypothesis about “standardization”, we collected data about two important experimental parameters: the marginal per capita return (i.e., by how much each dollar contributed to the PG is multiplied before redistribution of the whole PG) and group size. We observe a clear tendency toward standardization from 1979 to 2015. After 2000, about two-third of PG games use the same basic experimental protocol with 4 or 5 persons-groups and a linear PG payoff yielding an exact and fixed return of 0,3 or 0,4 or 0,5; whereas those values were found only in approximately one experiment out of four in the 1980’s.
To conclude on our initial question, EE is not immune to the replication crisis. We found that baseline replication provides a “weak constraint” on experimental results. This might explain why EE performed relatively better than experimental psychology in the recent replication survey mentioned above (Camerer et al., 2016). We therefore agree with Camerer et al. on the “relatively good replication success” of EE (compared to psychology). Yet we disagree on the interpretation of this result. According to many experimental economists, EE’s results are more robust because they are based on more reliable methods: paying subjects and transparency in editorial practices. We provided evidence suggesting that better reproducibility in EE is not the effect of better methods but rather reflects a tendency to standardize experimental protocols. Such standardization does not necessarily imply that EE is relatively more scientifically advanced than experimental psychology. In this regard, it might be interesting for further research to compare the state of standardization in EE and experimental psychology.
To read the working paper, click here.
Nicolas Vallois is an economist at the CRIISEA – Centre de recherche sur les institutions, l’industrie et les systèmes économiques d’Amiens, Université de Picardie Jules Verne. He can be contacted at nicolas.vallois@u-picardie.fr. Dorian Jullien is a postdoctoral fellow at CHOPE (Center for the History of Political Economy), Duke University and a research associate at the GREDEG (Groupe de Recherche en Droit, Economie et Gestion), Université Côte d’Azur. His email is dorian.jullien@gredeg.cnrs.fr.

You must be logged in to post a comment.