Systematic Reviews: The Machines Cometh
[Excerpts taken from the article, “Developing a fully automated evidence synthesis” by John Brassey et al., published in BMJ Evidence-Based Medicine]
“Here, we describe a fully automated evidence synthesis system for intervention studies, one that identifies all the relevant evidence, assesses the evidence for reliability and collates it to estimate the relative effectiveness of an intervention. Techniques used include machine learning, natural language processing and rule-based systems…The idea was to explore how far the current technologies could go to help develop a fully automated form of evidence synthesis.”
“Cochrane, a prominent SR producer, reports: ‘Each systematic review addresses a clearly formulated question; for example: Can antibiotics help in alleviating the symptoms of a sore throat? All the existing primary research on a topic that meets certain criteria is searched for and collated, and then assessed using stringent guidelines, to establish whether or not there is conclusive evidence about a specific treatment.’”
“From the above, for a given clinical question, we can extract the following questions that would need answering in a successful system: 1. Can all the evidence be identified? 2. Can this evidence be assessed? 3. Can it be collated to establish if there is conclusive evidence? These were the core tasks of this project.”
“…we used the concept of PICO, an acronym, which highlights what the population, intervention, comparison and outcomes are. For this step, we only required the PIC elements….The aim of the PIC identification is to automatically extract the population (eg, men with asthma), the intervention (eg, treated with vitamin C) and its comparison (eg, receiving placebo)…”
“…we exploited commonly occurring linguistic patterns. For example, consider the sentence: The bioavailability of nasogastric versus trovafloxacin in healthy subjects. In this sentence, a possible pattern is ‘[…] of […] vs […] in […]’; in which the preposition ‘of’ indicates the start of the Intervention, ‘vs’ separates the Intervention from the Comparison and finally, ‘in’ indicates the start of the population.”
“Since the text patterns of RCTs are variable, it was necessary to identify multiple patterns that cover the most common cases. To create ground truth data for this task, we employed six human annotators (two linguists and four people from the medical domain) and asked them to manually label the PIC elements in the title and the abstract of 1750 RCTs.”
“After manual labelling, we used 80% of the labelled RCTs (training set) to derive the most frequently occurring patterns for PIC identification. Afterwards, we created an algorithm that checked if an input sentence conforms to one of the identified patterns; if so, the PIC information was extracted. An overview of the process is given in figure 1.”

“ASSESSING THE EVIDENCE: This involved multiple steps and techniques:”
– “Sentiment analysis—this allowed us to understand if the intervention had a positive or negative impact in the population studied.”
– “Risk of bias (RoB) assessment—to indicate if a trial was likely to be biassed or not.”
– “Sample size calculations—understanding how big the trial was, an indication of how reliable the results are likely to be.”
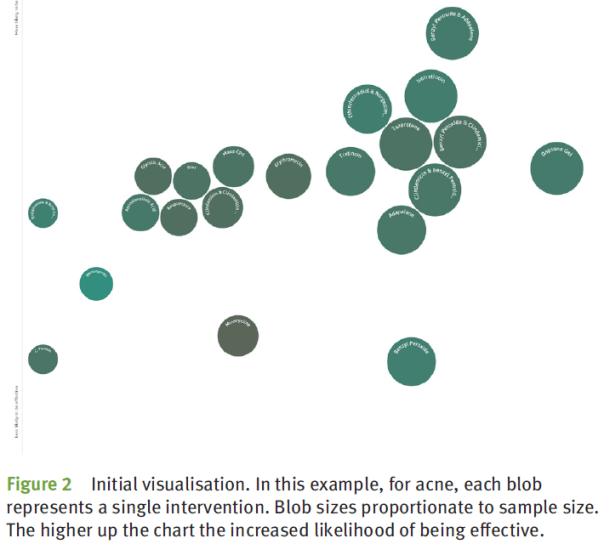
“…the results are displayed with the overall effectiveness on the y-axis. Each ‘blob’ corresponds to an evidence group, where the size of the blob represents the sample size while the shading reflects the overall RoB, see figure 2.”
“To the best of our knowledge, this is the first publicly available system to automatically undertake evidence synthesis…As the system is fully automatic, it means that all RCTs and SRs are included in the syntheses meaning that all conditions and interventions are covered and, given the nature of the system, as new RCTs and SRs are published they are automatically added to the system ensuring it is always up to date.”
“The method described is much akin to vote counting, whereby the number of positive and negative studies are counted. However, the technique we used has overcome one major criticism of vote counting in that we take into account sample size of the trials and adjust the impact accordingly. In other words, a small trial is not counted as equal to a large trial. Similarly, with our ability to assess the RoB for a given RCT and SR, we are able to ensure that trials with higher risks of bias carry less weight than unbiased trials.”
“This autosynthesis project is very much in the development and is released as a ‘proof of concept’.”
To read the article, click here.

You must be logged in to post a comment.