The Replication Network
Furthering the Practice of Replication in Economics
AoI*: “Reproduction and Replication at Scale” by Brodeur et al. (2024)
[*AoI = “Articles of Interest” is a feature of TRN where we report excerpts of recent research related to replication and research integrity.]
EXCERPTS (taken from the article)
“We are thrilled to announce that we are broadening our focus to new disciplines through a collaboration with Nature Human Behaviour. As part of this collaboration, we will be reproducing and replicating as many studies as possible of those that are published in Nature Human Behaviour (from 2023 and going forward), including in the fields of anthropology, epidemiology, economics, management, politics and psychology.”
“Furthermore, we will organize multiple replication games dedicated to reproducing and replicating articles in Nature Human Behaviour. All replication enthusiasts are invited to participate and will be granted co-authorship to a meta-paper that combines all reproductions and replications. The plan is for this meta-paper to then be considered for publication as a research article in Nature Human Behaviour (subject to peer review).”
“We are enthusiastic about this collaboration with Nature Human Behaviour and are actively looking for replicators. Please contact us by email at instituteforreplication@gmail.com if you would like to join our initiative!”
REFERENCES:
AoI*: “Promoting Reproducibility and Replicability in Political Science” by Brodeur et al. (2024)
[*AoI = “Articles of Interest” is a feature of TRN where we report abstracts of recent research related to replication and research integrity.]
ABSTRACT (taken from the article)
“This article reviews and summarizes current reproduction and replication practices in political science. We first provide definitions for reproducibility and replicability. We then review data availability policies for 28 leading political science journals and present the results from a survey of editors about their willingness to publish comments and replications. We discuss new initiatives that seek to promote and generate high[1]quality reproductions and replications. Finally, we make the case for standards and practices that may help increase data availability, reproducibility, and replicability in political science.”
REFERENCES:
AoI*: “Do Pre-Registration and Pre-Analysis Plans Reduce p-Hacking and Publication Bias? Evidence from 15,992 Test Statistics and Suggestions for Improvement” by Brodeur et al. (2023)
[*AoI = “Articles of Interest” is a feature of TRN where we report excerpts of recent research related to replication and research integrity.]
EXCERPTS (taken from the article)
“Pre-registration is regarded as an important contributor to research credibility. We investigate this by analyzing the pattern of test statistics from the universe of randomized controlled trials (RCT) studies published in 15 leading economics journals.”
“We draw two conclusions:”
“(a) Pre-registration frequently does not involve a pre-analysis plan (PAP), or sufficient detail to constrain meaningfully the actions and decisions of researchers after data is collected. Consistent with this, we find no evidence that pre-registration in itself reduces p-hacking and publication bias.”
“(b) When pre-registration is accompanied by a PAP we find evidence consistent with both reduced phacking and publication bias.”
“…we proceed with notions of pre-registration and PAPs as practiced in economics, or at least as operationalized by the largest and most influential professional association in the discipline, the AEA.”
“In their discussion relating to psychology, Nosek et al. (2018) contend that: “An effective solution is to define the research questions and analysis plan before observing the research outcomes – a process called preregistration,”which implies that pre-registration and the existence of a PAP are one and the same thing (see also Simmons et al. (2021) for a similar contention). This is far from how things work in economics, as we will show here.”
“We contend that many readers believe, wrongly according to our analysis, that pre-registration in itself implies enhanced research credibility, which would explain the weight apparently attached to whether a study is pre-registered or not in assessing its likely validity. Our finding is that credibility is enhanced only with inclusion of a PAP.”
REFERENCES:
Nosek, B. A., Ebersole, C. R., DeHaven, A. C. and Mellor, D. T.: 2018, The Preregistration Revolution, Proceedings of the National Academy of Sciences 115(11), 2600–2606.
REED: Doing Meta-Analyses with PCCs? Here’s Something You Might Not Know
[This blog first appeared at the MAER-Net Blog under the title “Something I Recently Learned About PCCs That Maybe You Also Didn’t Know”, see here]
While TRN is primarily dedicated to replications in economics, I also do research on meta-analysis. As such, I try to attend the Meta-Analysis in Economics Research Network (MAER-Net) Colloquium every year. It is a great place to learn from the best and have my many questions answered.
In 2022, the colloquium was held in Kyoto, Japan. That year I went with an especially large number of questions that I was hoping to have answered. In fact, I used my presentation at the colloquium as an opportunity to take my questions to the MAER-Net “brain trust”. Below is a slide from the presentation I gave in Kyoto:

Here is the background: My presentation was on “The Relationship Between Social Capital and Economic Growth: A Meta-Analysis.” Because measures of social capital and economic growth vary widely across studies, we transformed the estimates from the original studies into partial correlation coefficients (PCCs).
As is standard in economics, we used the following expression for the sampling variance of PCC:
1) s.e.(PCC)^2 = (1-PCC^2) / df
In the course of our analysis, one of the co-authors on this project, Robbie van Aert (Tilburg University) said we were using the wrong expression for the sampling variance of PCC. He said the correct expression was:
2) s.e.(PCC)^2 = (1-PCC^2)^2 / df
Notice the difference in the numerators.
This was pretty shocking to me, as I had published several meta-analyses with PCCs using Equation (1). As had many other economists.
Indeed, Robbie was right. Economists were using the wrong sampling variance! As a result of this experience, he published a note in Research Synthesis Methods (see below).

Unfortunately, I wasn’t able to get much of a response from those attending MAER-Net in Kyoto so I left confused about what I should do in my research.
However, the answer to my question was not long in coming. In March of this year I learned of an article by Tom Stanley and Chris Doucouliagos that addressed the issue of the “correct” sampling variance of PCC (see below).

To cut to the chase, the answer to my question if economists were using the wrong s.e.(PCC) is twofold:
1) Yes, economists are using the wrong sampling variance of PCC
2) Economists should continue using the wrong sampling variance because it produces better estimates
The reason why the “wrong” sampling variance is better than the “correct” sampling variance is enlightening. It raises issues about PCCs that I never appreciated. I thought if I was unaware of these issues, maybe others were too. Hence the motivation for this blog.
First, a reminder about why meta-analysis uses inverse variance weighting. Given heteroskedasticity, it is well known that weighted least squares (WLS) will produce estimates with least variance. Ceteris paribus, that argues in favor of using the “correct” sampling variance of PCC.
However, ceteris paribus doesn’t hold because the “correct” sampling variance of PCC is a function of PCC (see Equation 1).
In particular, as PCC increases, s.e.(PCC) decreases. As a result, inverse variance weighting favors larger values of PCC. This introduces bias in the estimation of the overall mean.
Doesn’t the “wrong” sampling variance also have a bias problem (cf. Equation 2)? Yes, it does. But the bias is not as bad.
Stanley and Doucouliagos demonstrate this in a series of simulations reported in their paper. In the table below, S1^2 is the “correct” sampling variance, and S2^2 is the “wrong” sampling variance commonly used by economists. In every case, bias is less using S2^2.

Does that mean that somehow WLS isn’t relevant for PCCs? Not at all. It is still the case that inverse weighting with the “correct” sampling variance produces estimates with smaller variance.
However, its advantage in variance is outweighed by its disadvantage in bias. As a result, inverse variance weighting using the “wrong” sampling variance is more efficient. This is demonstrated in the table where root mean squared error (RMSE) for S2^2 is smaller than for S1^2.
In summary, the “correct” sampling variance of PCC produces estimates with smaller variance. The “wrong” sampling variance produces estimates with smaller bias.
As Stanley and Doucouliagos show, the “wrong” sampling variance makes a better bias-variance trade-off and is thus more efficient. Accordingly, they recommend that economists continue to use the “wrong” sampling variance of PCC in inverse variance weighting.
Before reading Stanley and Doucouliagos’ article, I was unaware that inverse variance weighting with PCCs involved a bias-variance trade-off. Perhaps others were also unaware and will find this blog useful.
REFERENCES
Stanley, T. D., & Doucouliagos, H. (2023). Correct standard errors can bias meta‐analysis. Research Synthesis Methods, 14(3), 515-519.
van Aert, R. C., & Goos, C. (2023). A critical reflection on computing the sampling variance of the partial correlation coefficient. Research Synthesis Methods, 14(3), 520-525.
SIMCHI-LEVI: Behavioral Science’s Credibility Is At Risk. Replication Studies Can Help
NOTE: This blog is a repost of one originally published at the Informs blogsite (click here). We thank David Simchi-Levi for permission to repost.
Several scientific disciplines have been conducting replication initiatives to investigate the reliability of published research results. Replication studies are particularly important in social sciences for creating and advancing the state of knowledge. Transparency plans such as data disclosure policies and pre-registration have undoubtedly improved the standards for future studies. Replication studies help improve the level of confidence in previously-published results.
In “A Replication Study of Operations Management Experiments in Management Science” (Andrew M. Davis, Blair Flicker, Kyle Hyndman, Elena Katok, Samantha Keppler, Stephen Leider, Xiaoyang Long and Jordan D. Tong, Management Science), the authors investigate the replicability of a subset of laboratory experiments in operations management published in Management Science in 2020 and earlier to better understand the robustness, or limits, of the previously published results.
The research team, which included eight scholars from five research universities, carefully selected ten influential experimental papers in operations management based on survey-collected preferences of the operations management community more broadly. These papers covered six of the key OM topics: inventory management, supply chain contracts, queuing, forecasting, and sourcing. To control for subject-pool effects, the team conducted independent replications for each paper at two different research laboratories. The goal was to establish robust and reliable results with a statistical power of 90% at a 5% significance level.
The research team categorized replication outcomes based on p-values. When a paper’s primary hypothesis was replicated at both research sites, the team label the outcome as a “full” replication. A “partial” replication occurred when the primary hypothesis was replicated at one of the sites. And finally, when the primary hypothesis failed to replicate at either site, the authors label the outcome as a “no” replication.
Among the ten papers included in this study, six achieved full replication, two achieved partial replication, and two did not replicate. While it is encouraging to observe full replications, there is value in understanding why papers did not fully replicate. Non-replications provided interesting insights that contributed to our understanding of the research topics as well as methods.
An additional facet of the study was a survey conducted by the authors to collect predictions about the likelihood of replication of the results in papers in our study, from operations management researchers in general and specifically from OM researchers engaged in behavioral work. Interestingly, for both respondent groups, higher predictions of replication were positively associated with replication success; however, the team found that the researchers in the behavioral operations management field demonstrated more optimism about the likelihood of replication. However, overall prediction accuracy did not significantly differ between the behavioral and non-behavioral communities within operations.
This study has at least three important implications for the operations management community. First, it establishes a level of certainty about the validity, and in some cases limitations, of some of the most prominent laboratory experimental results in our field. Behavioral researchers, and those who draw on behavioral insights in analytical or empirical work, can leverage the study findings as a source of confidence about the results we tested.
Second, the study contributes interesting insights about the transferability of findings between the in-person and online data collection methods. Due to COVID-19, in some cases, the authors ran online versions of the original experiments and saw that in some cases they did indeed replicate despite the substantive differences. The COVID-19 pandemic more broadly caused an increase in online modes of data collection and remote interactions with participants, and therefore it became important to have findings that indicate when and why results can replicate across modalities and when they do not.
Third, the study initiates what we hope becomes a new norm in behavioral operations management for which this paper can serve as a foundation. We hope that similar operations management replication projects will become prevalent in the future. This should provide incentives for researchers to carefully document their methods in a way that will make it possible for others to replicate their results. Additionally, a stronger norm of independently conducted replications can help disincentivize researchers from engaging in fraud as well as identify existing fraudulent data.
There are several trade-offs that need to be considered in replication studies. There have now been several replication projects in psychology, economics, and operations. Each project has taken a different approach in terms of the paper selection method, author team size and structure, the number of sites per paper, and replication type.
Some projects adopt a mechanical approach, replicating papers from specific journals within a defined timeframe, while others, select a list of papers from various journals based on an open nomination process. The replication study in the Management Science paper employed a hybrid approach, combining mechanical and selective inclusion. This allowed the research team to create a representative list of papers while also incorporating community feedback.
Replicating more papers is desirable, but it comes with increased costs and coordination challenges. Projects that replicate a larger number of papers tend to have larger, decentralized teams. In contrast, the current project formed a centralized eight-author team to ensure process consistency and coordination. The team communicated regularly and made decisions jointly, leveraging the expertise of each team member. They also communicated with the authors of original papers throughout the replication process. For all selected papers, the original study authors shared their preferences about the hypotheses to study, shared and/or provided feedback on the materials used (software, instructions…) and the analysis, and were also given an opportunity to write responses to the replication reports.
Replication studies can choose to replicate each paper at one site or multiple sites. Replicating at multiple sites helps mitigate idiosyncratic differences among labs and provides a clearer understanding of the generalizability of results. Therefore, this research team conducted a replication study for each paper at two sites.
Replication studies can opt for either exact replications, following the original protocol, or close replications, introducing some material differences while documenting them explicitly. The choice of replication type depends on the goals of the study and the interpretation of the results. Although the initial intention of the research team was to conduct exact replications, this was not always possible. All deviations from original protocols, intentional as well as unintentional, are clearly documented.
In conclusion, this replication study in operations management provides valuable insights into the validity and transferability of experimental results. It enhances the confidence of researchers in the field and contributes to the ongoing replication movement. The research findings shed light on the intricacies of designing and conducting replication studies, addressing the trade-offs and compromises inherent in such endeavors.
We envision this study as a catalyst for future replication projects in operations management and related fields. By embracing replication and transparency, we can ensure the robustness and reliability of our research, ultimately advancing the knowledge and understanding of operations management principles and practices.
References
Andrew M. Davis, Blair Flicker, Kyle Hyndman, Elena Katok, Samantha Keppler, Stephen Leider, Xiaoyang Long and Jordan D. Tong, A Replication Study of Operations Management Experiments in Management Science. Management Science 2023 69:9, XX-XX.
For more perspective on this research, the E-i-C, David Simchi-Levi, asked two experts, Professor Colin F. Camerer (California Institute of Technology) and Professor Yan Chen (University of Michigan). Their comments are given below. Colin F. Camerer (California Institute of Technology)
—————————-
Title: Comment on “A Replication Study of Operations Management Experiments in Management Science”
camerer@caltech.edu
This comment cheerleads and historicizes the superb, action-packed paper by Davis et al (2023) replicating a carefully chosen selection of seminal behavioral operations experiments.
Almost twenty years ago, a series of seismic events began in experimental medical and social sciences, which led to a Replication Reboot in experimental social science that is still ongoing. It should continue until all the Rebooted open science practices are routine.
The first event was that Ioannidis (2005) promised to explain, as advertised in the hyperbolic title of his paper “Why Most Published Research Findings Are False”, referring to practices in medical trials.
In 2011 there were two more serious important events in experimental psychology: First, Bem (2011) published a paper in a highly-selective social psychology journal (JPSP) presenting evidence of “pre-cognitive” extrasensory perception. It was widely ridiculed—and the general claim was surely wrong (as some replication failures suggested). The JPSP defended their publication on the basis of being open-minded[1] and deferring to positive referee judgments. The Bem finding catalyzed concern that in some areas of experimental psychology, results that were “too cute to be true” were being published routinely. Many priming studies also failed to replicate around this time.
The second 2011 event was that Simmons et al (2011) demonstrated the idea of p-hacking—choosing specifications and subsamples iteratively until a preferred hypothesis appeared significant at a professionally-endorsed level (rigidly p<.05). (Leamer, 1978, also warned about the dangers of undisciplined “specification searches” in econometrics; his warning was often-cited but rarely followed.)
Simmons, and colleagues Simonsohn and Nelson, followed up their p-hacking bombshell with a series of papers clarifying their ideas and presenting tools (such as “p-curve”) to provide boundaries on how likely a set of studies might be exaggerated by p-hacking. By 2019 the term “p-hacking” was part of a question on the game show “Jeopardy!”.
A year later, in 2012, the research director at the Arnold Foundation, Stuart Buck, and the Arnolds themselves, became curious about whether policy evidence was really flimsy (based on highly-publicized replication failures of priming studies). Buck had seen writing from Brian Nosek about open science and he and the Arnolds communicated. The Arnold Foundation ended up investing $60 million in Open Science (see Buck 2013).
Shortly thereafter, the first multiple-study “meta-replications” appeared (Klein, 2014, a/k/a ManyLabs1; Open Science Collaboration, 2015 a/k/a RPP). The latter was the first output of the Open Science Foundation, created by Brian Nosek and Jeffrey Spies in 2013 and funded generously by the Arnold Foundation.
Those studies provided a sturdy foundation for how to do a set of replications and what can be learned. Then came two large-scale team efforts in replicating experimental economics, and then replicating general social science experiments published in high-impact Science and Nature (Camerer et al 2016, 2018). Our efforts followed the pioneering early ManyLabs and RPP work closely, except that we added prediction markets and surveys (following Dreber at al 2015). All of us are thrilled that these meta-replications have continued in different areas of experimental social science.
These historical facts help judge how quickly science—in this case, certain areas of experimental social science– is “self-correcting”. From the dramatic events of 2011 to the earliest meta-replications was only about four years. Generous private funding from the Arnold Foundation (people passionate about openness and quality of science) surely accelerated that timeline, perhaps by a factor of 2-3x.
Table 5 in this Davis et al (2023) article summarizing meta-replications shows that the first seven were not only conducted, but were published in a four-year span (2014-2018). That is amazingly fast (considering how much work goes into carefully documenting all aspects of the details and supplemental reporting, and the editorial grind). And it was done with no special centralized help from any professional organization, university, or federal funding agency. The moving forces were personal scientific contributions, Nosek and Spies creating OSF, quick writing of checks with many zeros by the Arnold Foundation, and emergence of nudges and funding from the Sloan Foundation (for Camerer et al studies, including Swedish grants to Anna Dreber and Magnus Johanneson) and then Simchi-Levi’s (2019) editorial.
About ten years later from the 2011 events, Andrew M. Davis, Blair Flicker—yes, I am spelling out all their names, not abbreviating– Kyle Hyndman, Elena Katok, Samantha Keppler, Stephen Leider, Xiaoyang Long, and Jordan D. Tong (2023) took up Simchi-Levi’s call to action. They carefully replicated ten experimental behavioral operations from studies published in Management Science.
Everyone involved deserves community thanks for putting in enormous amounts of work to produce evidence. This activity is less glamorous and career-promoting than regular kinds of innovative research. “Everyone” also includes peer scientists who made voted on which studies to replicate, and made judgments and replicability predictions in surveys. The collective effort would not be as persuasive and insightful without those peer contributions. The authors’ institutions also contributed money and resources. All this collective effort is trailblazing in extending similar meta-replication methods to a new domain. This effort also helps solidify best practices in a pipeline protocol many others can follow.
A cool feature of their approach is that peer scientists voted on which papers to replicate. The authors winnowed experimental papers down to 24, which around five in each of five substantive categories. Peer voting chose two from each category, for a total of 10 replications.
Basic results and one post-mortem
The basic results are simple to summarize: The quality of replicability varied but was generally high. A strong feature of their design is that each original finding was replicated twice, not once. Only two studies appeared to fail to replicate substantially in both replications. (Readers who aren’t interested in the nuanced details of this post-mortem should skip ahead to “Peer scientist replicability predictions are informative”.)
Let’s dig into details, as in a post-mortem, of one of the two apparent failures. It was an older paper by Ho[2] and Zhang (2008) about manufacturer-retail channel bargaining. It is well-known that linear pricing is inefficient because it doesn’t maximize total profit. Charging a fixed fee can fully restore efficiency (a/k/a “two-part tariff”). Ho and Zhang did the first experimental test of this theory. They were also curious about the behavioral hypothesis that retailers might encode paying a fixed fee (TPT) as a loss—if it is “mentally accounted” for as being decoupled from revenue—and balk at paying. However, if the fee is equivalently framed as a “quantity discount (QD)”, they wondered, that might reduce the loss-aversion. Their behavioral hypothesis was therefore that QD framing might be more empirically efficient than TPT.
As Ho and Zhang note in their Author Response (included in Davis et al’s supplementary material), four statistics go into the computation of overall efficiency. Three of the four statistics—wholesale and (conditional) retail prices, and the fixed fee—were strongly significantly different in the TPT and QD treatments in both the original study and the replication. Prices were lower and the fee was higher in QD. However, the difference in acceptance rates of the contracts, between the treatments, do go in opposite directions and efficiency does too.
A restriction which Davis et al used, as many others have (including our Camerer et al 2016, 2018 studies) is that only one hypothesis is tested. This is reasonable as otherwise it requires more complicated power calculations across multiple hypotheses. The efficiency prediction is what was singled out and it plainly did not replicate in magnitude or even direction. Davis et al and Ho and Zhang’s parallel discussions are in agreement about this.
A difference in protocol is that Ho and Zhang’s experiment was done on paper. Subjects had to make calculations by hand and their calculations were not checked. In the replication protocol, software was used, calculations were checked, and errors had to be corrected before subjects could proceed. The replication team noted that some subjects found this frustrating. The team also noted (as quoted in the Author Response):
“This calculation involves X + Y/(10-P) which is often not an integer. To do this calculation correctly also requires understanding order of operations, which to my great surprise it turns out that many people don’t understand. So some tried to calculate it as (X+Y)/(10-P). Even after calculating Price A correctly, they often ended up with a fraction and then had to multiply a fraction to calculate profit.”
The protocol difference and this comment make an important point: There will always be some unplanned deviations…always. The question is how well they might be anticipated and what they tell us.
This example reminds us that every experiment tests a joint hypothesis based on a long chain of behavioral elements. The chain is typically: Credibility of expected money or other reward; basic comprehension of the instructed rules; ability to make necessary calculations, whether explicitly (in the computer) or implicitly (on paper or in the brain); beliefs about what other subjects might do; a preference parameter such as the degree of loss-aversion (conditioned on a reference point); how feedback generates learning; and so on.
A good experimental design tries hard to create strong internal validity about design assumptions (such as payment credibility) and to allow thoughtful behavioral variation to identify behavioral parameters or treatment effects. (For example, Ho and Zhang recover estimates of a loss-aversion parameter, l=1.37 and 1.27 in TPT and QD.)
Sometimes “ability to make necessary calculations” is an element the experimenter wants to clamp and restrict to be true (e.g., providing a calculator) and other times it is an interesting source of behavioral variation. In this case, that “ability…” seems to have been sensitive to the experimental interface. This is a nuisance (unless, as in UI experiments, the nature of the interface is the subject of study—it wasn’t here).
This example is also a good opportunity to think about what scientists should do next in the face of a partially-failed replication. In a very few cases, a failure to replicate puts an idea or a group of scientists into a probationary period. For example, I do not think priming experiments such as many which replicated so poorly will ever recover.
In most cases, however, a partially-failed replication just means that a phenomenon is likely to be empirically sensitive to a wider range of variables than might be have been anticipated. This sensitivity should often spur more new investigation, not less.
In the case of nonlinear channel pricing, the empirical question is so interesting that mixed results of the original experiment and the replication should certainly provoke more research. As noted above, the core behavioral difference is the retailer acceptance rate of fixed-fee contracts under the TPT and QD frames. What variables cause this difference? Given these results, this question is even more interesting than before the replication results.
Why is behavioral operations replication so solid?
The general quality of replication effects is about as good as has been seen in any of the many meta-replications in somewhat different social sciences. In the replications of Davis et al and Ozer et al (ab) the replication effect sizes are smack on the original ones (as plotted in Figure 2). Other replication effect sizes are smaller than original effects, but that is the modal result. The relative effect size of replication compared to original data seems to generally be reliably around .60. Replicated effects usually go in the direction show originally, but are smaller. There is some great work to be done in figuring out exactly why this replication effect shrinkage is so regular.
In my experience looking across social sciences, replication is most precarious when a dependent variable and independent variable are measured (or experimentally manipulated) with error variance, and especially when the focus of theory is an interaction. In experimental economics, theory usually produces predictions about “main effects”.
Many of the behavioral operations are also about main effects— there is a single treatment variable and a plausible intuition about the direction of its effect, often competing with another intuition that there should be no effect at all. The “bullwhip effect” in supply chains is a great illustrative example. There is a clear concept of why no such effect should occur (normatively) and why it might and seems to (behaviorally). (This example is a great gift to behavioral economics—thanks, operations researchers!– because it spotlights a kind of behavioral consequence which seems to be special to operations but might be evident in other cases once the operations example is in mind.) There is a strong intuition that providing more information could make a difference, but is difficult to know without putting people in that situation and seeing what they do whether that’s true.
This formula is what made most of the earliest behavioral economics demonstrations so effective. Typically we were pitting one conventionally-believed convenient assumption—e.g., people discount exponentially, players in games are in equilibrium, people are selfish, people see through framing differences—against a plausible alternative.
Altmejd et al (2019) used LASSO methods to create a long list of features of both original studies and replication samples, to then predict from about 150 actual replications, what features of studies predicted replicability best (including prediction market forecasts). The LASSO “shrinks” features with weak predictive power to have zero coefficients (to limit false positives).
One of the important findings is that replication is less likely when the hypothesized effect is an interaction term rather than a main effect. Interactions are hard to detect when there is measurement error in both of two variables which are hypothesized to interact. Happily, behavioral operations seems to be in a start-up period in which main effects are still quite interesting. Interactions are part of human nature too, but identifying them requires larger high-quality samples and science which can confidently point to some plausible interactions and ignore others.
Publishing replications: Many >> 1
People often say that pure replication of a single previous study is not professionally rewarding (it can even make enemies) and is hard to publish. I think that’s generally true. Replicating one study raises a question that is difficult for the replicator to answer: Why did you choose this study to spend your time replicating? A single-study replication also cannot answer the most fundamental questions the profession would like to know about—such as “Does replicability failure casts possible fault on an author team or on a chosen topic that is hard to replicate?”
What we have learned in general science from the RPP and ManyLabs replications, and efforts like our own and this one in Management Science, is that meta-replicating a group of studies is a whole different enterprise. It is more useful and persuasive. It renders the question “Why replicate this particular study?” irrelevant and clearly answers the question “What does this tell us in general about studies on this topic?”. It is especially persuasive using the method the authors did here, which was to survey peer scientists about what they would most like to see replicated.
Furthermore, in our modern experience (post-2010) some funders—not necessarily all, but enough to supply enough resources—and many journals, are actually receptive to publishing these meta-replications. All sensible editors are open to publishing replication—they realize how important it is—but they would rather not have to adjudicate how to decide which of many one-study replications to publish. Editor Simchi-Levi’s editorial (2019) is an important demonstration of an active call from an editor of a prestigious journal.
Peer scientist replicability predictions are informative
In Davis et al (2023) peer scientist predictions of replicability were substantially correlated with actual predictability. There is also a small ingroup-optimism bias, in which peers most expert in behavioral operations predicted higher replication rates than non-experts, by about .08. However, both groups were about equally accurate when predictions are matched to actual replication outcomes. This is an important finding because it implies that in gathering accurate peer predictions, the peer group can be defined rather broadly. It does not have to be scientists closely expert with the style or scope of experiments.
Peer accuracy in predicting replicability raises a fundamental question about the nature of peer review and may suggest a simple improvement.
Suppose that referees are, to some extent, including guessed p(replication) as an input to their judgment of whether a paper should be published. And suppose there are observable features Xp of a refereed paper p—sample size, p-values, whether tested hypotheses are interactions, etc.—which both referees can easily see, and can also be seen in the post-refereeing process after papers are published.
Simple principles of rational forecasting imply that even if the features Xp are associated with replicability in the unconditional sample of papers reviewed, those features should not be associated with actually replicability of papers that are accepted, because referee selection will largely erase their predictive power.
Think of the simplest example of sample size N. Suppose a referee knows that there is a function p(replication|N) which is increasing in N. If she rejects papers with perceived low replicability, according to that function, then the set of accepted papers will not have replicability which is closely associated with N. The association was erased by referee selection.
However, it is a strong and reliable fact that actual replicability, based on observable characteristics of published papers, is somewhat predictable from peer judgments (surveys or more sophisticated prediction markets) and from simple observables like p-values and sample sizes. Altmejd et al (2019) found binary classification around 70% (where 50% is random and 100% is perfect). Most other studies, include Davis et al, also found a positive correlation between replication predictions and actual replication. In a working paper studying 36 PNAS experimental paper, Holtzmeister et al (in prep) find a very strong association between prediction-market predictions and actual replication. From 36 experiments published recently in PNAS, from the bottom 12 (judged as least likely to replicate by prediction markets), ten of 12 did not replicate at all.
There is no way around a hard truth here: In different fields, implicit referee and editorial decisions are choosing to publish studies for which replicability failures are substantially predictable, based on data the referees and editors had. The predictability increment is also not a small effect, it is substantial.
What can we do that is better? A few years ago, I proposed to a private foundation a pilot test where some submitted papers would be randomly “audited” by gathering peer predictions and then actually replicating the paper while it was being reviewed. The foundation liked the idea but was not willing to pay for a pilot unless we figured out who would pay for replications and investigator time if such a system were made permanent. We did not do the pilot. It is still worth a try.
What can we do better moving forward?
These results show that the quality of behavioral operations experiments, in terms of choice of theories, methods and sampling designed to create replicability, is solid. No area of social science has shown uniformly better replicability and some areas of psychology are clearly worse.
There is much to admire in Davis et al’s carefully-worded conclusion. I’ll mostly just quote and endorse some of their advice.
Suppose you are an active researcher, perhaps newer and not too burdened by old pre-Open Science bad habits. What should you be sure to do, to ensure your results are easy to replicate and likely to replicate?
Design for a generic subject pool. Whomever your starting subject pool is, somebody somewhere might want to replicate your experiment as exactly as possible, including written or oral instructions and user interface. It could be in a foreign country (so you want instructions to be faithfully translateable), with higher or lower literacy groups, with younger students or aging seniors, etc. You should want replication to be easy and to design for likely robustness.
I was taught by the great experimental economist Charlie Plott. Charlie obsessed over writing clear, plain instructions. For example, he avoided the term “probability”; instead, he would always describe a relative frequency of chance events that subjects could actually see. In many early experiments we also used his trick—a bingo cage of numbered balls which generated relative frequencies.
The simplicity of his instructions is now even more important as something to strive for, because online experiments, and the ability to do experiments in many countries and with people of many ages, requires the most culturally- and age-robust instructions.
Design for an online future: This advice is, of course, closely related to the above. Davis et al were harshly confronted with this because, during pandemic shutdown of many in-lab experiments they had to do a lot more online, even when the original experiments being replicated had not originally been online.
“Design for an open science future” is another desirable goal. In Camerer et al (2016) we had to entirely recreate software that was obsolete just to done study. The Davis et al replication project also created some de novo software.
Software degrades. If you create or use software for your experiments, the more customized, local, and poorly supported your software is, the more likely it will not be useable ___ years later (fill in the blank, 2, 3, 5).
Let’s end on a positive note. The Reproducibility Reboot is well underway, has been successful, and has been embraced by funders, journal editors, and energetic scientists willing to spend their valuable time on this enterprise. Korbmacher et al (2023) is a superb and thorough recent review. There is much to celebrate. We are like a patient going to the doctor, hoping for the best, but hearing that we need to put in more walking steps and eat healthier for or selves and our science to live longer. In five or twenty years, all of us will look back with some pride at the improvement in open science methods going on right now, of which this terrific behavioral operations project is an example.
[1] As the saying goes “Keep your minds open—but not so open that your brains fall out.”
[2] Disclosure: Teck-Hua Ho was a PhD student at Wharton when I was on the faculty there and we later wrote many papers together. Juan-juan Zhang was his advisee at Berkeley.
References
Altmejd A, Dreber A, Forsell E, Huber J, Imai T, et al. (2019) Predicting the replicability of social science lab experiments. PLOS ONE 14(12): e0225826. https://doi.org/10.1371/journal.pone.0225826
Buck, Stuart. Metascience since 2012: A personal history. https://forum.effectivealtruism.org/posts/zyrfPkX6apFoDCQsh/metascience-since-2012-a-personal-history
Camerer CF, Dreber A, Forsell E, Ho TH, Huber J, Johannesson M, Kirchler M, et al. (2016) Evaluating replicability of laboratory experiments in economics. Science 351(6280):1433–1436.
Camerer CF, Dreber A, Holzmeister F, Ho T-H, Huber J, Johannesson M, Kirchler M, et al. (2018) Evaluating the replicability of social science experiments in Nature and Science between 2010 and 2015. Nature Hum. Behav. 2:637–644.
Simchi-Levi D (2019) Management science: From the editor, January 2020. Management Sci. 66(1):1–4.
Dreber A, Pfeiffer T, Almenberg J, Isaksson S, Wilson B, Chen Y, Nosek BA, et al. (2015) Using prediction markets to estimate the reproducibility of scientific research. Nature 112(50):15343–15347.
Klein R, Ratliff K, Vianello M, Adams R Jr, Bahn´ık S, Bernstein M, Bocian K, et al. (2014) Data from investigating variation in replicability: A “many labs” replication project. J. Open Psych. Data 2(1):e4.
Korbmacher, M., Azevedo, F., Pennington, C.R. et al. The replication crisis has led to positive structural, procedural, and community changes. Commun Psychol 1, 3 (2023).
Leamer, Edward. 1978. Specification Searches: Ad Hoc Inference with Nonexperimental Data. Wiley
Open Science Collaboration (2015) Estimating the reproducibility of psychological science. Science 349(6251):aac4716.
Simmons, J.P.,Nelson,L.D.,& Simonsohn,U.(2011). False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science, 22, 1359–1366.
——————————————
Yan Chen (University of Michigan)
Title The Emerging Science of Replication
Background. Replications in the social and management sciences are essential for ensuring the reliability and progress of scientific knowledge. By replicating a study, researchers can assess whether the original results are consistent and trustworthy. This is crucial for building a robust body of knowledge. Furthermore, replications can help identify the conditions under which a phenomenon does or does not occur, thus honing theories and rendering them more precise and practical in real-world contexts. If a finding is consistently replicated, it becomes more likely to be accepted as a reliable part of the scientific understanding.
Over the past decade, the issue of empirical replicability in social science research has received a great deal of attention. Prominent examples include the Reproducibility Project: Psychology (Open Science Collaboration 2015), the Experimental Economics Replication Project (Camerer et al. 2016), and the Social Sciences Replication Project (Camerer et al. 2018). In particular, this discussion has focused on the degree of success in replicating laboratory experiments, the interpretation when a study fails to be replicated (Gilbert et al. 2016), the development of recommendations on how to approach a replication study (Shrout and Rodgers 2018), and best practices in replication (Chen et al. 2021).
This is an exciting time when the scientific community is converging on a set of principles for the emerging science of replication. Davis et al. (forthcoming) make significant contributions towards our shared understanding of these principles.
Summary. Davis et al. (forthcoming) present the first large-scale replication study in the area of operations management published in Management Science prior to 2020. Using a two-stage paper selection process including inputs from the research community, the authors identify ten prominent experimental operations management papers published in this journal. For each paper, they conduct high-powered (90% to detect the original effect size at the 5% significance level) replication study of the main results across at least two locations using original materials. Due to lab closures during the COVID-19 pandemic, this study also tests replicability in multiple modalities (in-person and online). Of these ten papers, six achieve full replication (at both sites), two achieve partial replication (at one site), and two do not replicate. In the discussion section, the authors share their insights on the tradeoffs and compromises in designing and implementing an ambitious replication study, which contribute to the emerging science of replication.
Comments. Compared to prior replication studies, this study has several distinct characteristics. First, this study contains independent replications across two locations, whereas the three prominent earlier replication studies contain one location for each original study (Open Science Collaboration 2015, Camerer et al. 2016, 2018). A multi-site replication helps determine whether a set of findings hold across diverse subject pools and cultural contexts, and enhance the robustness of the findings. Second, this study tests replicability in multiple modalities (in-person and online), whereas most of previous replication projects contain one modality. While replicating individual choice experiments online was unexpected due to the lab closure during the pandemic, it does teach us that it is important to “design for an online future.”
For researchers conducting lab and field experiments, in addition to design for an on- line future, we should “design for a generic subject pool.” How might researchers of original experiments design for a generic subject pool? In lab experiments, we could aim at collecting data from distinct subject pools. For example, in the classic centipede game experiment (McKelvey and Palfrey 1992), researchers recruited subjects from Caltech and Pasadena City College, two subject pools with different average analytical abilities. In a recent field experiment on a ride-sharing platform (Ye et al. 2022), researchers conducted the same field experiment across three cities of distinct size, competitiveness and culture. These multi-site design helps define the boundaries of each finding.
While this and previous replication studies use classical null hypothesis significance testing to evaluate replication results, we note that several studies have proposed that repli- cations take a Bayesian approach. Verhagen and Wagenmakers (2014) explore various Bayesian tests and demonstrate how previous studies and replications alter established knowledge through the Bayesian approach. When addressing how the field should con- sider failed replications, Earp and Trafimow (2015) consider the Bayesian approach and how failed replications affect the confidence of original findings.
McShane and Gal (2016) propose “a more holistic and integrative view of evidence that includes consideration of prior and related evidence, the type of problem being evaluated, the quality of the data, the effect size, and other considerations.” They warn that null hypothesis significance testing leads to dichotomous rather than continuous interpretations of evidence. Future replications might consider both the classical and Bayesian approaches to evaluate replication results.
References
Camerer, Colin F., Ann Dreber, Eskil Forsell, Teck-Hua Ho, Ju¨ rgen Huber, Magnus Johannesson, Michael Kirchler, Johan Almenberg, Adam Altmejd, Taizan Chan, Emma Heikensten, Felix Holzmeister, Taisuke Imai, Siri Isaksson, Gideon Nave, Thomas Pfeiffer, Michael Razen, and Hang Wu, “Evaluating replicability of laboratory experiments in economics,” Science, 2016, 351 (6280), 143–1436.
, Anna Dreber, Felix Holzmeister, Teck-Hua Ho, Jurgen Huber, Magnus Johannesson, Michael Kirchler, Gideon Nave, Brian A. Nosek, Thomas Pfeiffer, Adam Altmejd, Nick Buttrick, Taizan Chan, Yiling Chen, Eskil Forsell, Anup Gampa, Emma Heikensten, Lily Hummer, Taisuke Imai, Siri Isaksson, Dylan Manfredi, Julia Rose, Eric-Jan Wagenmakers, and Hang Wu, “Evaluating the replicability of social science experiments in Nature and Science between 2010 and 2015,” Nature Human Behaviour, 2018, 2, 637 – 644.
Chen, Roy, Yan Chen, and Yohanes E. Riyanto, “Best practices in replication: a case study of common information in coordination games,” Experimental Economics, 2021, 24, 2 – 30.
Davis, Andrew M., Blair Flicker, Kyle Hyndman, Elena Katok, Samantha Keppler, Stephen Leider, Xiaoyang Long, and Jordan D. Tong, “A Replication Study of Operations Management Experiments in Management Science,” Management Science, forthcoming.
Earp, Brian D. and David Trafimow, “Replication, falsification, and the crisis of confidence in social psychology,” Frontiers in Psychology, May 2015, 6 (621), 1–11.
Gilbert, Daniel T., Gary King, Stephen Pettigrew, and Timothy D. Wilson, “Comment on “Estimating the reproducibility of psychological science”,” Science, 2016, 351 (6277), 1037–1037.
McKelvey, Richard D. and Thomas R. Palfrey, “An Experimental Study of the Centipede Game,” Econometrica, 1992, 60 (4), 803–836.
McShane, Blakeley B. and David Gal, “Blinding Us to the Obvious? The Effect of Statistical Training on the Evaluation of Evidence”, Management Science, June 2016, 62 (6), 1707–1718.
Open Science Collaboration, “Estimating the reproducibility of psychological science,” Science, 2015, 349 (6251).
Shrout, Patrick E. and Joseph L. Rodgers, “Psychology, Science, and Knowledge Construction: Broadening Perspectives from the Replication Crisis,” Annual Review of Psychology, 2018, 69 (1), 487–510. PMID: 29300688.
Verhagen, Josine and Eric-Jan Wagenmakers, “Bayesian Tests to Quantify the Result of a Replication Attempt,” Journal of Experimental Psychology: General, August 2014, 143 (4), 1457–1475.
Ye, Teng, Wei Ai, Yan Chen, Qiaozhu Mei, Jieping Ye, and Lingyu Zhang, “Virtual teams in a gig economy,” Proceedings of the National Academy of Sciences, 2022, 119 (51), e2206580119.
AoI*: “High replicability of newly discovered social-behavioural findings is achievable” by Protzko et al. (2023)
[*AoI = “Articles of Interest” is a feature of TRN where we report abstracts of recent research related to replication and research integrity.]
ABSTRACT (taken from the article)
“Failures to replicate evidence of new discoveries have forced scientists to ask whether this unreliability is due to suboptimal implementation of methods or whether presumptively optimal methods are not, in fact, optimal. This paper reports an investigation by four coordinated laboratories of the prospective replicability of 16 novel experimental findings using rigour-enhancing practices: confirmatory tests, large sample sizes, preregistration and methodological transparency. In contrast to past systematic replication efforts that reported replication rates averaging 50%, replication attempts here produced the expected effects with significance testing (P < 0.05) in 86% of attempts, slightly exceeding the maximum expected replicability based on observed effect sizes and sample sizes. When one lab attempted to replicate an effect discovered by another lab, the effect size in the replications was 97% that in the original study. This high replication rate justifies confidence in rigour-enhancing methods to increase the replicability of new discoveries.”
AoI*: “The Significance of Data-Sharing Policy” by Azkarov et al. (2023)
[*AoI = “Articles of Interest” is a feature of TRN where we report abstracts of recent research related to replication and research integrity.]
ABSTRACT (taken from the article)
“We assess the impact of mandating data-sharing in economics journals on two dimensions of research credibility: statistical significance and excess statistical significance (ESS). ESS is a necessary condition for publication selection bias. Quasi-experimental difference-in-differences analysis of 20,121 estimates published in 24 general interest and leading field journals shows that data-sharing policies have reduced reported statistical significance and the associated t-values. The magnitude of this reduction is large and of practical significance. We also find suggestive evidence that mandatory data-sharing reduces ESS and hence decreases publication bias.”
VON HIPPEL: When Does Science Self-Correct? Lessons from a Replication Crisis in Early 20th Century Chemistry
NOTE: This blog is a repost of one originally published at The Good Science Project (click here)
Science is self-correcting—or so we are told. But in truth it can be very hard to expunge errors from the scientific record. In 2015, a massive effort showed that 60 percent of the findings published in top psychology journals could not be replicated. This was distressing news, but it led to several healthy reforms in experimental psychology, where a growing number of journals now insist that investigators state their hypotheses in advance, ensure that their sample size is adequate, and publish their data and code.
You might also imagine that the credibility of the non-replicable findings took a hit. But it didn’t—not really. In 2022—seven years after the poor replicability of many findings was revealed, the findings that had failed to replicate were still getting cited just as much as the findings that had replicated successfully. And when they were cited, the fact that they had failed to replicate was rarely mentioned.
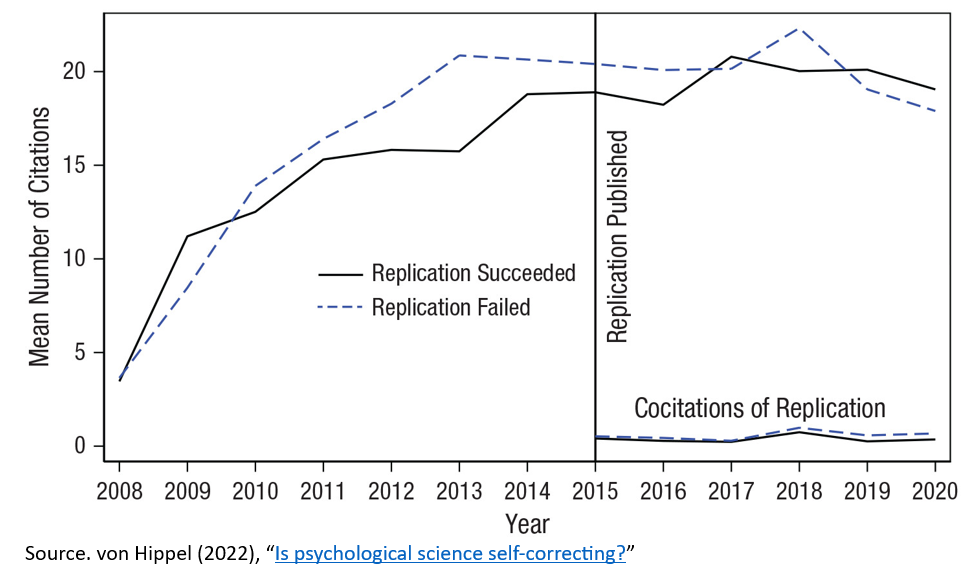
This pattern has been demonstrated several times in psychology and economics. Once a finding gains hinfluence, it continues to have influence even after it fails to replicate. The original finding keeps getting cited, and the replication study is all but ignored. The finding that replications don’t correct the record is unfortunately a finding that replicates pretty well.
Social scientists facing systemic problems in their home fields sometimes look longingly at their neighbors in the natural sciences. Natural scientists make mistakes too, and have even been known to falsify results, but if the mistakes and falsifications are consequential, they are often exposed and corrected in fairly short order.
One of the best-known examples is Fleischmann and Pons’ claim to have achieved “cold fusion” in 1989. Although the cold fusion episode is often viewed as an embarrassment in physics, it is actually a great example of a community correcting the scientific record quickly. Within 6 months of Fleischmann and Pons’ announcement, suspicious inconsistencies had been pointed out in their findings, and several other labs had reported failures to replicate. Finally, the Department of Energy announced that it would not support further work on cold fusion, and except for a handful of true believers the field turned its attention elsewhere.

I recently came across a similar episode from more than 100 years ago. The characters are of course different, but the first chapters are very much like those of the cold fusion episode. The later chapters, though, go in an unexpected direction, and show a Nobel laureate spending years pursuing nonreplicable results.
I’ll draw some lessons after I tell the story, which relies heavily on several books and articles, especially Dan Charles’ 2005 book Master Mind and Thomas Hager’s 2008 book The Alchemy of Air.
The Alchemy of Air
In an 1898 presidential address to the British Association for the Advancement of Science, the physicist William Crookes announced that humanity was approaching the brink of starvation. By 1930, he estimated, the world’s population would exceed the food supply that could be extracted from all the world’s arable land. Famine would inevitably follow. This being turn-of-the-century England, Crookes also suggested that famine would threaten the dominance of “the great Caucasian race,” since for some reason he believed that the supply of wheat on which “civilized mankind” depended would be more impacted that the supply of rice, corn, or millet that were more important to “other races, vastly superior to us in numbers, but differing widely in material and intellectual progress.”
Chemistry, Crookes argued, suggested a way to avoid that grim fate. Famine was only inevitable if the soil continued to produce crops at the rates that were typical at the end of the 19th century. But the soil could produce many more crops, and produce them more sustainably if it was enriched with massive amounts of fixed nitrogen. Natural nitrogen fertilizers, such as guano or saltpeter, were dwindling and might be gone by the 1930s. But 78 percent of air was nitrogen, even if it was not in a form that crops could use.
Crookes charged chemists with figuring out a way to “fix” the nitrogen in air—to react the N2 in the atmosphere with hydrogen from water vapor and produce the ammonia NH3 which was already known to be the key component of natural fertilizers. Solving the problem of making synthetic fertilizer would be a scientific triumph and a boon to humanity. The chemist who solved it would write their name in the history books. They would have shown how to make “bread from air.”
It did not escape notice that whatever chemist succeeded in making bread from air would become fabulously wealthy. And it did not escape notice that, in addition to making fertilizer, ammonia could be used to make explosives. The military applications of synthetic ammonia seemed especially important in Germany, which correctly anticipated that in the event of a war with Great Britain, the British navy could impose a blockade that would cut off Germany’s imports of both food and fertilizer.
Although the basic chemical reaction seemed straightforward, making it actually happen was not easy. It would require pressures and temperatures that had never been achieved in a laboratory. And it would require just the right catalyst.
In 1900, just two years after Crookes’ address, the German chemist Wilhelm Ostwald announced that he had synthesized ammonia. Ostwald was just the kind of person that other chemists imagined could make bread from air. He was nearly 50, well established, and widely regarded as one of the “fathers” of physical chemistry. He was already considered a strong candidate for a new prize funded by the estate of the recently deceased chemist Alfred Nobel. Synthesizing ammonia would make Ostwald a shoo-in. He applied for a patent and offered to sell his process for a million marks to the German company BASF.
There was only one problem. BASF couldn’t replicate Ostwald’s results. They put a junior chemist named Carl Bosch on the problem, but when he tried Ostwald’s process Bosch couldn’t produce a meaningful amount of ammonia. At best, the process would produce a couple of drops of ammonia and then stop. Which made no sense because the supply of nitrogen in the air was practically unlimited.
Bosch’s managers sent him back to the bench, and eventually he figured out what was going wrong. Ostwald had used iron as a catalyst, and the iron that Ostwald used, like the iron that Bosch used, was sometimes contaminated with a small amount of iron nitride. The nitrogen in the ammonia was coming from the iron nitride—not from the nitrogen in air. And since there was very little iron nitride, the process would never produce a meaningful amount of ammonia.
BASF wrote to Ostwald that they could not license his process after all. Ostwald withdrew his patent application, but he wasn’t exactly a gentleman about it. “When you entrust a task to a newly hired, inexperienced, know-nothing chemist,” Ostwald wrote, disparaging Bosch in a note to BASF managers, “then naturally nothing will come of it.”
But Bosch was right. No one at BASF could make Ostwald’s process work, and when they brought Ostwald in he couldn’t make it work either. He withdrew his patent application and the race to make bread from air continued.
Nine years, the problem of synthesizing ammonia was actually solved, but it was solved by a less obvious person. The person to show how to make bread from air was Fritz Haber, a 40-year-old chemist who worked at a respectable but not terribly prestigious university. Haber was Jewish and on nobody’s short list for the Nobel Prize.
Bosch was able to replicate Haber’s experiment, and spent the next few years scaling the process up. Bosch led a team of chemists and engineers who built large reaction chambers that could tolerate the required temperatures and pressures.
Meanwhile Ostwald sued BASF in collaboration with a rival company called Hoechst. Their claim was not that Haber’s process was invalid, but that it was not novel and its patents were invalid. If Ostwald and Hoechst had won, they would have been able to get into the ammonia business, too. But BASF won the suit, in part by bribing one of the key witnesses, an erstwhile rival of Haber’s named Walther Nernst. In 1913 BASF started running the world’s first ammonia synthesis factory, which produced a promising amount of ammonia in 1913 and 1914.
But in 1914 Germany entered World War One, Britain blockaded German ports, and all BASF’s ammonia was diverted from fertilizer to explosives, so that Germany could sustain its war effort even as its population starved. The repurposing of his life-giving work to deadly purposes upset Bosch so much that he went on a drinking binge.
Nevertheless, after the War, the spread of the Haber-Bosch process and related development led to massive increases in food production, which in the developing world are called the “Green Revolution.” It has been estimated that more than half the people now on earth simply would not be here if it weren’t for synthetic nitrogen fertilizers. Many of us owe our lives to them.
Why Did Chemistry Correct Chemists’ Errors?
The story so far is very much to the credit of turn-of-the-century chemistry. A senior chemist overreached and made a mistake, as everyone eventually does, but a junior chemist corrected him, and the path was cleared for one of chemistry’s greatest contributions to human thriving (and human misery).
But why did science self-correct so efficiently in this case? None of the characters in this story was a saint. Crookes was a racist (as were many English gentlemen at the time), and Ostwald could be a self-interested jerk. Haber and Bosch came off well in this story, but their later actions showed their dark side. Haber led Germany’s poison-gas program during and after World War One. Bosch eventually led IG Farben, the German chemical conglomerate that produced the Zyklon B gas used to kill Jews (including some of Haber’s relatives) in Nazi concentration camps. (Bosch’s personal feelings were anti-Nazi and anti-war, but that didn’t matter because he never took a stand.)
So if early twentieth-century chemists weren’t better human beings than modern psychologists and economists, why did they do a better job at rooting out nonreplicable results?
One reason, I think , was that chemistry had important practical uses. For modern social scientists, eminence is largely a social construction. It is measured by grants, publications, prizes, TED talks, appointments at prestigious universities. That was also true in early twentieth-century chemistry, but if it was done correctly, a breakthrough in chemistry would reach beyond one’s fellow chemists. It could lead to real, practical triumphs, like making bread from air.
And that’s why mistakes had to be corrected. BASF fully recognized that Ostwald would be annoyed by criticism of his work. But they couldn’t tiptoe around it, because they were trying to make ammonia from water and air. If Ostwald’s work couldn’t help them do that, then they couldn’t get into the fertilizer and explosives business. They couldn’t make bread from air. And they couldn’t pay Ostwald royalties. If the work wasn’t right, it was useless to everyone, including Ostwald.
That’s also the reason why the cold-fusion findings got corrected so quickly. If Fleischmann and Pons’ results were right, they could have led to an important new energy source. While it might have had unforeseen hazards, cold fusion would have made all other energy sources obsolete, solved global warming, and ended the need to buy oil from dangerous authoritarian countries. That’s why Fleischmann and Pons called a press conference, made the cover of the New York Times—and it’s why other scientists pounced on their result.
My friends in the natural sciences tell me that their fields do have some non-replicable results, but they’re typically in backwaters where only one lab has the necessary equipment and other labs aren’t particularly interested. If a finding looks to have practical applications, then nonreplicable results get exposed much more quickly.
Usually. But not always.
Fritz Haber’s Quest for Fool’s Gold
Two years after World War One, Haber and Bosch won the Nobel Prize and the Entente powers decided not to try Haber as a war criminal for his work on poison gas.
Now Fritz Haber began to look for other ways to serve his country. Germany’s new shortage was money. Under the Treaty of Versailles, Germany was charged with paying 132 billion gold marks in reparations—money it simply did not have. The burden brough hyperinflation and made it impossible for Germany to develop its economy and stabilize its experiment in democracy.
Haber started working on a potential solution: a chemical process that would extract gold from the sea. Ocean water contained trace quantities of gold, and Haber thought he could come up with an economical way to precipitate it out. It was an audacious plan, and if anyone else had suggested it, they might have been laughed at. But other scientists willingly joined Haber’s effort. After all, Haber was the scientist who had made bread from air.
Amazingly, Haber’s lab did come up with several ways to draw gold from sea water—and one of those methods would have been cost-effective if, as an 1878 article suggested, there were 65 micrograms of gold per liter of sea water. On the basis of that estimate, Haber’s financial backers built him a lab in an ocean liner, but once Haber got out to sea, in 1923, he found that the concentration of gold was more than 10,000 times lower than he expected. (Modern estimates suggest that the concentration is lower still.) The result that Haber had been relying on was non-replicable.
There are two lessons here. First, in early 20th century chemistry, as in 21st century psychology and economics, you could not trust everything you read in the scientific literature. Haber had believed published estimates of the gold in sea water, and he had paid dearly. Instead of spending years developing chemical processes that would only work if the published estimates were accurate, he should have started by confirming those estimates. Careful scientists take nothing for granted; they check everything themselves.
Second, no scientist is so eminent that he cannot make mistakes. Ostwald was the most eminent chemist in Germany when he let contamination fool him into thinking he had synthesized ammonia. Haber had become the most eminent chemist in Germany when he failed to check basic measurements of the gold in sea water.
Not only does eminence not guarantee accuracy, it can actually breed the hubris that leads to error. There are many examples of scientists who once did amazing work becoming sloppy, jumping to conclusions, or having so many people work for them that they can’t keep track of what’s going on in their own labs.
What Will It Take for the Social Sciences to Self-Correct?
What would it take for fields like economics and social psychology to self-correct as chemistry and physics (sometimes) do?
A crucial feature that leads a field to become self-correcting is the potential for important technological applications. As long as scientists are only writing articles, allegations of error may be difficult to resolve. But once a field has advanced to the point where it can claim to make bread from air, or draw gold from the sea, it more quickly becomes clear if the claim can hold water.
Now, work in psychology and economics sometimes aspires to offer practical benefits as well. Economists make recommendations regarding fiscal, labor, and educational policy, and the economists on the Federal Reserve Board control certain interest rates. Psychologists, for their part, offer advice and test interventions designed to change attitudes, improve mental health and academic achievement, and effect social change.
Of course, these economic and psychological interventions often fail to achieve their stated aims. But it’s always possible to explain those failures after the fact, often citing unpredictable contextual factors that worked against the intervention’s success.
And that highlights the second reason why the natural sciences are more self-correcting. Experiments in the natural sciences are closely controlled. A chemist cannot say that the success of a reaction depends on dozens of unspecified contextual factors, many of which cannot be foreseen. Instead, a chemist is expected to specify the exact temperature, pressure, and catalyst required to make a reaction occur. If another chemist cannot replicate the reaction at the same temperature and pressure, with the same catalyst, then somebody has made a mistake. It might be the original researcher; it might be the researcher conducting the replication. But there is a mistake somewhere, and somebody ought to figure it out. In a mature science, things don’t just happen for no particular reason.
In the social sciences, by contrast, scholars can be remarkably accepting of contradictory findings. In education research, for example, there are findings suggesting that achievement gaps between rich and poor children have been growing for 50 years—and other findings suggesting that they have barely changed. There are findings suggesting that achievement gaps grow faster during summer than during school—and other findings suggesting they don’t. Even results of randomized controlled trials often fail to replicate. This bothers me, but it doesn’t bother everyone, and many scholars either limit their attention to the results currently in front of them, or pick and choose from contradictory results according to which one best fits their general world view or policy preferences.
Of course, this state of affairs doesn’t provide a very firm foundation for real scientific progress. Both psychology and economics are starting to adopt practices which, when followed, produce findings that can more often be replicated across different labs and research teams. But a large number of questionable findings are still in the literature, and many of them are still getting cited at high rates. Many fields will continue to spin their wheels until they can tighten their focus to a small subset of replicable results, observed under controlled conditions, with major, practical applications in the real world.
REFERENCES
von Hippel, P. T. (2022). Is psychological science self-correcting? Citations before and after successful and failed replications. Perspectives on Psychological Science, 17(6), 1556-1565.

You must be logged in to post a comment.