Predicting Reproducibility: Rise of the Machines
[Excerpts are taken from the article “Estimating the deep replicability of scientific findings using human and artificial intelligence” by Yang Yang, Wu Youyou, and Brian Uzzi, published in PNAS]
“…we trained an artificial intelligence model to estimate a paper’s replicability using ground truth data on studies that had passed or failed manual replication tests, and then tested the model’s generalizability on an extensive set of out-of-sample studies.”
“Three methods to estimate a study’s risk of passing or failing replication have been assessed: the statistics reported in the original study (e.g., P values and effect size, also known as “reviewer metrics”), prediction markets, and surveys.”
“Our model estimates differences in predictive power according to the information used to construct the model—the paper’s narrative, paper’s reported statistics, or both.”
“After calibrating the model with the training data, we test it on hundreds of out-of-sample, manually replicated studies. Table 1 presents the study’s data sources, which include 2 million abstracts from scientific papers…and 413 manually replicated studies from 80 journals.”

“Our methodology involves three stages of development, and in stage 1 of this analysis, we obtained the manuscripts of all 96 [RPP] studies and stripped each paper of all nontext content…In stage 2, a neural-network-based method—word2vec (29) with standard settings—was used to quantitatively represent a paper’s narrative content by defining the quantitative relationship (co-occurrence) of each word with every other word in the corpus of words in the training set.”
“In stage 3, we predicted a study’s manually replicated outcome (pass or fail) from its paper-level vector using a simple ensemble model of bagging with random forests and bagging with logistic… This simple ensemble model generates predictions of a study’s likelihood of replicating [0.0, 1.0] using threefold repeated cross-validation. It is trained on a random draw of 67% of the papers to predict outcome for the remaining 33%, and the process is repeated 100 times with different random splits of training sets vs. test sets.”
“A typical standard for evaluating accuracy, which is assessed relative to a threshold selected according to the evaluator’s interest, is the base rate of failure in the ground-truth data. At the base rate threshold we chose, 59 of 96 studies failed manual replication (61%). We found that the average accuracy of the machine learning narrative-only model was 0.69…In other words, on average, our model correctly predicted the true pass or fail outcome for 69% of the studies, a 13% increase over the performance of a dummy predictor with 0.61 accuracy…”
“A second standard approach to assessing predictive accuracy is top-k precision, which measures the number of actual failures among the k lowest-ranked studies based on a study’s average prediction. When k is equal to the true failure base rate, the machine learning model’s top-k precision is 0.74…”
“To compare the accuracy of the narrative-only model with conventionally used reviewer metrics, we designed a statistics-only model using the same procedure used to design the narrative only model…The reviewer metrics-only model achieved an average accuracy and top-k precision of 0.66…and 0.72…, respectively.”
“To investigate whether combining the narrative-only and reviewer metrics-only models provides more explanatory power than either model alone, we trained a model on a paper’s narrative and reviewer metrics. The combined narrative and reviewer-metrics model achieved an average accuracy of 0.71…and top-k precision of 0.76…The combined model performed significantly better in terms of accuracy and top-k precision than either the narrative or reviewer metrics model alone…”
“We ran robustness tests of our machine learning model on five currently available out-of-sample datasets that report pass or fail outcomes…Fig. 3 summarizes the out-of-sample testing results for narrative (blue), reviewer metrics (green), and narrative-plus-reviewer metrics (orange) models.”
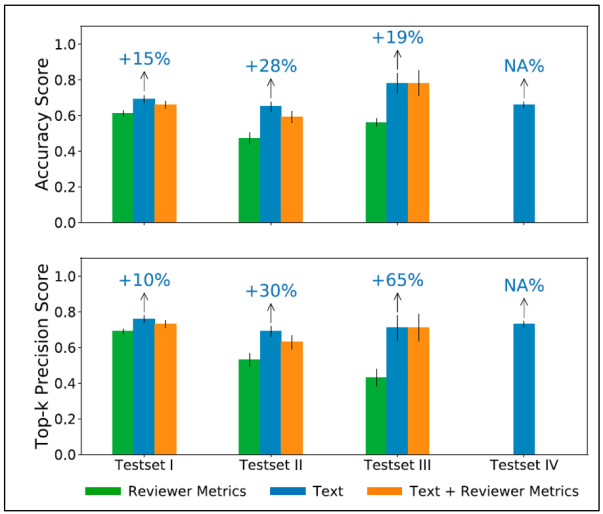
“Test set I…consists of eight similarly conducted published psychology replication datasets (n = 117). The machine learning model generated an out-of-sample accuracy and top-k precision of 0.69 and 0.76, respectively.”
“Test set II…consists of one set of 57 psychology replications done primarily by students as class projects, suggesting more noise in the “ground truth” data. Under these conditions of relatively high noise in the data, the machine learning model yielded an out-of-sample accuracy and top-k precision of 0.65 and 0.69, respectively.”
“Test sets III and IV are notable because they represent out-of-sample tests in the discipline of economics, a discipline that uses different jargon and studies different behavioral topics than does psychology—the discipline on which the model was trained…Test set III includes 18 economics experiments…Test set IV includes 122 economics studies compiled by the Economics Replication Wiki, The accuracy scores were 0.78 and 0.66, and the top-k precision scores were 0.71 and 0.73, respectively.”
“In another type of out-sample-test, we compared the machine learning model with prediction markets…To construct our test, we collected the subsample of 100 papers from test sets I to IV that were included in prediction markets and ranked papers from least to most likely to replicate per the reported results of each prediction market and each associated survey. We then ranked the machine learning model’s predictions of the same papers from least to most likely to replicate.
“In comparing prediction markets, survey, and our machine learning model, we operated under the assumption that the most important papers to correctly identify for manual replication tests are the papers predicted to be least and most likely to replicate.”
“With respect to the 10 most confident predictions of passing, the machine learning model predicts 90% of the studies correctly; the market or survey methods correctly classify 90% of the studies. Among the 10 most confident predictions of failing, the market or survey methods correctly classify 100% of the studies, and the machine learning model correctly classifies 90% of the studies.”
“Machine learning appears to have the potential to aid the science of replication. Used alone, it offers accurate predictions at levels similar to prediction markets or surveys.”
“Though the findings should be taken as preliminary given the necessarily limited datasets with ground-truth data, our out-of-sample tests offer initial results that machine learning produces consistent predictions across studies having diverse methods, topics, disciplines, journals, replication procedures, and periods.”
To read the article, click here.

You must be logged in to post a comment.