Do You Use Clustered Standard Errors? You Should Read This
[From the working paper, “How Cluster-Robust Inference Is Changing Applied Econometrics” by James MacKinnon, posted as a Queen’s University Working Paper]
“Whenever the observations can plausibly be grouped into a set of clusters, it has become customary, indeed often mandatory, in many areas of applied econometrics to use clustered standard errors….Nevertheless, whether and how to account for clustered disturbances is still somewhat controversial.”
“I am making the (arguably very strong) assumptions that each observation belongs to one and only one cluster, that the investigator knows which cluster it belongs to, and that any correlation across observations occurs only within clusters.”
“For simplicity and concreteness, consider the linear regression model where y and u are Nx1 vectors of observations and disturbances, X is an NxK matrix of exogenous covariates, and β is a Kx1 parameter vector. With one-way clustering, which is currently the most common case, there are G clusters, indexed by g, where the gth cluster has Ng observations.”
where y and u are Nx1 vectors of observations and disturbances, X is an NxK matrix of exogenous covariates, and β is a Kx1 parameter vector. With one-way clustering, which is currently the most common case, there are G clusters, indexed by g, where the gth cluster has Ng observations.”
“This yields a cluster-robust variance estimator, or CRVE, of which the most widely-used version is
“CV1 can have rank at most G-1. This makes it impossible to test hypotheses involving more than G-1 restrictions using Wald tests based on (4). Moreover, for hypotheses that involve numbers of restrictions not much smaller than G-1, the finite-sample properties of Wald tests based on (4) are likely to be very poor.”
“Allowing the disturbances to be correlated fundamentally changes the nature of statistical inference, especially for large samples. This is most easily seen in the context of estimating a population mean. Suppose we have a sample of N uncorrelated observations, yi, each with variance Var(yi) that is bounded from below and above. Then the usual formula for the variance of the sample mean [ybar] is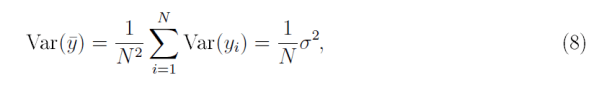
“From (8) it is easy to see that Var(ybar)→0 as N→∞. But this result depends crucially on the assumption that the yi are uncorrelated.”
“Without such an assumption, the variance of the sample mean would be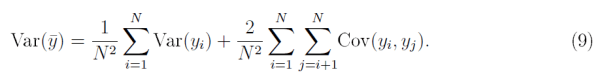
“…even if the Cov(yi;yj) are very small, the variance of ybar will never converge to zero as N→∞. Instead, it will ultimately converge to whatever the second term converges to.”
“…inference with clustered disturbances can be very different from inference with uncorrelated ones. When G is fixed, or increases less rapidly than N, the information contained in a sample grows more slowly than the sample size…. This implies that the amount of information about the parameters of interest contained in extremely large samples (such as the ones increasingly encountered in empirical microeconomics) may be very much less than intuition would suggest.”
“Much of the work on cluster-robust inference in recent years has focused on inference in finite samples. The meaning of finite is not the usual one, however. What matters for reliable inference is not the number of observations, N, but the number of clusters, G. In addition, both the way in which observations are distributed across clusters and the characteristics of the Xg matrices can greatly affect the reliability of finite-sample inference.”
“Suppose we are interested in one element of β, say βj . Then cluster-robust inference is typically based on the t statistic where βj0 is the value under the null hypothesis, and [Vhatjj] is the jth diagonal element of the CV1 matrix (4). The statistic tj is generally assumed to follow the Student’s t distribution with G-1 degrees of freedom.”
where βj0 is the value under the null hypothesis, and [Vhatjj] is the jth diagonal element of the CV1 matrix (4). The statistic tj is generally assumed to follow the Student’s t distribution with G-1 degrees of freedom.”
“Inference based on (11) and the t(G-1) distribution can sometimes work very well. It generally does so when there are at least 50 clusters and they are reasonably homogeneous, that is, similar in size and with reasonably similar Xg‘Xg and Xg‘ΩgXg matrices. However, there can be severe over-rejection when these conditions are not satisfied.”
“In most cases, the best way to perform tests of restrictions on the linear regression model (1) seems to be to use a particular version of the wild bootstrap. We first compute either a t statistic like tj or a Wald statistic … then compute a large number of bootstrap test statistics, and finally calculate a bootstrap P value that measures how extreme the actual test statistic is relative to the distribution of the bootstrap test statistics. For example, if 26 out of 999 bootstrap statistics were more extreme than the actual test statistic, the bootstrap P value would be 27/999 = 0.027.”
“The key issue for bootstrap testing is how to generate the bootstrap samples. In the case of (1), there are several plausible ways to do so. The best approach usually seems to be to use the restricted wild cluster bootstrap (WCR).”
“Provided the number of clusters is not too large, it is possible to generate a large number of wild cluster bootstrap test statistics very efficiently. This is what the Stata routine boottest does… Because using boottest is so inexpensive in most cases, it probably makes sense to employ the restricted wild cluster bootstrap by default whenever making cluster-robust inferences using Stata.”
“Reliable inference is particularly challenging when the parameter of interest is the coefficient on a treatment dummy variable, treatment is assigned at the cluster level, and there are very few treated clusters. This includes the case of difference-in-differences (DiD) regressions when all the treated observations belong to just a few clusters. It has been known for some time that using cluster-robust t statistics leads to serious over-rejection in such cases.”
[There is a] “…large and rapidly growing literature aimed at improving cluster robust inference in finite samples. A wide variety of methods is available, and it would often make sense to employ two or three of them. In many cases, but not all, the restricted wild cluster bootstrap works very well. Perhaps surprisingly, it can often be computed remarkably quickly using the Stata routine boottest.”
“As the empirical examples ,,, illustrate, inference can be very sensitive to how (and whether) the observations are clustered. In practice, investigators would therefore be wise to put a lot of thought into this. When there is more than one natural way to cluster, it generally makes sense to investigate all of them.”

You must be logged in to post a comment.