[From the article “It’s not a replication crisis. It’s an innovation opportunity” by Jon Brock, published in Medium]
“It takes me a few moments to recognise the name. I’ve arrived early at the National Health and Medical Research Council’s Research Translation Symposium at the University of Sydney and I’m sitting, coffee in hand, planning my route through the day’s program. A gentleman, quietly spoken, in a sharp blue jacket, asks to share my table. His conference badge identifies him as C. Glenn Begley. We’re shaking hands when I remember his significance.”
“Six years ago, Begley published an article in the journal Nature that was, in hindsight, a seminal moment in science. In three tersely worded pages, it ushered in what’s become known as the “replication crisis” — a growing recognition that many published scientific findings cannot be reproduced by independent scientists and may, therefore, be untrue. There’s a rueful smile when I mention this, a slight rolling of the eyes. But he’s soon telling me the back story.”
To read the article, click here.
[From the preprint “When and Why to Replicate: As Easy as 1, 2, 3?” by Sarahanne Field, Rink Hoekstra, Laura Bringmann, and Don van Ravenzwaaij, posted at PsyArXiv Preprints.]
“…a flood of new replications of existing research have reached the literature, and more are being conducted. In theory, this uptick in the number of replications being conducted is a good development for the field…”
“… however in practice, so much interest in conducting replications leads to a logistical problem. There is a vast body of literature that could be subject to replication. But the question is: how does one select which studies to replicate from the ever-increasing pool of candidates out there?”
“In this paper, we apply a Bayesian reanalysis to several recent research findings, the end-goal being to demonstrate a technique one can use to reduce a large pool of potential replication targets to a manageable list. The Bayesian reanalysis is diagnostic in the sense that it can assist us in separating findings into three classes, or tiers of results:”
“(1) results for which the statistical evidence pro-alternative is compelling;”
“(2) results for which the statistical evidence pro-null is compelling;”
“(3) results for which the statistical evidence is ambiguous.”
“… p–values are unable to differentiate between results which belong in the second of these categorical classes, and those that belong in the third.”
“…we will make an initial selection based on those studies in tier 3: whose results yield only ambiguous evidence in relation to support for their reported hypotheses. For this purpose, we will judge such ambiguity, or low evidential strength, as when a study’s. BF10 lies between 1/3 and 3, which, by Jeffrey’s (1961) classification system provides no more than ‘anecdotal’ evidence for one hypothesis over the other.”
“…The approach we advocate and apply in this article can be simple and relatively fast to conduct, and affords the user access to important information about the strength of evidence contained in a published study. Although efficient, this approach has the potential to maximize the impact of the outcomes of those replications, and minimize the waste of resources that could result from a haphazard approach to replication. Combining a quantitative reanalysis with a qualitative assessment process of a large group of potential replication targets in a simple approach such as the one presented in this paper, allows the information of multiple sources to prioritize replication targets…”
[From the article “Automatic extraction of quantitative data from ClinicalTrials.gov to conduct meta-analyses” by Richeek Pradhan et al., published in the Journal of Clinical Epidemiology]
“Systematic reviews and meta-analyses are labor-intensive and time-consuming. Automated extraction of quantitative data from primary studies can accelerate this process.”
“ClinicalTrials.gov, launched in 2000, is the world’s largest trial repository of results data from clinical trials; it has been used as a source instead of journal articles. …We developed a Python-based software application (EXACT) that automatically extracts data required for meta-analysis from the ClinicalTrials.gov database in a spreadsheet format. We confirmed the accuracy of the extracted data and then used those data to repeat meta-analyses in three published systematic reviews.”
“EXACT extracted data at ClincalTrials.gov with 100% accuracy, and it required 60% less time than the usual practice of manu-ally extracting data from journal articles. We found that 87% of the data elements extracted using EXACT matched those extracted manually from the journal articles. We were able to reproduce 24 of 28 outcomes using the journal article data. Of these 24 outcomes, we were able to reproduce 83.3% of the published estimates using data at ClinicalTrials.gov.”
To read the article, click here.
A recent news piece in Nature reported in glowing terms on the “first analysis of ‘pre-registered’ studies”, stating that “[pre-registration] seems to work as intended: to reduce publication bias for positive results.” There are reasons to be somewhat dubious about this claim.
The analysis in question appears in a preprint, “Open Science challenges, benefits and tips in early career and beyond”. The analysis is a small part of the paper, occupying about half a page of an 11-page document. The paper draws no strong claims from the data; the Nature story goes well beyond what the paper says, though I can easily believe the authors waxed proudly about their results when interviewed by the journalist.
The preprint is really an essay on preregistration and true to its title discusses challenges and risks, esp. for early stage investigators, as well as potential benefits. The authors are proponents of preregistration and reach the expected conclusion that the benefits outweigh the risks.
The angle of the Nature story is that preregistration cuts publication bias by increasing the proportion of null results that are published. The reporter drives the point home with a graphic (reproduced below) that vividly shows the increase in null findings in bright red: 55-66% with pre-registration vs. 5-20% without. Sounds convincing.
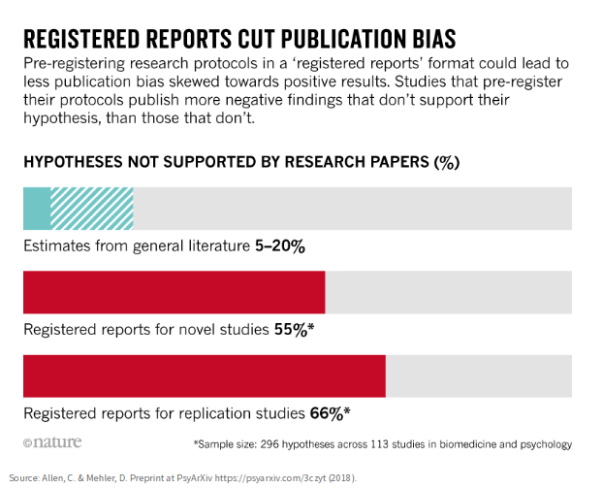
But hold the bus! There are several problems.
1. The data comes from a biased sample. The first wave of pre-registrants are presumably people committed to the ideal who want to do it right. There is no rigorous way to extrapolate from this (or any) biased sample to the population as a whole.
2. The study confounds two factors: preregistration and journals’ willingness to publish null results. There’s no way to allocate the treatment effect without a study that separates the factors. Perhaps the results would be just as good if journals were eager to publish null findings that weren’t preregistered.
3. The output variable is, at best, a surrogate for what we actually want. Is our goal really to increase the number of null results in the literature? If so, there are many trivial ways to accomplish this. No. I suspect the true goal is to improve the quality of science. The proportion of nulls is somehow thought to be an indicator of quality, although I’m not aware of any evidence to support this claim.
The research enterprise is a complex dynamic system driven by economic forces. Before mucking about with something as central as the criteria for publication, one needs to consider long term unintended consequences. Unless we repeal publish-or-perish, everyone in the field will continue publishing in order to keep their jobs. Unless we improve the quality of people in the field or give them more money or time to do research, we’ll be stuck with the same researchers publishing the best papers they can with limited resources.
Preregistration will make it harder and more costly to do research and the likely first-order effect will be to reduce the amount of research. If the change preferentially makes it harder to do good research, the outcome will be a classic unintended consequence: we will worsen, not improve, overall research quality.
Are you willing to risk these unintended consequences without a proper controlled study of the proposed change? I hope not.
This begs the question of how to do such a study as there is no obvious way to blind participants as to whether they’re in the treatment (preregistration) or control group. An alternative is to look at the experience in other fields where preregistration has been in effect for a long time, for example, medical research. To date, this has not been subject to rigorous study. However, it is this author’s assessment that the outcome is not as positive as the Nature report suggests.
Nat Goodman is a retired computer scientist living in Seattle Washington. His working years were split between mainstream CS and bioinformatics and orthogonally between academia and industry. As a retiree, he’s working on whatever interests him, stopping from time-to-time to write papers and posts on aspects that might interest others. He can be contacted at natg@shore.net.
[From the article “Push button replication: Is impact evaluation evidence for international development verifiable?” by Benjamin Wood, Rui Müller, and Annette Brown, published in PLoS ONE]
“…We drew a sample of articles from the ten journals that published the most impact evaluations from low- and middle-income countries from 2010 through 2012. This set includes health, economics, and development journals.”
“…Of the 109 articles in our sample, only 27 are push button replicable, meaning the provided code run on the provided dataset produces comparable findings for the key results in the published article. The authors of 59 of the articles refused to provide replication files. Thirty of these 59 articles were published in journals that had replication file requirements in 2014, meaning these articles are non-compliant with their journal requirements.”
“…The findings presented here reveal that many economics, development, and public health researchers are a long way from adopting the norm of open research. Journals do not appear to be playing a strong role in ensuring the availability of replication files.”
To read the article, click here.
About 10 years ago, the economist Hoyt Bleakley published two important papers on the impact of health on wealth—more precisely, on the long-term economic impacts of large-scale disease eradication campaigns. In the Quarterly Journal of Economics, “Disease and Development: Evidence from Hookworm Eradication in the American South” found that a hookworm eradication campaign in the American South in the 1910s was followed by a substantial gain in adult earnings. In AEJ: Applied Economics, “Malaria Eradication in the Americas: A Retrospective Analysis of Childhood Exposure” reported similar benefits from 20th-century malaria eradication efforts in Brazil, Colombia, Mexico, and the U.S.
With my colleagues at GiveWell providing inspiration and assistance, I replicated and reanalyzed both studies. The resulting pair of papers has just appeared in the International Journal for Re-Views in Empirical Economics (hookworm, malaria). I’ve blogged my findings on givewell.org (hookworm, malaria). Short version: I can buy the Bleakley findings for malaria, but not for hookworm.
Here I will share some thoughts sparked by my experience about process—about how we generate, review, publish, and revisit research in the social sciences.
To win trust, studies need to be reanalyzed, not just replicated
Psychology is now in the throes of a replication crisis: when published lab experiments are repeated, about half the time the original results (presumably statistically different from zero) disappear (this, this). Some see a replication crisis in economics too. I do not. In my experience (this, this, this, this, this, this, this, this, …), most empirical research in economics does replicate, in the sense that original results can be matched when applying the reported methods to the reported data. The matches are perfect when original data and code are available and approximate otherwise. A paper by Federal Reserve economists reaches the opposite conclusion only by counting as non-replicable any study whose authors did not respond to a request for data.
I would say, rather, that economics is in a reanalysis crisis. Or perhaps a “robustness crisis.” When I turn from replicating a study to revising it, introducing arguable improvements to data and code, the original findings often slip away like sand through my fingers. About half the time, in fact. The split decision on the two Bleakley papers is a case in point. Another is my “reanalysis review” of the impact of incarceration on crime: of the eight studies for which data availability permitted replication, I found what I deemed to be significant methodological concerns in seven, and that ultimately led to me to reverse my reading of four. (Caveat: Essentially all my experience is with observational studies rather than field experiments, which may be more robust.)
This is why I say that half of economics studies are reliable—I’m just not sure which half. Seriously, as a partial answer to “which half?”, I conjecture that young, tenure-track researchers are more apt to produce fragile work, because they are under the most intense pressure to generate significant, non-zero results.
Review of research is under-supplied
Many studies in economics aspire to influence policy decisions that have stakes measured in billions or trillions of dollars. Yet society invests only hundreds or thousands of dollars in assessing the quality of economics research, mainly in the form of peer review. And if only half the studies that survive peer review withstand closer scrutiny, then we evidently have not reached the point of diminishing returns to investment in review.
There is something wrong with this picture. Serious assessment of published research is a public good and so is under-supplied. Who will fill the gap?
Reanalysis, like original analysis, cannot be mechanized
I like to think that in reanalyzing research, I strike a judicious balance. Ideally, I introduce appropriately tough robustness tests; yet I avoid “gotcha” specification mining, trying lots of things until I break a regression. Ultimately, it is for readers to assess my success. One might take the discretionary character of reanalysis as a fatal flaw: replication, by contrast, can be fully pre-specified and is in this sense more objective. But by the same argument, one ought not to perform original research. A better approach is to marshal the toolkit that has gradually been assembled to improve the objectivity and reliability of original research, and bring it to reanalysis—for example, posting data and code along with finished analysis, and preregistering one’s analytical plan of attack. In revisiting the Bleakley studies, I did both.
Preregistering reanalysis is a good thing
In fact, this was my first-time preregistering. I’ve heard of preregistered analysis plans that run to hundreds of pages. My plans (hookworm, malaria) just run a page or so. The Open Science Framework of the Center for Open Science serves as the perfect, public home for the documents, as an independent party that credibly time-stamped them and makes them public.
I tried to use the plans to signal my strategy, recognizing that tactics would need to be refined after encountering the data. But I did not take the plans as binding. I allowed myself to stray outside a plan, while working to inform the reader when I had done so. After all, reanalysis is a creative act too, which I think should be allowed to take unexpected turns. It’s also a social act: helpful or even peremptory comments from the original authors, as well as reviewers and editors, are bound to motivate changes late in a project.
That said, I think I have room to mature as preregisterer. I could have written my hookworm plan with more care, making it more predictive of what I ultimately did, thus adding to its credibility.
Original authors should be included in the review of replications and reanalyses, in the right way
I always send draft write-ups of replications and reanalyses to the original authors. Some don’t respond (much). Others do, and I always learn from them (Pitt, Bleakley). Clearly original authors should be heard from. But should journals give them the full powers of a referee? Maybe not. This creates an incentive for them to withhold comment on drafts sent to them before submission to a journal and then, when invited to referee, to roll out all their criticisms before the editor. Presumably some of the criticisms will be valid, and ought to be incorporated before involving other referees. Managing editor Martina Grunow explained to me how IREE threads this needle:
“We…decided that contacting the original author must be done by the replicator and before submitting the replication study to IREE (with 4 weeks waiting time whether the author responds) and that the contact (attempt or dialog) must be documented in the paper. This mainly protects the replicator against the killer argument [that the replicator failed to perform the due diligence of sharing the text with the original author]. In the case that an original author wants to comment on the replication, we offer to publish this comment along with the replication study. Up to now this did not happen. As we read in the submissions to IREE, most original authors do not reply when they are contacted by the replicators.”
I like this solution: do not use original authors as ordinary referees, but require replicators to make reasonable efforts to include original authors in the process before journal submission.
The American Economic Association’s archiving policy has holes
In 2003, the American Economic Review published a study by McCullough and Vinod, which tried—and failed—to replicate ten empirical papers in an issue of the AER. At the time, the journal merely required publishing authors to provide data and code to interested researchers upon request:
“Though the policy of the AER requires that ‘Details of computations sufficient to permit replication must be provided,’ we found that fully half of the authors would not honor the replication policy….Two authors provided neither data nor code: in one case the author said he had already lost all the files; in another case, the author initially said it would be ‘next semester’ before he would have time to honor our request, after which he ceased replying to our phone calls, e-mails, and letters. A third author, after several months and numerous requests, finally supplied us with six diskettes containing over 400 files—and no README file. Reminiscent of the attorney who responds to a subpoena with truckloads of documents, we count this author as completely noncompliant. A fourth author provided us with numerous datafiles that would not run with his code. We exchanged several e-mails with the author as we attempted to ascertain how to use the data with the code. Initially, the author replied promptly, but soon the amount of time between our question and his response grew. Finally, the author informed us that we were taking up too much of his time—we had not even managed to organize a useable data set, let alone run his data with his code, let alone determine whether his data and code would replicate his published results.”
I’ve had similar experiences. (As well as plenty of better ones, with cooperative replicatees.)
In response, AER editor Ben Bernanke announced an overhaul: henceforth, the journal would require submission of data and code to a central archive at the time of publication. The policy now applies to all American Economic Association journals, including the one that published the Bleakley study of malaria eradication.
Kudos to Bernanke and the AER, for that policy reform put the journal many years ahead of the QJE, which became the periodical of record for the Bleakley hookworm study. But in taking advantage of the Bleakley malaria data and code archive, I also ran into two serious gaps in the AEA’s policy, or at least its implementation. These leave substantial scope for original authors to impede replication. As I write:
“First, [the AEA journals] provide no access to the primary data, or at least to the code that transforms the primary data into the analysis data. The American Economic Review’s own assessment of compliance with its data availability policy highlighted this omission in 2011. ‘Simply requiring authors to submit their data prior to publication may not be sufficient to improve accuracy….The broken link in the replication process usually lies in the procedures used to transform raw data into estimation data and to perform the statistical analysis, rather than in the data themselves’ (Glandon 2011). Second, code is provided for tables only, not figures. Yet figures can play a central role in a study’s conclusions and impact. Like tables, figures distill large amounts of data to inform inference. They ought to be fully replicable, but only can be if their code is public too.”
I think much of the power of the Bleakley studies lay in figures that seemed to show kinks in long-term earnings trends with timing explicable by the eradication campaigns. In the hookworm study, those kinks pretty substantially faded in the attempted replication—and it is impossible to be sure why, for lack of access to much of the original data and code. Potential causes include discrepancies between original and replication in primary database construction, in the transformation code, or in the figure-generating code.
The AEA and other publishers can and should head-off such mysteries, with more complete archiving.
David Roodman is a Senior Advisor at GiveWell. He has replicated and reanalyzed research on foreign aid effectiveness, geomagnetic storms, alcohol taxes, immigration, microcredit, and other subjects.
[From the blog “Power to the Plan” by Clare Leaver, Owen Ozier, Pieter Serneels, and Andrew Zeitlin, posted at BITSS]
“…Our blinded pre-analytical work uncovered two decision margins that could deliver substantial increases in power: changing test statistics used and putting structure on a model for error terms. Because the value of these decisions depends on things that are hard to know ex ante — even using baseline data — they create a case for blinded analysis of endline outcomes. We argue that there are circumstances in which this can be done without risk of p-hacking, and in which the power gains from these decision margins are substantial.”
“…Kolmogorov-Smirnov (KS) tests can be better powered than OLS t-tests by a factor of four, even under additive treatment effects.”
“…Remember how machine learning is a way of getting a better fit using observables? Imposing structure on error terms is a way of getting a better fit on the *unobserved* sources of variation. That structure can take many forms: it can relate to the correlations between units, the distribution of residuals (normal? pareto?), or both. Imbens and Rubin (2015, p. 68) observe that test statistics derived from structural estimates — for example, expressly modeling the error term — can improve power to the extent that they represent a “good descriptive approximation” to the data generating process. Blinded endline data allowed us to learn about the quality of such approximations, with substantial consequences.”
“In our setting, when we turned to look at effects on student outcomes, we intended to use a linear model … But there were still a number of potential correlations to consider: some students are observed at more than one point in time; each student has multiple teachers, and schools may have both incumbents and teachers recruited under a variety of contract expectations. Linear mixed-effects (LME) models provide an avenue for implementing this.”
“Our LME model, which assumes normally distributed error terms that include a common shock at the pupil level, delivers an estimator of the effect of interest that has a standard deviation as much as 30 percent smaller than the equivalent OLS estimator. Because normality is a reasonable approximation to these error terms, the structure of LME allows it to outperform traditional random-effects. The gains from LME are conceptually comparable to an increase of 70 percent in sample size.”
“…Endline data are often far from normal and correlation structures across units are hard to know ex ante. A blinded endline approach can be a useful substitute for tools like DeclareDesign in cases where baseline data, or a realistic basis for simulating the endline data-generating process, are not available.
“There is broad consensus that well-powered studies are important, not least because they make null results more informative. Consequently, researchers invest a lot in statistical power. Our recent experience suggests that blinded analyses — whether based on pooled or partial endline data — can be a useful tool to make informed choices of models and test statistics that improve power.”
[From the article “Reproducibility of Scientific Results”, by Fiona Fidler and John Wilcox, published in The Stanford Encyclopedia of Philosophy]
“This review consists of four distinct parts. First, we look at the term “reproducibility” and related terms like “repeatability” and “replication”, presenting some definitions and conceptual discussion about the epistemic function of different types of replication studies. Second, we describe the meta-science research that has established and characterised the reproducibility crisis, including large scale replication projects and surveys of questionable research practices in various scientific communities. Third, we look at attempts to address epistemological questions about the limitations of replication, and what value it holds for scientific inquiry and the accumulation of knowledge. The fourth and final part describes some of the many initiatives the open science reform movement has proposed (and in many cases implemented) to improve reproducibility in science.”
An outline of the article is given below:
Replicating, Repeating, and Reproducing Scientific Results
1.1 An Account from the Social Sciences
1.2 An Interdisciplinary Account
1.3 A Philosophical Account
Meta-Science: Establishing, Monitoring, and Evaluating the Reproducibility Crisis
2.1 Reproducibility Projects
2.2 Publication Bias, Low Statistical Power and Inflated False Positive Rates
2.3 Questionable Research Practices
2.4 Over-Reliance on Null Hypothesis Significance Testing
2.5 Scientific Fraud
Epistemological Issues Related to Replication
3.1 The Experimenters’ Regress
3.2 Replication as a Distinguishing Feature of Science
3.3 Formalising the Logic of Replication
Open Science Reforms: Values, Tone, and Scientific Norms
4.1 Methods and Training
4.2 Reporting and Dissemination
4.3 Peer Review
4.4 Incentives and Evaluations
4.5 Values, Tone, and Scientific Norms in Open Science Reform
Conclusion
Bibliography
Academic Tools
Other Internet Resources
Related Entries
[From the blog entitled “Oh, I hate it when work is criticized (or, in this case, fails in attempted replications) and then the original researchers don’t even consider the possibility that maybe in their original work they were inadvertently just finding patterns in noise”, posted by Andrew Gelman at Statistical Modeling, Causal Inference, and Social Science]
“I promised you a sad story. But, so far, this is just one more story of a hyped claim that didn’t stand up to the rigors of science. And I can’t hold it against the researchers that they hyped it: if the claim had held up, it would’ve been an interesting and perhaps important finding, well worth hyping.”
“No, the sad part comes next. Collins reports:”
“Multi-lab experiments like this are fantastic. There’s little ambiguity about the result. That said, there is a response by Amir, Mazar and Ariely. Lots of fluff about context. No suggestion of “maybe there’s nothing here”.”
“You can read the response and judge for yourself. I think Collins’s report is accurate, and that’s what made me sad. These people care enough about this topic to conduct a study, write it up in a research article and then in a book—but they don’t seem to care enough to seriously entertain the possibility they were mistaken. It saddens me. Really, what’s the point of doing all this work if you’re not going to be open to learning?”
To read the full blog, click here.
[From the working paper, “Multiple Perspectives on Inference for Two Simple Statistical Scenarios” by van Dongen et al., posted at PsyArXiv Preprints]
“When analyzing a specific data set, statisticians usually operate within the confines of their preferred inferential paradigm. For instance, frequentist statisticians interested in hypothesis testing may report p-values, whereas those interested in estimation may seek to draw conclusions from confidence intervals. In the Bayesian realm, those who wish to test hypotheses may use Bayes factors and those who wish to estimate parameters may report credible intervals. And then there are likelihoodists, information-theorists, and machine-learners — there exists a diverse collection of statistical approaches, many of which are philosophically incompatible.”
“… We invited four groups of statisticians to analyze two real data sets, report and interpret their results in about 300 words, and discuss these results and interpretations in a round-table discussion.”
“… Despite substantial variation in the statistical approaches employed, all teams agreed that it would be premature to draw strong conclusions from either of the data sets.”
“… each analysis team added valuable insights and ideas. This reinforces the idea that a careful statistical analysis, even for the simplest of scenarios, requires more than a mechanical application of a set of rules; a careful analysis is a process that involves both skepticism and creativity.”
“… despite employing widely different approaches, all teams nevertheless arrived at a similar conclusion. This tentatively supports the Fisher-Jeffreys conjecture that, regardless of the statistical framework in which they operate, careful analysts will often come to similar conclusions.
To read the article, click here.

You must be logged in to post a comment.