This final instalment on the state of replications in economics, 2020 version, continues the discussion of how to define “replication success” (see here and here for earlier instalments). It then delves further into interpreting the results of a replication. I conclude with an assessment of the potential for replications to contribute to our understanding of economic phenomena.
How should one define “replication success”?
In their seminal article assessing the rate of replication in psychology, Open Science Collaboration (2015) employed a variety of definitions of replication success. One of their measures has come to dominate all others: obtaining a statistically significant estimate with the same sign as the original study (“SS-SS”). For example, this is the definition of replication success employed by the massive SCORE project currently being undertaken by the Center for Open Science.
The reason for the “SS-SS” definition of replication success is obvious. It can easily be applied across a wide variety of circumstances, allowing a one-size, fits-all measure of success. It melds two aspects of parameter estimation – effect size and statistical significance – into a binary measure of success. However, studies differ in the nature of their contributions. For some studies, statistical significance may be all that matters, say when establishing the prediction of a given theory. For others, the size of the effect may be what’s important, say when one is concerned about the effect of a tax cut on government revenues.
The following example illustrates the problem. Suppose a study reports that a 10% increase in unemployment benefits is estimated to increase unemployment duration by 5%, with a 95% confidence interval of [4%, 6%]. Consider two replication studies. Replication #1 estimates a mean effect of 2% with corresponding confidence interval of [1%, 3%]. Replication #2 estimates a mean effect of 5%, but the effect is insignificant with a corresponding confidence interval of [0%, 10%].
Did either of the two replications “successfully replicate” the original? Did both? Did none? The answer to this question largely depends on the motivation behind the original analysis. Was the main contribution of the original study to demonstrate that unemployment benefits affect unemployment durations? Or was the motivation primarily budgetary? So that the size of the effect was the important empirical contribution?
There is no general right or wrong answer to these questions. It is study-specific. Maybe even researcher-specific. For this reason, while I understand the desire to develop one-size-fits-all measures of success, it is not clear how to interpret these “success rates”. This is especially true when one recognizes — and as I discussed in the previous instalment to this blog — that “success rates” below 100%, even well below 100%, are totally compatible with well-functioning science.
How should we interpret the results of a replication?
The preceding discussion might give the impression that replications are not very useful. While measures of the overall “success rate” of replications may not tell us much, they can be very insightful in individual cases.
In a blog I wrote for TRN entitled “The Replication Crisis – A Single Replication Can Make a Big Difference”, I showed how a single replication can substantially impact one’s assessment of a previously published study.
Define “Prior Odds” as the Prob(Treatment is effective):Prob(Treatment is ineffective). Define the “False Positive Rate” (FPR) as the percent of statistically significant estimates in published studies for which the true underlying effect is zero; i.e, the treatment has no effect. If the prior odds of a treatment being effective are relatively low, Type I error will generate a large number of “false” significant estimates that can overwhelm the significant estimates associated with effective treatments, causing the FPR to be high. TABLE 1 below illustrates this.
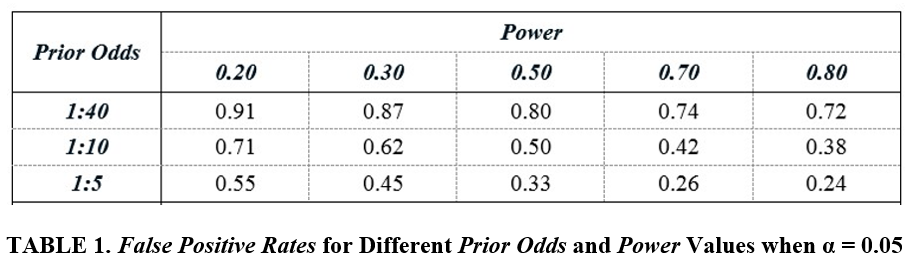
The FPR values in the table range from 0.24 to 0.91. For example, given 1:10 odds that a randomly chosen treatment is effective, and assuming studies have Power equal to 0.50, the probability that a statistically significant estimate is a false positive is 50%. Alternatively, if we take a Power value of 0.20, which is approximately equal to the value that Ioannidis et al. (2017) report as the median value for empirical research in economics, the FPR rises to 71%.
It needs to be emphasized that these high FPRs have nothing to do with publication bias or file drawer effects. They are the natural outcomes of a world of discovery in which Type I error is combined with a situation where most studied phenomena are non-existent or economically negligible.
TABLE 2 reports what happens when a researcher in this environment replicates a randomly selected significant estimate. The left column reports the researcher’s initial assessment that the finding is a false positive (as per TABLE 1). The table shows how that probability changes as a result of a successful replication.
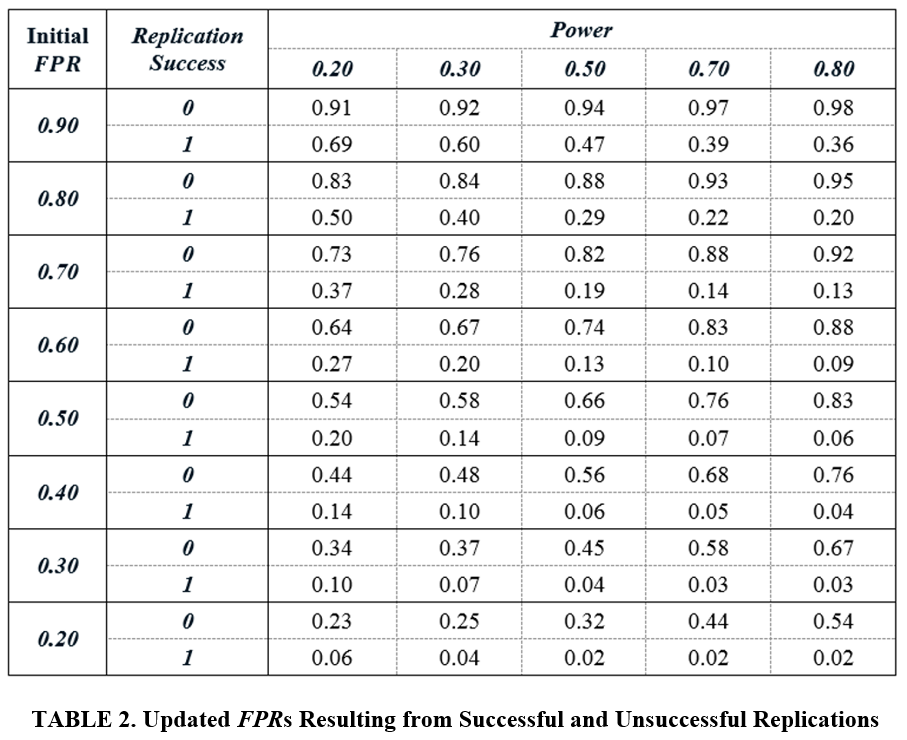
For example, suppose the researcher thinks there is a 50% chance that a given empirical claim is a false positive (Initial FPR = 50%). The researcher then performs a replication and obtains a significant estimate. If the replication study had 50% Power, the updated FPR would fall from 50% to 9%.
TABLE 2 demonstrates that successful replications produce substantial decreases in false positive rates across a wide range of initial FPRs and Power values. In other words, while discipline-wide measures of “success rates” may not be very informative, replications can have a powerful impact on the confidence that researchers attach to individual estimates in the literature.
Do replications have a unique role to play in contributing to our understanding of economic phenomena?
To date, replications have not had much of an effect on how economists do their business. The discipline has made great strides in encouraging transparency by requiring authors to make their data and code available. However, this greater transparency has not resulted in a meaningful increase in published replications. While there are no doubt many reasons for this, one reason may be that economists do not appreciate the unique role that replications can play in contributing to our understanding of economic phenomena.
The potential for empirical analysis to inform our understanding of the world is conditioned on the confidence researchers have in the published literature. While economists may differ in their assessment of the severity of false positives, the message of TABLE 2 is that, for virtually all values of FPRs, replications substantially impact that assessment. A successful replication lowers, often dramatically lowers, the probability that a given empirical finding is a false positive.
It is worth emphasizing that replications are uniquely positioned to make this contribution. New studies fall under the cloud of uncertainty that hangs over all original findings; namely, the rational suspicion that reported results are merely a statistical artefact. Replications, because of their focus on individual findings, are able to break through the fog. It is hoped that economists will start to recognize the unique role that replications can play in the process of scientific discovery. And that publishing opportunities for well-done replications; and appropriate professional rewards for the researchers who do them, follow.
Bob Reed is a professor of economics at the University of Canterbury in New Zealand. He is also co-organizer of the blogsite The Replication Network and Principal Investigator at UCMeta. He can be contacted at bob.reed@canterbury.ac.nz.

You must be logged in to post a comment.