VASISHTH: The Statistical Significance Filter Leads To Overoptimistic Expectations of Replicability
[This blog draws on the article “The statistical significance filter leads to overoptimistic expectations of replicability”, authored by Shravan Vasishth, Daniela Mertzen, Lena A. Jäger, and Andrew Gelman, published in the Journal of Memory and Language, 103, 151-175, 2018. An open access version of the article is available here.]
The Problem
Statistics textbooks tell us that the sample mean is an unbiased estimate of the true mean. This is technically true. But the textbooks leave out a very important detail.
When statistical power is low, any statistically significant effect that the researcher finds is guaranteed to be a mis-estimate: compared to the true value, the estimate will have a larger magnitude (so-called Type M error), and it could even have the wrong sign (so-called Type S error). This point can be illustrated through a quick simulation:
Imagine that the true effect has value 15, and the standard deviation is 100. Assuming that the data are generated from a normal distribution, an independent and identically distributed sample of size 20 will have power 10%. In this scenario, if you repeatedly sample from this distribution, in a few cases you will get a statistically significant effect. Each of those cases will have a sample mean that is very far away from the true value, and might even have the wrong sign. The figure below reports results from 50 simulations, ordered from smallest to largest estimated mean. Now, in the same scenario, if you increase sample size to 350, you will have power at 80%. In this case, whenever you get a statistically significant effect, it will be close to the true value; you no longer have a Type M error problem. This is also shown in the figure below.
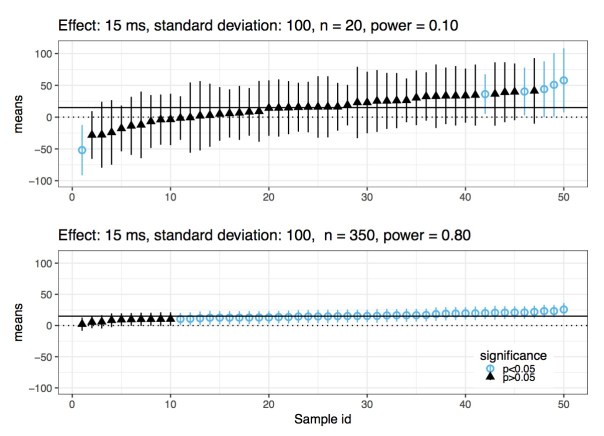
As the statistician Andrew Gelman put it, the maximum likelihood estimate can be “super-duper biased”(StanCon 2017, New York).
Given that we publish papers based on whether an effect is statistically significant or not, in situations where power is low, every one of those estimates that we see in papers will be severely biased. Surprisingly, I have never seen this point discussed in a mathematical statistics textbook. When I did my MSc in Statistics at the University of Sheffield (2011 to 2015), this important detail was never mentioned at any point. It should be the first thing one learns when studying null hypothesis significance testing.
Because this point is not widely appreciated yet, I decided to spend two years attempting to replicate a well-known result from the top ranking journal in my field. The scientific details are irrelevant here; the important point is that there are several significant effects in the paper, and we attempt to obtain similar estimates by rerunning the study seven times. The effects reported in the paper that we try to replicate are quite plausible given theory, so there is no a priori reason to believe that these results might be false positives.
You see the results of our replication attempts in the three figures below. The three blue bars show the results from the original data; the bars shown here represent 95% Bayesian credible intervals, and the midpoint is the mean of the posterior distribution. The original analyses were done using null hypothesis significance testing, which means that all the three published results were either significant or marginally significant. Now compare the blue bars with the black ones; the black bars represent our replication attempts. What is striking here is that all our estimates from the replication attempts are shrunk towards zero. This strongly implies that the original claims were driven by a classic type M error. The published results are “super-duper biased”, as Gelman would say.
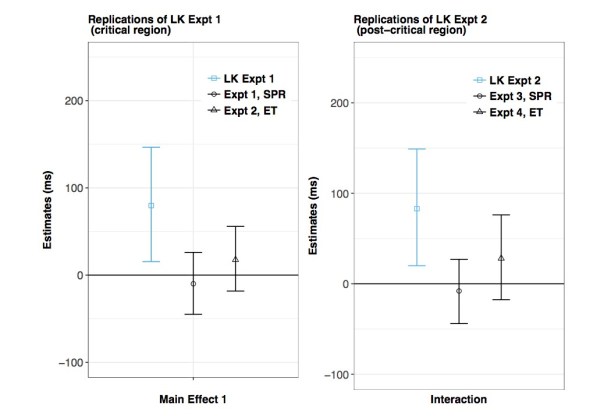
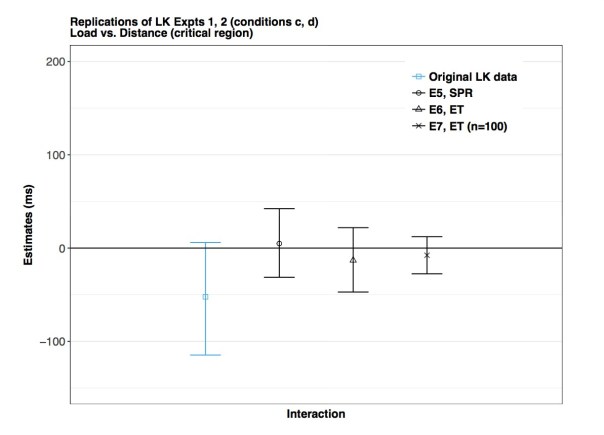
An important take-home point here is that the original data had significant or nearly significant effects, but the estimates also had extremely high uncertainty. We see that from the wide 95% credible intervals in the blue bars. We should pay attention to the uncertainty of our estimates, and not just whether the effect is significant or not. If the uncertainty is high, the significant effect probably represents a biased estimate, as explained above.
A Solution
What is a better way to proceed when analysing data? The null hypothesis significance testing framework is dead on arrival if you have insufficient power: you’re doomed to publish overestimates of the effects you are interested in.
A much more sensible way is to focus on quantifying uncertainty about your estimate. The Bayesian framework provides a straightforward methodology for achieving this goal.
1) Run your experiment until you achieve a satisfactorily low uncertainty of your estimate; in each particular domain, what counts as satisfactorily low can be established by specifying the range of quantitative predictions made by theory. In our paper, we discuss the details of how we do this in our particular domain of interest. We also explain how we can interpret these results in the context of theoretical predictions; we use a method that is sometimes called the region of practical equivalence approach.
2) Conduct direct replications to establish the robustness of your estimates. Andrew Gelman has called this the “secret weapon”. There is only one way to determine whether one has found a replicable effect: actual replications.
3) Preregistration, open access to the published data and code are critical to the process of doing good science. Surprisingly, these important ideas have not yet been widely adopted. People continue to hoard their data and code, often refusing to release it even on request. This is true at least for psychology, linguistics, some areas of medicine, and surprisingly, even statistics.
When I say all this to my colleagues in my field, a common reaction from them is that they can’t afford to run high-power studies. I have two responses to that. First, you need to use the right tool for the job. When power is low, prior knowledge needs to be brought into the analysis; in other words, you need Bayes. Second, for the researcher to say that they want to study subtle questions but they can’t be bothered to collect enough data to get an accurate answer is analogous to a medical researcher saying that he wants to cure cancer but all he has is duct tape, so let’s just go with that.
Is There Any Point In Discussing These Issues?
None of the points discussed here are new. Statisticians and psychologists have been pointing out these problems since at least the 1970s. Psychologists like Meehl and Cohen energetically tried to educate the world about the problems associated with low statistical power. Despite their efforts, not much has changed. Many scientists react extremely negatively to criticisms about the status quo. In fact, just three days ago, at an international conference I was delivered a message from a prominent US lab that I am seen as a “stats fetishist”. Instead of stopping to consider what they might be doing wrong, they dismiss any criticism as fetishism.
One fundamental problem for science seems to be the problem of statistical ignorance. I don’t know anybody in my field who would knowingly make such mistakes. Most people who use statistics to carry out their scientific goals treat it as something of secondary importance. What is needed is an attitude shift: every scientist using statistical methods needs to spend a serious amount of effort into acquiring sufficient knowledge to use statistics as intended. Curricula in graduate programs need to be expanded to include courses taught by professional statisticians who know what they’re doing.
Another fundamental problem here is that scientists are usually unwilling to accept that they ever get anything wrong. It is completely normal to find people who publish paper after paper over a 30 or 40-year career that seemingly validates every claim that they ever made in the past. When one believes that one is always right, how can one ever question the methods and the reasoning that one uses on a day-to-day basis?
A good example is the recently reported behavior of the Max Planck director Tania Singer. Science reports: “Scientific discussions could also get overheated, lab members say. “It was very difficult to tell her if the data did not support her hypothesis,” says one researcher who worked with Singer.”
Until senior scientists such as Singer start modelling good behaviour by openly accepting that they can be wrong, and until the time comes that people start taking statistical education seriously, my expectation is that nothing will change, and business will go on as usual:
1) Run a low-powered study
2) P-hack the data until statistical significance is reached and the desired outcome found
3) Publish result
4) Repeat
It has been a successful formula. It has given many people tenure and prestigious awards, so there is very little motivation for changing anything.
Shravan Vasishth is Professor of Linguistics, University of Potsdam, Germany. His biographical and contact information can be found here.

Pingback: GOODMAN: When You’re Selecting Significant Findings, You’re Selecting Inflated Estimates | The Replication Network