[This blog is based on the article “ Replication studies in economics—How many and which papers are chosen for replication, and why?” by Frank Mueller-Langer, Benedikt Fecher, Dietmar Harhoff, and Gert Wagner, published in the journal Research Policy]
Academia is facing a quality challenge: The global scientific output doubles every nine years while the number of retractions and instances of misconduct is increasing. In this regard, replication studies can be seen as important post-publication quality checks in addition to the established pre-publication peer review process. It is for this reason that replicability is considered a hallmark of good scientific practice. In our recent research paper, we explore how often replication studies are published in empirical economics and what types of journal articles are replicated.
We find that between 1974 and 2014, 0.1% of publications in the top 50 economics journals were replication studies. We provide empirical support for the hypotheses that higher-impact articles and articles by authors from leading institutions are more likely to be replicated, whereas the replication probability is lower for articles that appeared in top 5 economics journals. Our analysis also suggests that mandatory data disclosure policies may have a positive effect on the incidence of replication. The article can be found here (published under a Creative Commons license).
Scientific research plays an important role in the advancement of technologies and the fostering of economic growth. Hence, the production of thorough and reliable scientific results is crucial from a social welfare and science policy perspective. However, in times of increasing retractions and frequent instances of inadvertent errors, misconduct or scientific fraud, scientific quality assurance mechanisms are subject to a high level of scrutiny.
Issues regarding the replicability of scientific research have been reported in multiple scientific fields, most notably in psychology. A report by the Open Science Collaboration from 2015 estimated the reproducibility of 100 studies in psychological science from three high-ranking psychology journals. Overall, only 36% of the replications yielded statistically significant effects compared to 97% of the original studies that had statistically significant results.
However, similar issues have been reported from other fields. For example, Camerer and colleagues attempted to replicate 18 studies published in two top economic journals—the American Economic Review and the Quarterly Journal of Economics—between 2011 and 2014 and were able to find a significant effect in the same direction as proposed by the original research in only 11 out of 18 replications (61%).
Considering the impact that economic research has on society, for example in a field like evidence-based policy making, there is a particular need to explore and understand the drivers of replication studies in economics in order to design favorable boundary conditions for replication practice.
We explore formal, i.e., published, replication studies in economics by examining which and how many published papers are selected for replication and what factors drive replication in these instances. To this extent, we use metadata about all articles published in the top 50 economics journals between 1974 and 2014. While there are also informal replication studies that are not published in scientific journals (especially replications conducted in teaching or published as working papers) and an increasing number of other forms of post-publication review (e.g., discussions on websites such as PubPeer), these are not covered with our approach.
We find that between 1974 and 2014 0.1% of publications in the top 50 economics journals were replication studies. We find evidence that replication is a matter of impact: higher-impact articles and articles by authors from leading institutions are more likely to be replicated, whereas the replication probability is lower for articles that appeared in top 5 economics journals. Our analysis also suggests that mandatory data disclosure policies may have a positive effect on the incidence of replication.
Based on our findings, we argue that replication efforts could be incentivized by reducing the cost of replication, for example by promoting data disclosure. Our results further suggest that the decision to conduct a replication study is partly driven by the replicator’s reputation considerations. Arguably, the low number of replication studies being conducted could potentially increase if replication studies received more formal recognition (for instance, through publication in [high-impact] journals), specific funding, (for instance, for the replication of articles with a high impact on public policy), or awards. Since replication is, at least partly, driven by reputational rewards, it may be a viable strategy to document and reward formal as well as informal replication practices.
* DISCLAIMER: The views expressed are purely those of the authors and may not in any circumstances be regarded as stating an official position of the European Commission.
Dr. Frank Müller-Langer is Affiliated Researcher at the Max Planck Institute for Innovation and Competition (MPI-IC) and Research Fellow at European Commission, Joint Research Centre, Directorate Growth & Innovation, Digital Economy Unit. Dr. Benedikt Fecher is Head of the “Learning, Knowledge, Innovation” research programme at the Alexander von Humboldt Institute for Internet and Society and co-editor of the blog journal Elephant in the Lab. Prof. Dietmar Harhoff, Ph.D., is Director at MPI-IC and Head of the MPI-IC Innovation and Entrepreneurship Research Group. Prof. Dr. Gert G. Wagner is Research Associate at the Alexander von Humboldt Institute for Internet and Society, Max Planck Fellow at the MPI for Human Development (Berlin) and Senior Research Fellow at the German Socio-Economic Panel Study (SOEP). Correspondence regarding this blog can be directed to Dr. Müller-Langer at frank.mueller-langer@ip.mpg.de.
[From the blog “Accountable replications at Royal Society Open Science: A model for scientific publishing” by Sanjay Srivastava, published at the blogsite, The Hardest Science]
“I was excited to read this morning that the journal Royal Society Open Science has announced a new replication policy … In the new policy, RSOS is committing to publishing any technically sound replication of any study it has published, regardless of the result, and providing a clear workflow for how it will handle such studies.”
“What makes the RSOS policy stand out? Accountability means tying your hands – you do not get to dodge it when it will sting or make you look bad. Under the RSOS policy, editors will still judge the technical faithfulness of replication studies. But they cannot avoid publishing replications on the basis of perceived importance or other subjective factors.”
“Rather, whatever determination the journal originally made about those subjective questions at the time of the initial publication is applied to the replication. Making this a firm commitment, and having it spelled out in a transparent written policy, means that the scientific community knows where the journal stands and can easily see if the journal is sticking to its commitment. Making it a written policy (not just a practice) also means it is more likely to survive past the tenure of the current editors.”
“Other journals should now follow suit. Just as readers would trust a news source more if they are transparent about corrections — and less if they leave it to other media to fix their mistakes — readers should have more trust in journals that view replications of things they’ve published as their responsibility, rather than leaving them to other (often implicitly “lesser”) journals. Adopting the RSOS policy, or one like it, will be way for journals to raise the credibility of the work that they publish while they make scientific publishing more rigorous and transparent.”
Replication studies are often regarded as the means to scrutinize scientific claims of prior studies. They are also at the origin of the scientific debate on what has been labeled “replication crisis.” The fact that the results of many studies cannot be “replicated” in subsequent investigations is seen as casting serious doubts on the quality of empirical research. Unfortunately, the interpretation of replication studies is itself plagued by two intimately linked problems: first, the conceptual background of different types of replication often remains unclear. Second, inductive inference often follows the rationale of conventional significance testing with its misleading dichotomization of results as being either “significant” (positive) or “not significant” (negative). A poor understanding of inductive inference, in general, and the p-value, in particular, will cause inferential errors in all studies, be they initial ones or replication studies.
Amalgamating taxonomic proposals from various sources, we believe that it is useful to distinguish three types of replication studies:
1. Pure replication is the most trivial of all replication exercises. It denotes a subsequent “study” that is limited to verifying computational correctness. It therefore uses the same data (sample) and the same statistical model as the initial study.
2. Statistical replication (or reproduction) applies the same statistical model as used in the initial study to another random sample of the same population. It is concerned with the random sampling error and statistical inference (generalization from a random sample to its population). Statistical replication is the very concept upon which frequentist statistics and therefore the p-value are based.
3. Scientific replication comprises two types of robustness checks: (i) The first one uses a different statistical model to reanalyze the same sample as the initial study (and sometimes also another random sample of the same population). (ii) The other one extends the perspective beyond the initial population and uses the same statistical model for analyzing a sample from a different population.
Statistical replication is probably the most immediate and most frequent association evoked by the term “replication crisis.” It is also the focus of this blog in which we illustrate that re-finding or not re-finding “statistical significance” in statistical replication studies does not tell us whether we fail to replicate a prior scientific claim or not.
In the wake of the 2016 ASA-statement on p-values, many economists realized that p-values and dichotomous significance declarations do not provide a clear rationale for statistical inference. Nonetheless, many economists seem still to be reluctant to renounce dichotomous yes/no interpretations; and even those who realize that the p-value is but a graded measure of the strength of evidence against the null are often not fully aware that an informed inferential interpretation of the p-value requires considering its sample-to-sample variability.
We use two simulations to illustrate how misleading it is to neglect the p-value’s sample-to-sample variability and to evaluate replication results based on the positive/negative dichotomy. In each simulation, we generated 10,000 random samples (statistical replications) based on the linear “reality” y = 1 + βx + e, with β = 0.2. The two realities differ in their error terms: e~N(0;3), and e~N(0;5). Sample size is n = 50, with x varying from 0.5 to 25 in equal steps of 0.5. For both the σ = 3 and σ = 5 cases, we ran OLS-regressions for each of the 10,000 replications, which we then ordered from the smallest to the largest p-value.
Table 1 shows selected p-values and their cumulative distribution F(p) together with the associated coefficient estimates b and standard error estimates s.e. (and their corresponding Z scores under the null).The last column displays the power estimates based on the naïve assumption that the coefficient b and the standard error s.e. that we happened to estimate in the respective sample were true.
Table 1: p-values and associated coefficients and power estimates for five out of 10,000 samples (n = 50 each)†

Our simulations illustrate one of the most essential features of statistical estimation procedures, namely that our best unbiased estimators estimate correctly on average. We would therefore need all estimates from frequent replications – irrespective of their p-values and their being large or small – to obtain a good idea of the population effect size. While this fact should be generally known, it seems that many researchers, cajoled by statistical significance language, have lost sight of it. Unfortunately, this cognitive blindness does not seem to stop short of those who, insinuating that replication implies a reproduction of statistical significance, lament that many scientific findings cannot be replicated. Rather, one should realize that each well-done replication adds an additional piece of knowledge. The very dichotomy of the question whether a finding can be replicated or not, is therefore grossly misleading.
Contradicting many neat, plausible, and wrong conventional beliefs, the following messages can be learned from our simulation-based statistical replication exercise:
1. While conventional notation abstains from advertising that the p-value is but a summary statistic of a noisy random sample, the p-value’s variability over statistical replications can be of considerable magnitude. This is paralleled by the variability of estimated coefficients. We may easily find a large coefficient in one random sample and a small one in another.
2. Besides a single study’s p-value, its variability –and, in dichotomous significance testing, the statistical power (i.e., the zeroth order lower partial moment of the p-value distribution at 0.05) – determines the repeatability in statistical replication studies. One needs an assumption regarding the true effect size to assess the p-value’s variability. Unfortunately, economists often lack information regarding the effect size prior to their own study.
3. If we rashly claimed a coefficient estimated in a single study to be true, we would not have to be surprised at all if it cannot be “replicated” in terms of re-finding statistical significance. For example, if an effect size and standard error estimate associated with a p-value of 0.05 were real, we would necessarily have a mere 50% probability (statistical power) of finding a statistically significant effect in replications in a one-sided test.
4. Low p-values do not indicate results that are more trustworthy than others. Under reasonable sample sizes and population effect sizes, it is the abnormally large sample effect sizes that produce “highly significant” p-values. Consequently, even in the case of a highly significant result, we cannot make a direct inference regarding the true effect. And by averaging over “significant” replications only, we would necessarily overestimate the effect size because we would right-truncate the distribution of the p-value which, in turn, implies a left-truncation of the distribution of the coefficient over replications.
5. In a single study, we have no way of identifying the p-value below which (above which) we overestimate (underestimate) the effect size. In the σ = 3 case, a p-value of 0.001 was associated with a coefficient estimate of 0.174 (underestimation). In the σ = 5 case, it was linked to a coefficient estimate of 0.304 (overestimation).
6. Assessing the replicability (trustworthiness) of a finding by contrasting the tallies of “positive” and “negative” results in replication studies has long been deplored as a serious fallacy (“vote counting”) in meta-analysis. Proper meta-analysis shows that finding non-significant but same-sign effects in a large number of replication studies may represent overwhelming evidence for an effect. Immediate intuition for this is provided when looking at confidence intervals instead of p-values. Nonetheless, vote counting seems frequently to cause biased perceptions of what is a “replication failure.”
Prof. Norbert Hirschauer, Dr. Sven Grüner, and Prof. Oliver Mußhoff are agricultural economists in Halle (Saale) and Göttingen, Germany. Prof. Claudia Becker is an economic statistician in Halle (Saale). The authors are interested in connecting with economists who have an interest to further concrete steps that help prevent inferential errors associated with conventional significance declaration in econometric studies. Correspondence regarding this blog should be directed to Prof. Hischauer at norbert.hirschauer@landw.uni-halle.de.
[From the article “Data Access, Transparency, and Replication: New Insights from the Political Behavior Literature” by Daniel Stockemer, Sebastian Koehler, and Tobias Lentz, in the October issue of PS: Political Science & Politics]
“How many authors of articles published in journal with no mandatory data-access policy make their dataset and analytical code publicly available? If they do, how many times can we replicate the results? If we can replicate them, do we obtain the same results as reported in the respective article?”
“We answer these questions based on all quantitative articles published in 2015 in three behavioral journals—Electoral Studies, Party Politics, and Journal of Elections, Public Opinion & Parties—none of which has any binding data-access or replication policy as of 2015. We found that few researchers make their data accessible online and only slightly more than half of contacted authors sent their data on request. Our results further indicate that for those who make their data available, the replication confirms the results (other than minor differences) reported in the initial article in roughly 70% of cases.”
“However, more concerning, we found that in 5% of articles, the replication results are fundamentally different from those presented in the article. Moreover, in 25% of cases, replication is impossible due to poor organization of the data and/or code.”
To read more, click here. (NOTE: article is behind a paywall.)
[From the abstract of the working paper, “US Courts of Appeal cases frequently misinterpret p-values and statistical significance: An empirical study”, by Adrian Barnett and Steve Goodman, posted at Open Science Framework]
“We examine how p-values and statistical significance have been interpreted in US Courts of Appeal cases from 2007 to 2017. The two most common errors were: 1) Assuming a “non-significant” p-value meant there was no important difference and the evidence could be discarded, and 2) Assuming a “significant” p-value meant the difference was important, with no discussion of context or practical significance. The estimated mean probability of a correct interpretation was 0.21 with a 95% credible interval of 0.11 to 0.31.”
In a recent editorial in Management Review Quarterly, the journal invited replications, and put forth the following “Seven Principles of Effective Replication Studies”:
#1. “Understand that replication is not reproduction”
#2. “Aim to replicate published studies that are relevant”
#3. “Try to replicate in a way that potentially enhances the generalizability of the original study”
#4. “Do not compromise on the quality of data and measures”
#5. “Nonsignificant findings are publishable but need explanation”
#6. “Extensions are possible but not necessary”
#7. “Choose an appropriate format based on the replication approach”
We have to admit that #5 caught our eye. Here is the explanation the editors gave:
“…nonsignificant results or ‘failed’ replications can be extremely important to further theory development. However, they need more information and explanation than ‘successful’ replications. Replication studies should account for this and include detailed comparison tables of the original and replicated results and an elaborate discussion of the differences and similarities between the studies. Authors need to make an effort to explain deviant findings. The differences might be due to different contextual environments from where the sample is drawn; the use of different, more appropriate measures; different statistical methods or simply a result of frequentist null-hypothesis testing where, by definition, false positives are possible (Kerr, 1998). In any case, authors should comment on these possibilities and take a clear stand.”
Note that a replicating author who can’t explain why their replication did not reproduce the original study’s results is given the following lifeline: “The differences might be due to… simply a result of frequentist null-hypothesis testing where, by definition, false positives are possible.”
Is it reasonable that nonsignificant results in replications — and we acknowledge that the fact it is a replication is important — be held to a higher standard of justification than significant results?
We think so, but we wonder if it really will be sufficient for MRQ for a replicating author to “explain” their nonsignificant results by claiming the original study was a 5%, rare result of samping error.
And we wonder what others think.
To read the full editorial, click here.
[From the article “More and more scientists are preregistering their studies. Should you?” by Kai Kupferschmidt, published in Science]
“…Preregistration, in its simplest form, is a one-page document answering basic questions such as: What question will be studied? What is the hypothesis? What data will be collected, and how will they be analyzed? In its most rigorous form, a “registered report,” researchers write an entire paper, minus the results and discussion, and submit it for peer review at a journal, which decides whether to accept it in principle. After the work is completed, reviewers simply check whether the researchers stuck to their own recipe; if so, the paper is published, regardless of what the data show.”
“…Several databases today host preregistrations. The Open Science Framework, run by COS, is the largest one; it has received 18,000 preregistrations since its launch in 2012, and the number is roughly doubling every year. The neuroscience journal Cortex, where Chambers is an editor, became the first journal to offer registered reports in 2013; it has accepted 64 so far, and has published results for 12. More than 120 other journals now offer registered reports, in fields as diverse as cancer research, political science, and ecology.
“…Still, the model is not attractive to everyone. Many journals are afraid of having to publish negative results, Chambers says. And some researchers may not want to commit to publishing whatever they find, regardless of whether it supports a hypothesis.”
“….There are other drawbacks…”
“…It’s not easy to tell how real preregistration’s potential benefits and drawbacks are. Anne Scheel of the Eindhoven University of Technology in the Netherlands, for instance, recently set out to answer a seemingly simple question: Do registered reports lead to more negative results being published? “I’m quite shocked how hard it is,” says Scheel.”
“…For preregistration to be a success, the protocols need to be short, simple to write, and easy to read, Simmons says. That’s why in 2015 he, Nelson, and Simonsohn launched a website, aspredicted.org, that gives researchers a simple template for generating a preregistration.”
[From the abstract of the forthcoming paper, “Replication studies in economics—How many and which papers are chosen for replication, and why?” by Frank Mueller-Langer, Benedikt Fecher, Dietmar Harhoff, and Gert G. Wagner, forthcoming in the journal, Research Policy]
“We investigate how often replication studies are published in empirical economics and what types of journal articles are replicated. We find that between 1974 and 2014 0.1% of publications in the top 50 economics journals were replication studies. We consider the results of published formal replication studies (whether they are negating or reinforcing) and their extent: Narrow replication studies are typically devoted to mere replication of prior work, while scientific replication studies provide a broader analysis. We find evidence that higher-impact articles and articles by authors from leading institutions are more likely to be replicated, whereas the replication probability is lower for articles that appeared in top 5 economics journals. Our analysis also suggests that mandatory data disclosure policies may have a positive effect on the incidence of replication.”
To access the article, click here (but note that it is behind a paywall).
[From the article “The changing forms and expectations of peer review” by Serge Horbach and Willem Halffman, published in Research Integrity and Peer Review, 2018, 3:8]
This is a wonderful article that provides a comprehensive discussion of peer review in the context of scientific quality and integrity. Here are some highlights from the article.
– Provides context for arguments around the role of peer review in ensuring scientific quality/integrity. This includes references from those arguing that it performs that function adequately, to others that argue it fails miserably.
– It discusses the historical evolution of peer-review, arguing that it did not become a mainstream journal practice until after the Second World War.
– Explains how the desire to ensure fairness and objectivity led to single-blind, double-blind, and triple-blind reviewing (where even the handling editor does not know the identify of the author). See table below:
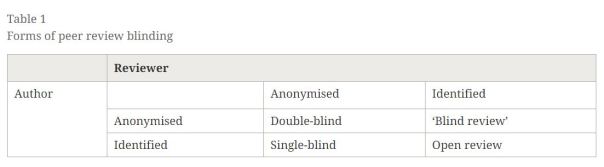
– Discusses the evidence for bias (particularly gender and institutional-affiliation bias) in peer review.
– It is interesting that the same concern for reviewer bias has led to diametrically opposite forms of peer review: double-blind peer review and open peer review.
– With the advent of extra-journal publication outlets, such as pre-print archives, there has been discussion that peer review should serve less the role of quality assurance, and more the goal of providing context and connection to existing literature.
– Makes the argument that one of the motivations behind “registered reports”, where journals decide to publish a paper based on its research design — independently of its results — is that this would provide a greater incentive to undertake replications.
– Related to the replication crisis and publication bias, peer review at some journals has moved to re-focussing assessment away from novelty and statistical significance, and towards importance of the research question and soundness of research design.
– Another development in peer review has been the creation of software to assist journals and reviewers in identifying plagiarism and to detect statistical errors and irregularities.
– Artificial intelligence is being looked to in order to address the burdensome task of reviewing ever-increasing numbers of scientific manuscripts. The following quote offers an intriguing look at a possible, AI future of peer review: “Chedwich deVoss, the director of StatReviewer, even claims: ‘In the not-too-distant future, these budding technologies will blossom into extremely powerful tools that will make many of the things we struggle with today seem trivial. In the future, software will be able to complete subject-oriented review of manuscripts. […] this would enable a fully automated publishing process – including the decision to publish.’”
– Given the increasingly important role that statistics play in scientific research, there is an incipient movement for journals to employ statistical experts to review manuscripts, including the contracting of reviewing to commercial providers.
– Post-publication review, such as that offered by PubPeer, has also expanded peer review outside the decision to publish research.
– Another movement in peer review has been to introduce interactive discussion between the reviewer, the author, and external “peers” before the editor makes their decision. Though this is not mentioned in the article, this is the model of peer review in place at the journal Economics: The Open Access, Open Assessment E-journal.
– The article concludes the discussion by noting that as academic publishing has become big business, with high submission and subscription fees charged to authors and readers, there is an increasing sense that academic publishers should be held responsible for the quality of their product. This has — and will have even more so in the future — consequences for peer review.
To read the full article, click here.
The Journal of Experimental Political Science (JEPS) just announced that is opening up a new kind of manuscript submission based on preregistered reports. Here is how they describe it:
“A preregistered report is like any other research paper in many respects. It offers a specific research question, summarizes the scholarly conversation in which the question is embedded, explicates the theoretically grounded hypotheses that offer a partial answer to the research question, and details the research design for testing the proposed hypotheses. It differs from most research papers in that a preregistered report stops here. The researchers do not take the next step of reporting results from the data they collected. Instead, they preregister the design in a third-party archive, such as the Open Science Framework, before collecting data.”
“At JEPS, we will send out preregistered reports for a review, just like other manuscripts, but we will ask reviewers to focus on whether the research question, theory, and design are sound. If the researchers carried out the proposed research a) would they make a contribution and b) would their proposed test do the job? If the answer is yes (potentially after a round of revisions), we will conditionally accept the paper and give the researchers a reasonable amount of time to conduct the study, write up the results, and resubmit the revised fully-fledged paper. At this point, we will seek the reviewers’ advice one more time and ask, “Did the researchers do what they said they were going to do?” If the answer is “yes,” we will publish the paper. It doesn’t matter if the research produced unexpected results, null findings, or inconsistent findings. In fact, we will specifically instruct reviewers at the second stage to ignore statistical significance and whether they support the authors’ hypotheses when evaluating the paper.”
This follows the recent announcement at another Cambridge University Press journal, the Japanese Journal of Political Science, that it is introducing results-free peer review (RFPR).
To read more about the JEPS announcement, click here.
To read previous posts about RFPR at TRN, click here, here, here, and here.

You must be logged in to post a comment.