COUPÉ: Are Replications Worth it?
Does it make sense for an academic to put effort in replicating another study? While reading a paper in Political Analysis (Katz, 2001[1]) in 2005, I noticed a strange thing. In that paper, the author uses simulations to check how biased estimates are if one estimates fixed effects in a logit model by including fixed effects dummies rather than doing conditional logit.
However, the way the author described the fixed effects in the paper suggested that he assumed all fixed effects were equal. This, in fact, means there are no fixed effects, as equal fixed effects are just like a constant term. The author’s Stata code confirmed he indeed generated a ‘true’ model without fixed effects and hence the article’s interpretation was different from what it was actually doing. I fixed the code, re-ran the simulation and wrote up a correction which was also published in Political Analysis (Coupé, 2005[2]). The author in his reply admitted the issue (Katz, 2005[3]).
These two articles, Katz (2001) and Coupé (2005) thus provide a clean experiment to assess how a successful replication affects citations of both the replication and the original paper. Both papers were published in the same journal. Katz’s reply (Katz, 2005) shows the author of the original paper agrees with the flaw in the analysis of Katz (2001) so there is no uncertainty about whether the replication or the original is incorrect. And the flaw is at the core of the analysis in Katz (2001). In most replications, only parts of the analyses are shown to be incorrect or not replicable so subsequent citations might refer to the ‘good’ parts of the paper.
I used Google search to find citations of Katz (2001) and Coupé (2005) and then eliminated the citations coming from multiple versions of the same papers. The table below gives the results.
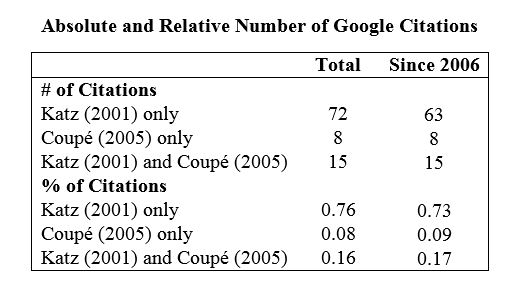
The table shows that even after publication of the correction, more than 70% of citing papers only cite the Katz study. This remains true even if one restricts the sample to citations from more than 5 years after the publication of the correction.
I also investigated how those papers that cite both Katz (2001) and Coupé (2005) cite these papers. I could find the complete text for 13 out of 15 such papers. None indicates the issue with the Katz (2001) study, instead both studies are used as examples of studies that find one can include fixed effects dummies in a logit regression if the number of observations per individual is sufficiently big. While both studies indeed come to that conclusion, the Katz (2001) study could not make that claim based on the analysis it did. This suggest that even those people who at least knew about the Coupé (2005) article also did not really care about this fact.
While the fact that many people continue to cite research that has been shown to be seriously flawed is possibly disappointing, this should not come as a surprise. Retraction Watch (2015) has a league table of citations given to papers after they have been retracted.
Further, my experience is consistent with the results of Hubbard and Armstrong (1994). They find that “Published replications do not attract as many citations after publication as do the original studies, even when the results fail to support the original studies.” In other words, even after the replication has been published, the original article continues to be cited more frequently than the replication. This is true even when the results from the original study were overturned by the replication.
Citations are only one measure of “worth.” But my experience, and the evidence from Hubbard and Armstrong (1994), suggest that replicated research is not valued as highly by the discipline as original research. Which may be one reason why so little replication research is done.
REFERENCES
Coupé, T. (2005). Bias in conditional and unconditional fixed effects logit estimation: A correction. Political Analysis, Vol. 13: 292-295.
Hubbard, R. and Armstrong, J.S. (1994). Replications and extensions in marketing – rarely published but quite contrary. International Journal of Research in Marketing, Vol. 11: 233-248.
Katz, E. (2001). Bias in conditional and unconditional fixed effects logit estimation. Political Analysis, Vol. 9: 379-384.
Katz, E. (2001). Response to Coupé. Political Analysis, Vol. 13: 296-296.
Tom Coupé is an Associate Professor of Economics at the University of Canterbury, New Zealand.
[1] Abstract of Katz (2001): “Fixed-effects logit models can be useful in panel data analysis, when N units have been observed for T time periods. There are two main estimators for such models: unconditional maximum likelihood and conditional maximum likelihood. Judged on asymptotic properties, the conditional estimator is superior. However, the unconditional estimator holds several practical advantages, and therefore I sought to determine whether its use could be justified on the basis of finite-sample properties. In a series of Monte Carlo experiments for T < 20, I found a negligible amount of bias in both estimators when T ≥ 16, suggesting that a researcher can safely use either estimator under such conditions. When T < 16, the conditional estimator continued to have a very small amount of bias, but the unconditional estimator developed more bias as T decreased.”
[2] Abstract of Coupe (2005). “In a recent paper published in this journal, Katz (2001) compares the bias in conditional and unconditional fixed effects logit estimation using Monte Carlo Simulation. This note shows that while Katz’s (2001) specification has ‘‘wrong’’ fixed effects (in the sense that the fixed effects are the same for all individuals), his conclusions still hold if I correct his specification (so that the fixed effects do differ over individuals). This note also illustrates the danger, when using logit, of including dummies when no fixed effects are present”.
[3] Katz’ (2005) reply. “I agree with the author’s main point. Although I tried to fit a fixed-effects model to the simulated data, those data were generated from a model without fixed effects. In my experiment, therefore, use of the unconditional estimator was perfectly confounded with misspecification of the model. I thank the author for catching this flaw.”

very interesting. It would be nice to run a more systematic review, beyond “my papers do not get as many citations as they should” 🙂 It would probably be publishable
LikeLiked by 1 person
Very interesting, and consistent with my own experience. Just to be pedantic, could I ask you to convert your figures in your table to percentages (or label as proportions)?
LikeLiked by 1 person
Pingback: Weekend reads: One of the most highly cited papers ever; a pharma buys peer-reviewed praise; how to get more citations - Retraction Watch at Retraction Watch