LAKENS: Examining the Lack of a Meaningful Effect Using Equivalence Tests
When we perform a study, we would like to conclude there is an effect, when there is an effect. But it is just as important to be able to conclude there is no effect, when there is no effect. So how can we conclude there is no effect? Traditional null-significance hypothesis tests won’t be of any help here. If you observe a p > 0.05, concluding that there is no effect is a common erroneous interpretation of p-values.
One solution is equivalence testing. In an equivalence test, you statistically test whether the observed effect is smaller than anything you care about. One commonly used approach is the two-one-sided test (TOST) procedure (Schuirmann, 1987). Instead of rejecting the null-hypothesis that the true effect size is zero, as we traditionally do in a statistical test, the null-hypothesis in the TOST procedure is that there is an effect.
For example, when examining a correlation, we might want to reject an effect as large, or larger, than a medium effect in either direction (r = 0.3 or r = -0.3). In the two-sided test approach, you would test whether the observed correlation is significantly smaller than r = 0.3, and test whether the observed correlation is significantly larger than r = -0.3. If both these tests are statistically significant (or, because these are one-sided tests, when the 90% confidence interval around our correlation does not include the equivalence bounds of -0.3 and 0.3) we can conclude the effect is ‘statistically equivalent’. Even if the effect is not exactly 0, we can reject the hypothesis that the true effect is large enough to care about.
Setting the equivalence bounds requires that you take a moment to think about which effect size you expect, and which effect sizes you would still consider support for your theory, or which effects are large enough to matter in practice. Specifying the effect you expect, or the smallest effect size you are still interested in, is good scientific practice, as it makes your hypothesis falsifiable. If you don’t specify a smallest effect size that is still interesting, it is impossible to falsify your hypothesis (if only because there are not enough people in the world to examine effects of r = 0.0000001).
Furthermore, when you specify which effects are too small to matter, it is possible to find an effect is both significantly different from zero, and significantly smaller than anything you care about. In other words, the finding lacks ‘practical significance’, solving another common problem with overreliance on traditional significance tests. You don’t have to determine the equivalence bounds for every other researcher – you can specify which effect sizes you would still find worthwhile to examine, perhaps based on the resources (e.g., the number of participants) you have available.
You can use equivalence tests in addition to null-hypothesis significance tests. This means there are now four possible outcomes of your data analysis, and these four cases are illustrated in the figure below (adapted from Lakens, 2017). A mean difference of Cohen’s d = 0.5 (either positive or negative) is specified as a smallest effect size of interest in an independent t-test (see the vertical dashed lines at -0.5 and 0.5). Data is collected, and one of four possible outcomes is observed (squares are the observed effect size, thick lines the 90% CI, and thin lines the 95% CI).
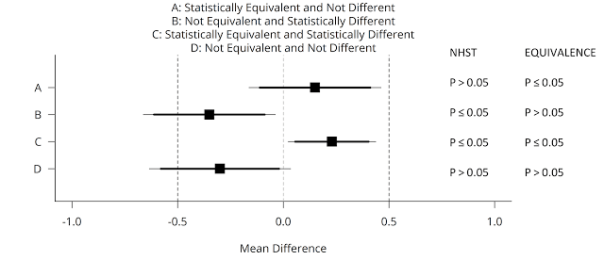
We can conclude statistical equivalence if we find the pattern indicated by A: The p-value from the traditional NHST is not significant (p > 0.05), and the p-value for the equivalence test is significant (p ≤ 0.05). However, if the p-value for the equivalence test is also > 0.05, the outcome matches pattern D, and we can not reject an effect of 0, nor an effect that is large enough to care about. We thus remain undecided. Using equivalence tests, we can also observe pattern C: An effect is statistically significant, but also smaller than anything we care about, or equivalent to null (indicating the effect lacks practical significance). We can also conclude the effect is significant, and that the possibility that the effect is large enough to matter can not be rejected, under pattern B, which means we can reject the null, and the effect might be large enough to care about.
Testing for equivalence is just as simple as performing the normal statistical tests you already use today. You don’t have to learn any new statistical theory. Given how easy it is to use equivalence tests, and how much they improve your statistical inferences, it is surprising how little they are used, but I’m confident that will change in the future.
To make equivalence tests for t-tests (one-sample, independent, and dependent), correlations, and meta-analyses more accessible, I’ve created an easy to use spreadsheet, and an R package (‘TOSTER’, available from CRAN), and incorporated equivalence test as a module in the free software jamovi. Using these spreadsheets, you can perform equivalence tests either by setting the equivalence bound to an effect size (e.g., d = 0.5, or r = 0.3) or to raw bounds (e.g., a mean difference of 200 seconds). Extending your statistical toolkit with equivalence tests is an easy way to improve your statistical and theoretical inferences.
Daniël Lakens is an Assistant Professor in Applied Cognitive Psychology at the Eindhoven University of Technology in the Netherlands. He blogs at The 20% Statistician and can be contacted at D.Lakens@tue.nl.
REFERENCES
Lakens, D. (2017). Equivalence tests: A practical primer for t-tests, correlations, and meta-analyses. Social Psychological and Personality Science. DOI: 10.1177/1948550617697177 https://osf.io/preprints/psyarxiv/97gpc/
Schuirmann, Donald J. (1987). A comparison of the two one-sided tests procedure and the power approach for assessing the equivalence of average bioavailability. Journal of Pharmacokinetics and Pharmacodynamics 15(6): 657-680.

You must be logged in to post a comment.