REED: Why Lowering Alpha to 0.005 is Unlikely to Help
A standard research scenario is the following: A researcher is interested in knowing whether there is a relationship between two variables, x and y. She estimates the model y = μ0 + μ1 x + ε, ε ~ N(0,σ2). She then tests H0: μ1 = 0 and concludes that a relationship exists if the associated p-value is less than 0.05.
Recently, a large number of prominent researchers have called for journals to lower the threshold level of statistical significance from 0.05 to 0.005 (Benjamin et al., 2017; henceforth B72 – for its 72 authors!). They give two main arguments for doing so. First, an α value of 0.005 corresponds to Bayes Factor values that they judge to be more appropriate. Second, it would reduce the occurrence of false positives, making it more likely that significant estimates in the literature represent real results. Here is the argument in their own words:
“The choice of any particular threshold is arbitrary and involves a trade-off between Type I and II errors. We propose 0.005 for two reasons. First, a two-sided P-value of 0.005 corresponds to Bayes factors between approximately 14 and 26 in favor of H1. This range represents “substantial” to “strong” evidence according to conventional Bayes factor classifications. Second, in many fields the 𝑃 < 0.005 standard would reduce the false positive rate to levels we judge to be reasonable” (B72, page 8).
However, the model that these authors employ ignores two factors which mitigate against the positive consequences of lowering α. First, it ignores the role of publication bias. Second, lowering α would also lower statistical power. So while lowering α would reduce the rate of false positives, it would also reduce the capability to identify real relationships.
In the following numerical analysis, I show that once one accommodates these factors, the benefits of lowering α disappear, so that the world of academic publishing when α = 0.005 looks virtually identical to the world of α = 0.05, at least with respect to the signal value of statistically significant estimates.
B72 demonstrate the benefit of lowering the level of significance as follows: Let α be the level of significance and β the rate of Type II error, so that Power is given by (1-β). Define a third parameter, ϕ, as the prior probability that H0 is true.
In any given study, ϕ is either 1 or 0; i.e., a relationship exists or it doesn’t. But consider a large number of “similar” studies, all exploring possible relationships between different x’s and y’s. Some of these relationships will really exist in the population, and some will not. ϕ is the probability that a randomly chosen study estimates a relationship where none really exists.
B72 use these building blocks to develop two useful constructs. First is Prior Odds, defined as Pr(H1)/Pr(H0) = (1- ϕ)/ϕ. They posit the following range of values as plausible for real-life research scenarios: (i) 1:40, (ii) 1:10, and (iii) 1:5.
Second is the False Positive Rate. Let ϕα be the probability that no relationship exists but Type I error produces a significant finding. Let (1-ϕ)(1-β) be the probability that a relationship exists and the study has sufficient power to identify it. The percent of significant estimates in published studies for which there is no underlying, real relationship is thus given by
(1) False Positive Rate(FPR) = ϕα / [ϕα+(1-ϕ)(1-β)] .
Table 1 reports False Positive Rates for different Prior Odds and Power values when α = 0.05. Taking a Prior Odds value of 1:10 as representative, they show that FPRs are distressing large over a wide range of Power values. For example, given a Power value of 0.50 — the same value that Christensen and Miguel (2017) use in their calculations — there is only a 50% chance that a statistically significant, published estimate represents something real. With smaller Power values — such as those estimated by Ioannidis et al. (2017) — the probability that a significant estimate is a false positive is actually greater than the probability that it represents something real.
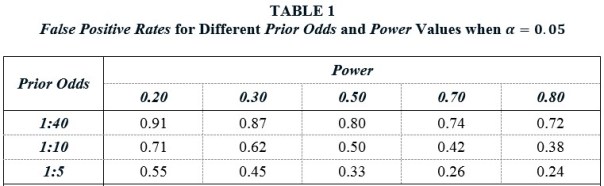
Table 2 shows that lowering α to 0.005 substantially improves this state of affairs. False Positive Rates are everywhere much lower. For example, when Prior Odds is 1:10 and Power is 0.50, the FPR falls to 9%, compared to 50% when α = 0.05. Hence their advocacy for a lower α value.
Missing from the above analysis is any mention of publication bias. Publication bias is the well-known tendency of journals to favor significant findings over insignificant findings. This also has spillovers on the behavior of researchers, who may engage in p-hacking and other suspect practices in order to obtain significant results. Though measuring the prevalence of publication bias is challenging, a recent study estimates that significant findings are 30 times more likely to be published than insignificant findings (Andrews and Kasy, 2017). As a result, insignificant findings will be underrepresented, and significant findings, overrepresented, in the published literature.
Following Ioannidis (2005) and others, I introduce a Bias term, defined as the decreased share of insignificant estimates that appear in the published literature as a result of publication bias. If Pr(insignificant) is the probability that a study reports an insignificant estimate in a world without publication bias, then the associated probability with bias is Pr(insignificant)∙(1-Bias). Correspondingly, the probability of a significant finding increases by Pr(insignificant)∙Bias. It follows that the FPR adjusted for Bias is given by
(2) False Positive Rate(FPR) = [ϕα + ϕ(1-α)Bias] / [ϕα + ϕ(1-α)Bias + (1-ϕ)(1-β) + (1-ϕ)βBias].
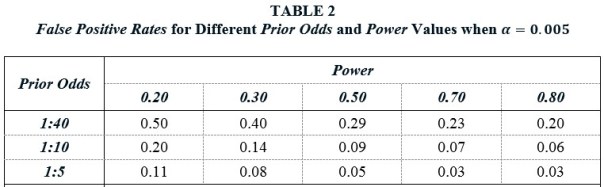
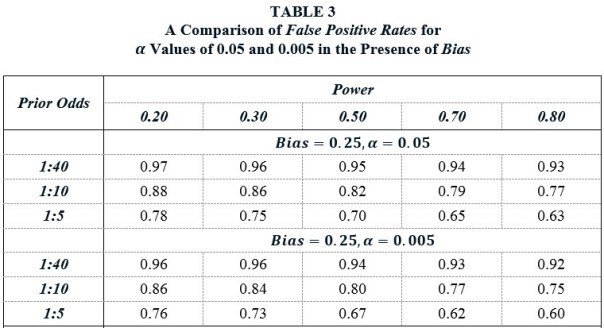
Table 3 shows the profound effect that Bias has on the False Positive Rate. The top panel recalculates the FPRs from Table 1 when Bias = 0.25. As points of comparison, Ioannidis et al. (2017) assume Bias values between 0.10 and 0.80, Christensen and Miguel (2016) assume a Bias value of 0.30, and Maniadis et al. (2017) assume Bias values of 0.30 and 0.40, though these are applied specifically to replications.
Returning to the previous benchmark case of Prior Odds = 1:10 and Power = 0.50, we see that the FPR when α = 0.05 is a whopping 82%. In a world of Bias, lowering α to 0.005 has little effect, as the corresponding FPR is 0.80. Why is that? Lowering α to 0.005 produces a lot more insignificant estimates, which also means a lot more false positives. This counteracts the benefit of the higher significance standard.
Advocates of lowering α might counter that decreasing α would also have the effect of decreasing Bias, since it would make it harder to p-hack one’s way to a significant result if no relationship really exists. However, lowering α would also diminish Power, since it would be harder for true relationships to achieve significance. Just how all these consequences of lowering would play out in practice is unknown, but TABLE 4 present a less than sanguine picture.
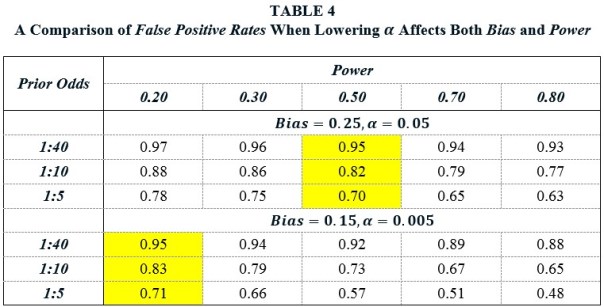
Suppose that before the change in α, Bias = 0.25 and Power = 0.50. Lowering α from 0.05 to 0.005 decreases Bias and Power. Suppose that the new values are Bias = 0.15 and Power = 0.20. A comparison of these two panels shows that the ultimate effect of decreasing α on the False Positive Rate is approximately zero.
It is, of course, possible that lowering α would reduce Bias to near zero values and that the reduction in Power would not be so great as to counteract its benefit. However, it would not be enough for researchers to forswear practices such as p-hacking and HARKing. Journals would also have to discontinue their preference for significant results. If one thinks that it is unlikely that journals would ever do that, then it is hard to avoid the conclusion that it is also unlikely that lowering α to 0.005 would help with science’s credibility problem.
Bob Reed is a professor of economics at the University of Canterbury in New Zealand. He is also co-organizer of the blogsite The Replication Network. He can be contacted at bob.reed@canterbury.ac.nz.
REFERENCES

You must be logged in to post a comment.