This instalment follows on yesterday’s post where I addressed two questions: Are there more replications in economics than there used to be? And, Which journals publish replications? These questions deal with the descriptive aspect of replications. We saw that replications seemingly constitute a relatively small — arguably negligible – component of the empirical output of economists. And while that component appears to be growing, it is growing at a rate that is, for all practical purposes, inconsequential. I would like to move on to more prescriptive/normative subjects.
Before I can get there, however, I need to acknowledge that the assessment above relies on a very specific definition of a replication, and that the sample of replications on which it is based is primarily drawn from one data source: Replication Wiki. Is it possible that there are a lot more replications “out there” that are not being counted? More generally, is it even physically possible to know how many replications there are?
Is it possible to know how many replications there are?
One of the most comprehensive assessments of the number of replications in economics was done in a study by Frank Mueller-Langer, Benedikt Fecher, Dietmar Harhoff, and Gert Wagner, published in Research Policy in 2019 and blogged about here. ML et al. reviewed all articles published in the top 50 economics journals between 1974 and 2014. They calculated a “replication rate” of 0.1%. That is, 0.1% of all the articles in the top 50 economics journals during this time period were replication studies.
0.1% is likely an understatement of the overall replication rate in economics, as replications are likely to be underrepresented in the top journals. With 400 mainline economics journals, each publishing an average of approximately 100 articles a year, it is a daunting task to assess the replication rate for the whole discipline.
One possibility is to scrape the internet for economics articles and use machine learning algorithms to identify replications. In unpublished work, colleagues of mine at the University of Canterbury used “convolutional neural networks” to perform this task. They compared the texts of the replication studies listed at The Replication Network (TRN) with a random sample of economics articles from RePEc.
Their final analysis produced a false negative error rate (the rate at which replications are mistakenly classified as non-replications) of 17%. The false positive rate (the rate at which non-replications are mistakenly classified as replications) was 5%.
To give a better feel for what these numbers means, consider a scenario where the replication rate is 1%. Suppose we have a sample of 10,000 papers, of which 100 are replications. Applying the false negative and positive rates above produces the numbers in TABLE 1.

Given this sample, a researcher would identify 578 replications, of which 83 would be true replications, and 495 would be “false replications”, that is, non-replication studies falsely categorized as replication studies. One would have to get a false positive rate below 1% before even half of the identified “replications” were true replications. Given a relatively low replication rate (here 1%), it is obvious that it is highly unlikely that machine learning will ever be accurate enough to produce reliable estimates of the overall replication rate in the discipline.
A final alternative is to follow the procedure of ML et al., but choose a set of 50 journals outside the top economics journals. However, as reported in yesterday’s blog, replications tend to be clustered in a relatively small number of journals. Results of replication rates would likely depend greatly on the particular sample of journals that was used.
Putting the above together, the answer to the question “Is it possible to know how many replications there are” appears to be no.
I now move on to assessing what we have learned from the replications that have been done to date. Specifically, have replications uncovered a reproducibility problem in economics?
Is there a replication crisis in economics?
The last decade has seen increasing concern that science has a reproducibility problem. So it is fair to ask, is there a replication crisis in economics? Probably the most famous study of replication rates is the study by Brian Nosek and the Open Science Collaboration (Science, 2015) that assessed the replication rate of 100 experiments in psychology. They reported an overall “successful replication rate” of 39%. Similar studies focused more on economics report higher rates (see TABLE 2).
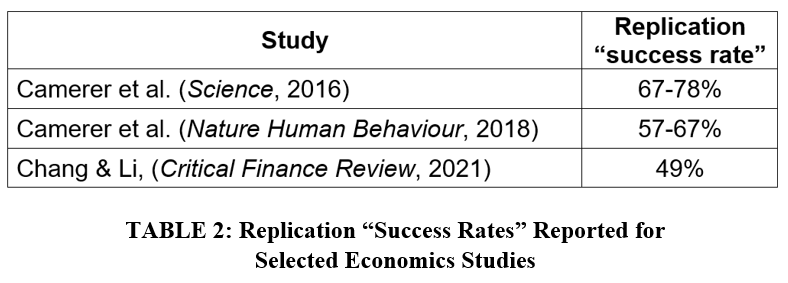
The next section will delve a little more into the meaning of “replication success”. For now, let’s first ask, what rate of success should we expect to see if science is performing as it is supposed to? In a blog for TRN (“The Statistical Fundamentals of (Non-)Replicability”), Jeff Miller considers the case where a replication is defined to be “successful” when it reproduces a statistically significant estimate reported in a previous study (see FIGURE 1 below).
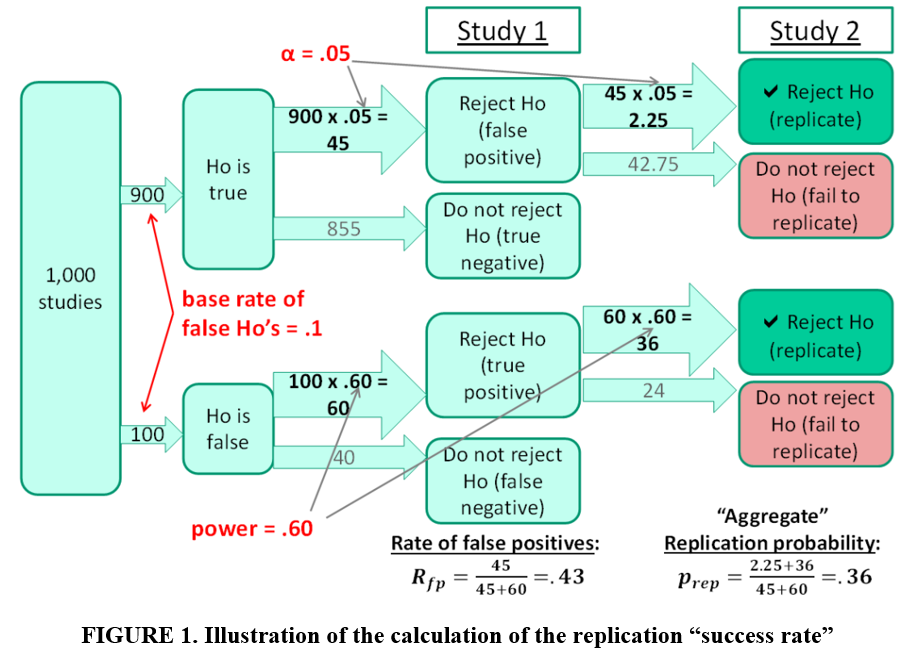
FIGURE 1 assumes 1000 studies each assess a different treatment. 10% of the treatments are effective. 90% have no effect. Statistical significance is set at 5% and all studies have statistical power of 60%. The latter implies that 60 of the 100 studies with effective treatments produce significant estimates. The Type I error rate implies that 45 of the remaining 900 studies with ineffectual treatments also generate significant estimates. As a result, 105 significant estimates are produced from the initial set of 1000 studies.
If these 105 studies are replicated, one would expect to see approximately 38 significant estimates, leading to a replication “success rate” of 36% (see bottom right of FIGURE 1). Note that there is no publication bias here. No “file drawer effect”. Even when science works as it is supposed to, we should not expect a replication “success rate” of 100%. “Success rates” far less than 100% are perfectly consistent with well-functioning science.
Conclusion
Replications come in many sizes, shapes, and flavors. Even if we could agree on a common definition of a replication, it would be very challenging to make discipline-level conclusions about the number of replications that get published. Given the limitations of machine learning algorithms, there is no substitute for personally assessing each article individually. With approximately 400 mainline economics journals, each publishing approximately 100 articles a year, that is a monumental, seemingly insurmountable, challenge.
Beyond the problem of defining a replication, beyond the problem of defining “replication success”, there is the further problem of interpreting “success rates”. One might think that a 36% replication success rate was an indicator that science was failing miserably. Not necessarily so.
The final instalment of this series will explore these topics further. The goal is to arrive at an overall assessment of the potential for replications to make a substantial contribution to our understanding of economic phenomena (to read the next instalment, click here).
Bob Reed is a professor of economics at the University of Canterbury in New Zealand. He is also co-organizer of the blogsite The Replication Network and Principal Investigator at UCMeta. He can be contacted at bob.reed@canterbury.ac.nz.

Pingback: New: Journal of Comments and Replications in Economics – Economist Writing Every Day