NOTE: This is a long blog. TL;DR: I discuss 5 papers and the identification strategies each use in their effort to identify a causal effect of replications on citations.
One of the defining features of science is its ability to self-correct. This means that when new evidence or better explanations emerge, scientific theories and models are modified or even discarded. However, the question remains whether science really works this way. In this blog I review 5 recent papers that attempt to empirically answer this question. All five investigated whether there was a citation penalty from an unsuccessful replication. Although each of the papers utilized multiple approaches, I only report one or a small subset of results as representative of their analyses.
Three of the papers are published and from psychology: Serra-Garcia & Gneezy (2021), Schafmeister (2021), and von Hippel (2022). Two of the papers are from economics and are unpublished: Ankel-Peters, Fiala, & Neubauer (2023) and Coupé & Reed (2023).
All five find no evidence that psychology/economics are self-correcting. However, there are interesting things to learn in how they approached this question and that is what I want to cover in this blog.
The Psychology Studies
The three psychology studies rely heavily on replications from the Reproducibility Project: Psychology (Open Science Collaboration, 2015; henceforth RP:P). In particular, they exploit a unique feature of RP:P = RP:P “randomly” selected studies to replicate.
Specifically, they chose three leading journals in psychology. For each, they opened up to the first issue of 2008 and then selected experiments to replicate that met certain feasibility requirements. They did not choose experiments based on their results. RP:P was only concerned with selecting experiments whose methods could be reproduced with reasonable effort. They continued reading through the journals until they found 100 studies to replicate.
Because of RP:P’s procedure for selecting studies, one can view the outcome of their replications as random events since the decision to replicate an experiment was independent of expectations about whether the replication would be successful.
It is this feature that allows the three psychology studies to model the treatments “successful replication” and “unsuccessful replications” as random assignments. All three studies investigate whether “unsuccessful” replications adversely affect the original studies’ citations. I discuss each of them below.
Serra-Garcia & Gneezy (2021). Serra-Garcia & Gneezy draw replications from three sources, with the primary source being RP:P. The other two studies (“Economics”-Camerer et al., 2016; “Nature/Science”-Camerer et al., 2018) followed similar procedures in selecting experiments to replicate. Their main results are based on 80 replications and are presented in Figure 3 and Table 1 of their paper.
The vertical lines in the three panels of their Figure 3 indicate the year the respective replication results were published. The height of the lines represents the yearly citations for original studies that were successfully replicated (blue) and unsuccessfully replicated (black). If science were self-replicating, one would hope to see that citations for studies that failed to replicate would take a hit and decrease after the failure to replicate became known. Nothing of that sort is obvious from the graphs.

To obtain a quantitative estimate of the treatment effect (=”successful replication”), Serra-Garcia & Gneezy estimate the following specification:
Yit = β0i + β1Successit + β2AfterReplicationit + β3Success×AfterReplicationit + Year Fixed Effects + Control Variables
where:
Dependent variable = Google Scholar cites per year
Number of original studies = 80
Time period = 2010-2019
Estimation Method = Poisson/Random Effects
Control group = No
Their Table 1 reports the results of a difference-in-difference (DID) analysis (see below). The treatment variable is “Replicated x After publication of replication”. The estimated effect says that original studies that are successfully replicated receive approximately 1.2 more citations per year than those that are not. However, the effect is not statistically significant.

It is the random assignment of “successful replication” and “unsuccessful replication” that allow Serra-Garcia & Gneezy (2021) to claim they identify a causal effect. The other two psychology studies follow a similar identification strategy.
Schafmeister (2021). Schafmeister focuses solely on replication studies from RP:P. In particular, he selects 95 experiments that had a single replication and whose original studies produced statistically significant results.
He then constructs a control group of 329 articles taken from adjacent years (2007,2009) of the same three psychology journals used by RP:P. He uses the same criteria that RP:P used to select their replication studies except that these studies are used as controls. This allows him to define three treatments: “successful replication”, “unsuccessful replication”, and “no replication”. Because he uses the same criteria as RP:P in selecting his control group, he is able to claim that all three treatments are randomly assigned.
To obtain a quantitative estimate of the two treatment effects (=”successful replication” and “unsuccessful replication), Schafmeister estimates the following DID specification:
Yit = β0 + β1Successfulit + β2Failedit+ Study Fixed Effects + Year Fixed Effects + Control Variables
where “Successful” and “Failed” are binary variables that indicate that that the replication was successful/failed and that t > 2015, the year the replication result was published; and
Dependent variable = ln(Web of Science cites per year)
Number of original studies = 429 (95 RP:P + 329 controls)
Time period = 2010-2019
Estimation Method = OLS/Fixed Effects
Control group = Yes
Schafmeister’s Table 2 reports the results (see below). Focusing on the baseline results, studies that successfully replicate receive approximately 9% more citations per year (=0.037+0.051) than studies whose replications failed. Unfortunately, Schafmeister did not test whether this difference was statistically significant.

Von Hippel (2022). Similar to Schafmeister, von Hippel draws his replication entirely from RP:P, albeit with a slightly different sample of 98 studies. His Figure 2 provides a look at his main results. There is some evidence that successful replications gain citations relative to unsuccessful replications.
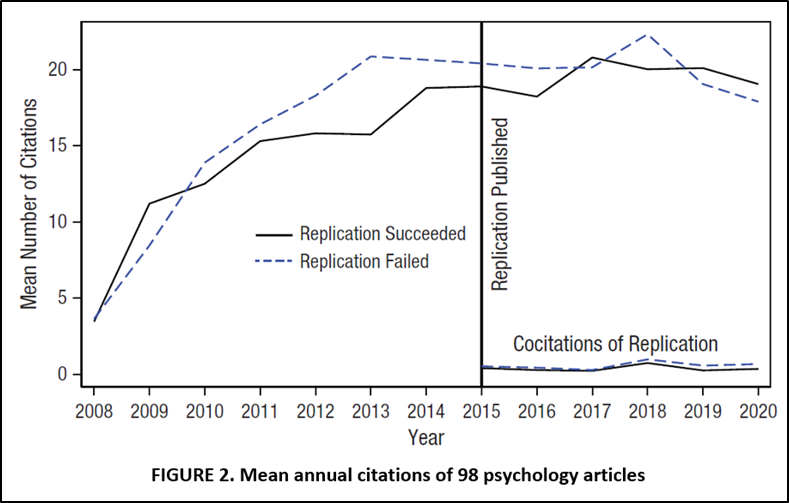
To obtain quantitative estimates of the treatment effect (“unsuccessful replication), von Hippel estimates the following DID specification:
Yit = β0 + β1AfterFailureit + Study Fixed Effects + Year Fixed Effects + Control Variables
where “AfterFailure” takes the value 1 if the original study failed to replicate and the year > 2015; and
Dependent variable = ln(Google Scholar cites per year)
Number of original studies = 95
Time period = 2008-2020
Estimation Method = Negative Binomial/Fixed Effects
Control group = No
He concludes that “replication failure reduced citations of the replicated studies by approximately 9%”, though the effect was not statistically significant.
In conclusion, all three psychology studies estimate that unsuccessful replication reduce citations, but the estimated effects are insignificant in two of the three studies and unreported in a third.
The Economics Studies
Once we get outside of psychology, the plot thickens. There is nothing of the scale of the RP:P to allow researchers to assume random assignment with respect to whether a replication is successful. Any investigation of whether economics is self-correcting must work with non-experimental, observational data. Two studies have attempted to do this.
Ankel-Peters, Fiala, & Neubauer (2023). Ankel-Peters, Fiala, & Neubauer focus on the flagship journal of the American Economic Association. They study all replications published as “Comments” that appeared in the American Economic Review (AER) from 2010-2020. Their AER sample comes with one big advantage and one big disadvantage.
The advantage lies in the fact that replications that appear in the AER are likely to be seen. A problem with replications that appear in lesser journals is that they may not have the visibility to affect citations. But that isn’t a problem for replications that appear in the AER. If ever one were to hope to see an adverse citation impact from an unsuccessful replication, one would expect to find it in the studies replicated in the AER.
The big disadvantage is that virtually all of the replications published by the AER are unsuccessful replications. This makes it impossible to compare the citation impact of unsuccessful replications with successful ones.
A second disadvantage is the relatively small number of studies in their sample. When Ankel-Peters, Fiala, & Neubauer try to examine citations for original studies that have at least 3 years of data before the replication was published and 3 years after, they are left with 38 studies.
Their main finding is represented by their FIGURE 6 below.

Ankel-Peters, Fiala, & Neubauer do not attempt to estimate the causal effect of an unsuccessful replication. Recognizing the difficulty of using their data to do that, they state, “…we do not strive for making a precise causal statement of how much a comment affects the [original paper’s] citation trend. The qualitative assessment of an absence of a strong effect is sufficient for our case” (page 15). That leaves us with Coupé & Reed (2023).
Coupé & Reed (2023). I note that one of the co-authors of this paper is Reed, who is also writing this blog. This raises the question of objectivity. Let the reader beware!
Unlike Ankel-Peters, Fiala, & Neubauer, Coupé & Reed attempt to produce a causal estimate of the effect of unsuccessful replications. Their approach relies on matching.
They begin with a set of 204 original studies that were replicated for which they have 3 years of data before the replication was published and 3 years of data after the replication was published. Approximately half of the replicated studies had their results refuted by their replications, with the remaining half receiving either a confirmation or a mixed conclusion.
They consider estimating the following DID specification:
Yit = β0 + β1Negativeit + Study Fixed Effects + Year Fixed Effects + Control Variables
Where Yit is Scopus citations per year and “Negative” takes the value 1 for an original study that failed to replicate and t > the year the replication was published. However, concern about the non-random assignment of treatment and the ability of control variables to adjust for this non-randomness causes them to reject this approach.
Instead, they pursue a two-stage matching approach. First, they use Scopus’ database and identify potential controls from all studies that were published in the same years as the replicated studies, appeared in the same set of journals that published the replicated studies, and belonged in the same general Scopus subject categories. This produced a pool of 112,000 potential control studies.
In the second stage, they matched these potential controls with the replicated studies on the basis of their year-by-year citation histories. Their matching strategy is illustrated in FIGURE 2.
If the original study was published 3 years before the replication study was published, they match on the intervening two years (Panel A). If the original study was published 4 years before the replication study was published, they match on the intervening 3 years (Panel B). And so on.

They don’t just match on the total number of citations in the pre-treatment period, but on the year-by-year history. The logic is that non-random assignment is better captured by finding other articles with identical citation histories than by adjusting regressions with control variables.
This gives them 3 sets of treateds and controls depending on the closeness of the match. For near perfect matches (“PCT=0%”), they have 74 replications and 7,044 controls. For two looser matching criteria (“PCT=10%” and “PCT=20%), they have 103 replications and 7,552 controls; and 142 replications and 11,202 controls, respectively.
For all original studies with a positive replication in a given year t, they define DiffPit = Ypit – Ypbarit, where Ypit is the associated citations for study i and YPbarit is the average of all the controls matched with study i. For all original studies i with a negative replication in a given year t, they define DiffNit = YNit – YNbarit, where YNit and YNbarit are defined analogously as above.
Coupé and Reed then pool these two sets of observations to get
Diffit = (Ypit – Ypbarit)×(1-Nit) + (YNit – YNbarit)×Nit = β0 + β1Negativeit
where Nit is a binary variable that takes the value 1 if the original study had a negative/failed replication.
They then estimate separate regressions for each year t = -3, -2, -1, 0, 1, 2, 3, where time is measured from the year the replication study was published.
β1 then provides an estimate of the difference in the citation effect from a negative replication compared to a positive or mixed replication. Their preferred results are based on quantile regression to address outliers and are reported in their Table 10 (see below).

They generally find a small, positive effect associated with negative replications of less than 2 citations/year. In all but one case (PCT=0%, t=2), the estimates are statistically insignificant. In no case do they find a negative and significant effect on citations and thus, they find no evidence of a citation penalty for failed replications.
Unlike psychology, any estimates of the causal effect of failed replications on citations in economics must deal with the problem of non-random treatment assignment. Reed and Coupé’s identification strategy relies on the fact that Ypbarit and YNbarit account for any unobserved characteristics associated with positive and negative replications, respectively. Since Ypbarit and YNbarit “predicted” the citation behaviour of the original studies before they were replicated, the assumption is that they represent an unbiased estimate of how many citations the respective original studies would have received if they had not been replicated. Under this assumption, β1 provides a causal estimate of the citation effect of a negative replication versus a positive one.
For psychology, the results are pretty convincing: a failed replication has a relatively small and statistically insignificant impact on a study’s citations.
In economics, the challenge is to find a way to address the problem that researchers do not randomly choose studies to replicate. Studies by Ankel-Peters, Fiala, & Neubauer (2023) and Reed & Coupé (2023) present two such approaches. Both studies fail to find any evidence of a citation penalty from unsuccessful replications. Whether one finds their results convincing depends on how well one thinks they address the problem of non-random assignment of treatment.
Bob Reed is Professor of Economics and the Director of UCMeta at the University of Canterbury. He can be contacted at bob.reed@canterbury.ac.nz, respectively.
REFERENCES
Ankel-Peters, J., Fiala, N., & Neubauer, F. (2023). Is economics self-correcting? Replications in the American Economic Review. Ruhr Economic Papers, #1005.
Coupé, T. & Reed, W.R. (2023). Do Replications Play a Self-Correcting Role in Economics? Mimeo, University of Canterbury.
Schafmeister, F. (2021). The effect of replications on citation patterns: Evidence from a large-scale reproducibility project. Psychological Science, 32(10), 1537-1548.
Serra-Garcia, M., & Gneezy, U. (2021). Nonreplicable publications are cited more than replicable ones. Science Advances, 7(21), eabd1705.
von Hippel, P. T. (2022). Is psychological science self-correcting? Citations before and after successful and failed replications. Perspectives on Psychological Science, 17(6), 1556-1565.

Pingback: Epidemiologists Correlate Male Alcohol Consumption To Birth Defects In Mice
Pingback: Refuted papers proceed to be cited greater than their failed replications: Can a brand new search engine be constructed that can repair this drawback? – Buku Baht
Pingback: Refuted papers proceed to be cited greater than their failed replications: Can a brand new search engine be constructed that can repair this downside? – huffworldpost.com
Pingback: Refuted papers continue to be cited more than failed replications. Can a new search engine be built to solve this problem? – Polynews.eu
Pingback: Refuted papers continue to be cited more than their failed replications: Can a new search engine be built that will fix this problem? – digixcity.com
Pingback: Should publishers flag replication failures in the same way they flag retractions? | Dynamic Ecology