The Replication Network
Furthering the Practice of Replication in Economics
Invitation to Participate in a Survey on How Results Influence Journal Publication
Researchers at Cardiff University (Chris Chambers, Ben Meghreblian) are seeking participants in a survey exploring the extent to which the results of a research study influence publication in the peer-reviewed literature.
The study takes about 5-10 minutes and is part of a research project being undertaken across several UK universities. The broad aim of this research is to build a better picture of factors influencing peer-reviewed publication across different academic fields.
Participation is anonymous.
To go to the survey, click on the link below:
https://cardiffunipsych.eu.qualtrics.com/jfe/form/SV_6g2hWJNtNt9LhjM
REED: Meta-Analysis and Univariate Regression Tests for Publication Bias – Seriously?
[This blog first appeared at the MAER-Net Blog under the title “Univariate Regression Tests for Publication Bias: Why Do We Do Them?”, see here]
The FAT-PET Framework: A standard meta-analysis article goes something like this (see, for example, Knaisch and Pöschel, 2023):
PART I: Introduction
PART 2: Literature Review
PART 3: Description of Data
PART 4: Testing for Publication Bias
PART 5: Explaining Heterogeneity
PART 6: Best Practice Estimate
PART 7: Conclusion
(1) Estimated Effect = β0 + β1 SE + ε,
where SE is the standard error of the estimated effect. β1 is used to test for the existence of publication bias. Statistical significance is interpreted as evidence of publication bias.
In economics, this is called the Funnel Asymmetry Test, or “FAT”. Elsewhere, it is more widely known as Egger’s regression test.
β0 provides an estimate of the overall mean effect after adjusting for publication bias. This is commonly referred to as “Effect Beyond Bias” and is nothing more than a prediction of the estimated effect when SE = 0.
The test of β0=0 is known as the Precision Effect Test (“PET”). (Hence “FAT-PET”.) If β0 is significant in Equation (1), Stanley & Doucouliagos (2012) recommend that SE be replaced by SE^2 and the associated estimate of the constant term be taken as the preferred “Effect Beyond Bias”. This is what turns FAT-PET into FAT-PET-PEESE.
The Univariate FAT-PET. To set the context, suppose a colleague of yours were to ask you to comment on a draft of a paper they had written estimating the effect of education on wages. They have access to a unique dataset with extensive information on worker and job/occupation characteristics. Yet their paper only reports a simple regression of wages on education.
Surely you would tell your colleague that they will never get their paper published. They need to hold the influence of other variables constant. They need to do a more extensive regression analysis before concluding anything about the returns to education.
Yet when it comes to testing for publication bias and estimating the overall mean effect, we give primacy to a simple regression of effect size on standard error — a practice we would typically regard as deficient in other applications.
Best practice is univariate + multivariate FAT-PET, right? A standard response to this criticism is that “best practice” says you should never just estimate a univariate regression. Rather, you should also include the SE/SE^2 variable in a regression specification with other variables that are thought to affect estimated effects. The good news is, at least at first glance, this does indeed appear to be what most meta-analyses in economics do.
I went through the Journal of Economic Surveys (JOES) and found the 20 most recently published meta-analyses. (The list of articles is given at the bottom of this blog.)
Of these, 19 do a univariate, FAT-PET-type regression. Of these nineteen, 17 go on to include a standard error variable in a more fully specified meta-regression. So it looks like good practice is mostly being followed in meta-analyses recently published in JOES. Interestingly, Aiello and Bonannno (2019) skip the univariate FAT-PET and go directly to a meta-regression with multiple explanatory variables.
A problem with the univariate + multivariate FAT-PET approach. One problem with the practice of doing both a univariate and a multivariate FAT-PET is that the multivariate MRA is rarely (never?) included in the section on publication bias. That is, when there is a separate section on publication bias, only the univariate version of the test is reported and used to draw a conclusion about the existence of publication bias.
This can be misleading. Especially when the univariate and multivariate regressions lead to different conclusions. This can occur whenever the SE variable is highly correlated with other study characteristics. In my experience, I have found that this is often the case.
For example, I presented a paper at last year’s MAER-Net on Social Capital and Economic Growth. There were 18 study characteristics in my meta-regression. A regression of SE on the 18 variables produced an R-squared of 53.8%.
Things were no better when I substituted sample size for SE. The respective R-squared was even higher, at 68.2%. (As an aside, substantial correlation of sample size with study characteristics is a problem when researchers use sample size as an IV for the standard error variable.) We should not be surprised when the multivariate FAT-PET produces a different conclusion than the univariate FAT-PET in these cases.
Two examples from my sample of 20 are Churchill et al. (2022) and Georgia et al. (2022). The respective FAT coefficients are reported in the table below, with standard errors in parentheses. In both cases, the univariate FAT estimates indicated the existence of publication bias, while the multivariate estimates did not.

In fact, the record regarding good practice is not as good as it seems. It is true that most meta-analyses in my sample estimated a meta-regression including both the SE variable and other study characteristics. However, not all used the multivariate meta-regression to test for publication bias. There are studies in my sample that estimate a univariate FAT-PET, conclude there is evidence of publication bias, later report a multivariate meta-regression with an insignificant SE variable, but never acknowledge this as evidence against publication bias.
The univariate FAT-PET can be misleading about the existence of publication bias. Why report it at all? Why not do like Aiello and Bonannno (2019) and go straight to the multivariate FAT-PET?
It seems to me that estimating the influence of publication bias is conceptually no different than estimating the returns to education. In both cases, one needs to control for other factors.
Another problem: Effect beyond bias. If omitted variable bias affects β1 in Equation (1), then it also affects estimates of β0. If the SE coefficient is positively biased, “Effect beyond bias” will be underestimated (assuming an overall positive effect). If the SE coefficient is negatively biased, it will be overestimated. Obtaining an unbiased estimate of the effect of publication bias is essential for estimating “Effect beyond bias”.
If good practice calls for estimating a multivariate FAT-PET version of Equation (1), good practice should also include a corresponding estimate of the overall mean effect. That is, there should be a multivariate analogue to “Effect beyond bias” that corresponds to the univariate “Effect beyond bias”.
This is straightforward to do when the multivariate FAT-PET is estimated using OLS. When using a weighted estimator such as FE or RE, there are some nuanced issues, though these are not difficult to address. Yet this is rarely, if ever, done. None of the 20, most recently published meta-analyses in JOES calculate a multivariate “Effect beyond bias”.
To be fair, many meta-analyses report one or more “best practice” estimates. In my sample, 11 of the 20 meta-analyses predict the estimated effect size using “best study” characteristics. For example, best studies might include those based on randomized control studies, or that correct for endogeneity. Typically, they assume that SE = 0; i.e., no publication bias.
“Best practice” estimates are good. But they are not the same thing as a multivariate analogue to the univariate FAT-PET regression. They predict the estimated effect size for a particular kind of study. They do not provide an estimate of the overall mean effect for all studies.
In the absence of a multivariate “Effect beyond bias”, there is nothing to balance the “Effect beyond bias” estimates from the univariate regression. In that case, the univariate estimates will be given undue weight.
In conclusion, I have two recommendations:
1) Meta-analysts should always include a multivariate FAT in the section of their paper that is devoted to testing for publication bias.
2) Meta-analysts should always include a multivariate “Effect beyond bias” alongside the univariate “Effect beyond bias” estimate.
I am keen to hear what other meta-analysts think.
NOTE: Bob Reed is Professor of Economics and the Director of UCMeta at the University of Canterbury. He can be reached at bob.reed@canterbury.ac.nz. Special thanks go to Weilun Wu for his research assistance for this project.
REFERENCES
Aiello, F., & Bonanno, G. (2019). Explaining differences in efficiency: A meta‐study on local government literature. Journal of Economic Surveys, 33(3), 999-1027.
de Batz, L., & Kočenda, E. (2023). Financial crime and punishment: A meta-analysis. Journal of Economic Surveys, https://doi.org/10.1111/joes.12580
Brada, J. C., Drabek, Z., & Iwasaki, I. (2021). Does investor protection increase foreign direct investment? A meta‐analysis. Journal of Economic Surveys, 35(1), 34-70.
Chletsos, M., & Sintos, A. (2023). Financial development and income inequality: A meta‐analysis. Journal of Economic Surveys, 37(4), 1090-1119.
Churchill, S., Luong, H. M., & Ugur, M. (2022). Does intellectual property protection deliver economic benefits? A multi‐outcome meta‐regression analysis of the evidence. Journal of Economic Surveys, 36(5), 1477-1509.
Donovan, S., de Graaff, T., de Groot, H. L., & Koopmans, C. C. (2022). Unraveling urban advantages—A meta‐analysis of agglomeration economies. Journal of Economic Surveys. https://onlinelibrary.wiley.com/doi/10.1111/joes.12543
Ferreira‐Lopes, A., Linhares, P., Martins, L. F., & Sequeira, T. N. (2022). Quantitative easing and economic growth in Japan: A meta‐analysis. Journal of Economic Surveys, 36(1), 235-268.
Filomena, M., & Picchio, M. (2023). Retirement and health outcomes in a meta‐analytical framework. Journal of Economic Surveys. 37(4), 1120–1155
Giorgio, D. P., European Commission, & IZA. (2022). Studying abroad and earnings: A meta‐analysis. Journal of Economic Surveys, 36(4), 1096-1129.
Gregor, J., Melecký, A., & Melecký, M. (2021). Interest rate pass‐through: A meta‐analysis of the literature. Journal of Economic Surveys, 35(1), 141-191.
Hansen, C., Block, J., & Neuenkirch, M. (2020). Family firm performance over the business cycle: a meta‐analysis. Journal of Economic Surveys, 34(3), 476-511.
Hirsch, S., Petersen, T., Koppenberg, M., & Hartmann, M. (2023). CSR and firm profitability: Evidence from a meta‐regression analysis. Journal of Economic Surveys, 37(3), 993-1032.
Hubler, J., Louargant, C., Laroche, P., & Ory, J. N. (2019). How do rating agencies’decisions impact stock markets? A meta‐analysis. Journal of Economic Surveys, 33(4), 1173-1198.
Knaisch, J., & Pöschel, C. (2023). Wage response to corporate income taxes: A meta-regression analysis. Journal of Economic Surveys, 00, 1–25. https://doi.org/10.1111/joes.12557
Kočenda, E., & Iwasaki, I. (2022). Bank survival around the World: A meta‐analytic review. Journal of Economic Surveys, 36(1), 108-156.
Malovaná, S., Hodula, M., Bajzík, J., & Gric, Z. (2023). Bank capital, lending, and regulation: A meta-analysis. Journal of Economic Surveys, 00, 1–29. https://doi.org/10.1111/joes.12560
Polak, P. (2019). the euro’s trade effect: A meta‐analysis. Journal of Economic Surveys, 33(1), 101-124.
Stanley, T. D., Doucouliagos, H., & Steel, P. (2018). Does ICT generate economic growth? A meta‐regression analysis. Journal of Economic Surveys, 32(3), 705-726.
Vooren, M., Haelermans, C., Groot, W., & Maassen van den Brink, H. (2019). The effectiveness of active labor market policies: a meta‐analysis. Journal of Economic Surveys, 33(1), 125-149.
Xue, X., Cheng, M., & Zhang, W. (2021). Does education really improve health? A meta‐analysis. Journal of Economic Surveys, 35(1), 71-105.
REED: More on Self-Correcting Science and Replications: A Critical Review
NOTE: This is a another long blog. Sorry about that! TL;DR: I provide a common framework for evaluating 5 recent papers and critically compare them. All of the papers have shortcomings. I argue that the view that the psychology papers represent a kind of “gold standard” is not justified. There is a lot left to learn on this subject.
In a previous post, I summarized 5 recent papers that attempt to estimate the causal effect of a negative replication on the original study’s citations. In this blog, I want to look a little more closely at how each of the papers attempted to do that.
Because the three psychology papers utilized replications that were “randomly” selected (more on this below), there is the presumption that their estimates are more reliable. I want to challenge that view. In addition, I want to reiterate some concerns that have been raised by others that I think have not been fully appreciated.
I also think it is insightful to provide a common framework for comparing and assessing the 5 papers. As I am a co-author on one of those papers, I will attempt to avoid letting my bias affect my judgment, but caveat lector!
DID and the Importance of the Parallel Trends Assumption
The three psychology papers — Serra-Garcia & Gneezy (2021), Schafmeister (2021), and von Hippel (2022) – all employ a Difference-in-Difference (DID) identification strategy that relies on the assumption of parallel trends (PT). (Von Hippel also employs an alternative strategy that does not assume PT, but more on that below.) Before looking at the papers more closely, it is good to refresh ourselves on the importance of the PT assumption in DID estimation.
FIGURE 1 below shows trends in citations for studies that had failed replications (black line) and studies that had successful replications (blue line). The treatment is revelation of the outcome of the respective replications (failed replication, successful replication), and the start time of the treatment is the date that the replication was published, T*.
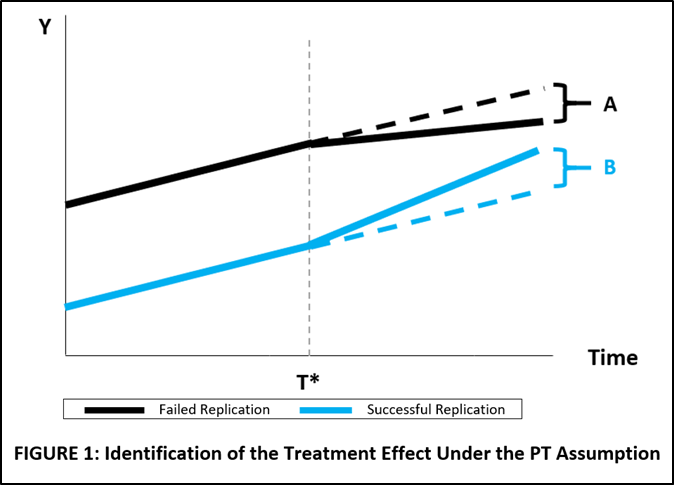
A researcher wants to estimate the citation effect of failed versus successful replications. The solid lines represent the observed citation trends of the original studies before and after the treatment. For the counterfactuals, the researcher assumes that the pre-treatment trends would have continued had the studies not been replicated. This is represented by the black and blue dotted lines, respectively.
In the figure, failed replications result in fewer citations per year, represented by the flatter slope of the black line. The associated treatment effect of failed replications is the difference in slopes between the actual trend line and the counterfactual trend line, given by A, where A < 0.
Successful replications result in more citations per year, represented by the steeper slope of the blue line. The treatment effect for positive replications is again the difference in slopes, given by B, where B > 0.
The estimate of the total citation effect of a failed replication versus a successful replication is given by (A-B).
The importance of the PT assumption is illustrated in FIGURE 2. Here, originals with failed replications have a steeper trend in the pre-treatment period than originals with successful replications.
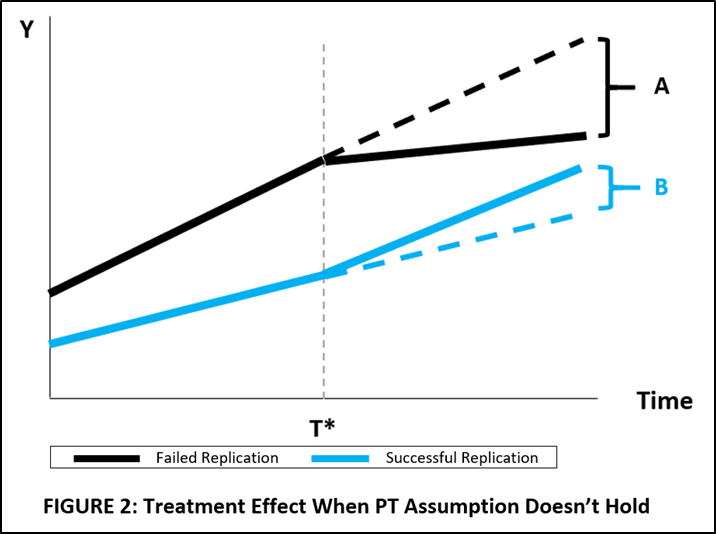
If the researcher were to mistakenly assume that they had the same trend, say use the average of the pre-treatment trends, they would underestimate both A and B, and thus underestimate the effect of a failed replication versus a successful replication.
This is illustrated below. The red line averages the pre-treatment trends of studies with failed replications and studies with successful replications.
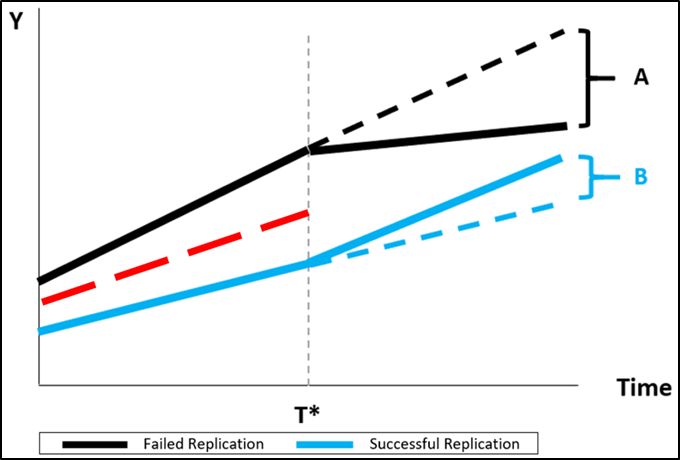
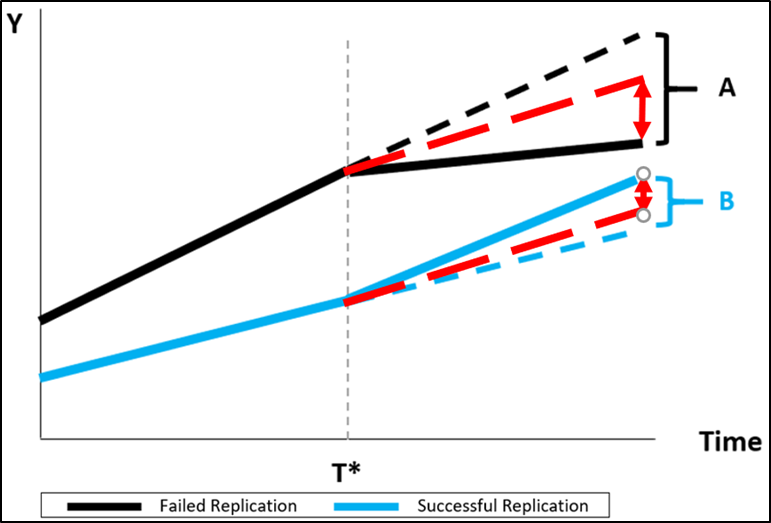
When the averaged, common trend is used to establish the respective counterfactuals, both |A| and |B| are underestimated, so that the total citation effect of a failed replication versus a successful replication is underestimated. This is illustrated by the dotted red lines below.
How the PT Assumption is Incorporated in Regression Specifications
Now I show how the three studies incorporate the PT assumption in their regressions.
Serra-Garcia & Gneezy:
(1) Yit = β0i + β1Successit + β2AfterReplicationit+ β3Success×AfterReplicationit+ Year Fixed Effects + Control Variables
Schafmeister:
(2) Yit = β0 + β1Successfulit + β2Failedit+ Study Fixed Effects + Year Fixed Effects + Control Variables
Von Hippel:
(3) Yit = β0 + β1AfterFailureit + Study Fixed Effects + Year Fixed Effects + Control Variables
In the equations above, Yit represents citations of study i in year t. The estimate of the citation penalty for failed versus successful replications is respectively given by β3 (Equation 1), β2 – β1 (Equation 2), and β1 (Equation 3).
While the three specifications have some differences, all three equations include a common time trend for both failed and successful replications, represented by “Year Fixed Effects”. This imposes the PT assumption on the estimating equations.
What is the Basis for the PT Assumption?
My reading of the respective articles is that each of them depends, explicitly or implicitly, on the research design of the Reproducibility Project: Psychology (RPP) and the related Camerer et al. (2016, 2018) studies to support the assumption of PT.
As discussed in my prior blog, RPP “randomly” selected which experiments to replicate, without regard to whether they thought the replications would be successful. As such, one could argue that there is no reason to expect pre-treatment citation trends to differ, since there was nothing about the original studies that affected the choice to replicate.
However, random selection of experiments does not mean random assignment of outcomes. As was first pointed out to me by Paul von Hippel, just because the choice of articles to replicate was “random” does not mean that the assignment of treatments (failed/successful replications) to citation trends will be random. There could well be features of studies that affect both their likelihood of being successfully replicated and their likelihood of being cited.
In fact, this is exactly the main point of Serra-Garcia & Gneezy’s article “Nonreplicable publications are cited more than replicable ones.” They show that nonreplicable papers were cited more frequently EVEN BEFORE it was demonstrated they were nonreplicable.
Serra-Garcia & Gneezy have an explanation for this: “Existing evidence … shows that experts predict well which papers will be replicated. Given this prediction, why are nonreplicable papers accepted for publication in the first place? A possible answer is that the review team faces a trade-off. When the results are more “interesting,” they apply lower standards regarding their reproducibility.” In other words, “interesting-ness” is a confounder for both pre-treatment citations and replicability.
FIGURE 3 from their paper (reproduced below) supports scepticism about the PT assumption. It shows pre-treatment citation trends for three sets of replicated studies. For two of them “Nature/Science” and “Psychology in rep. markets” (which corresponds to the RPP), the citation trends for original studies with failed replications show substantially higher rates of citation before treatment than those with successful replications. This is a direct violation of the PT assumption.

In personal correspondence about my paper with Tom Coupé (discussed below), one researcher wrote me, “I would be worried about selection bias—which papers were chosen (by others) for replication? [A] ‘trick’ to avoid selection [is] to base [your] study on papers that were replicated systematically (‘ALL experimental papers in journal X for the year Y’).” As should be clear from the above, studies that rely on replications from RPP and the Camerer et al. studies are not beyond criticism on this regard.
But wait, there’s more!
Tom Hardwicke, who has also examined the effect of failed replications on citations (Hardwicke et al., 2021), pointed out to me two other issues. Underlying the citation analyses of the RPP replications is the assumption that once RPP was published, readers were immediately made aware of the non-replicability of the respective studies.
Not so fast. It is not easy to identify the studies that failed replication in RPP. They are not listed in the paper. And they are not listed in the supplementary documentation. To find them, you have to go back to the original RPP spreadsheet that contains their data. Even assuming one made it that far, identifying the studies that failed replication is not so easy. Don’t take my word for it. Check it out yourself here.
Even assuming that one identified which studies failed replication, there is the question of whether the evidence was strong enough to change one’s views about the original study. Etz & Vandekerckhove (2021) concluded that it did not: “Overall, 75% of studies gave qualitatively similar results in terms of the amount of evidence provided. However, the evidence was often weak (i.e., Bayes factor < 10). The majority of the studies (64%) did not provide strong evidence for either the null or the alternative hypothesis in either the original or the replication, and no replication attempts provided strong evidence in favor of the null.”
Where does Ankel-Peters, Fiala, and Neubauer fit within the DID framework?
Before moving on to strategies that do not rely on the PT assumption, it is helpful to place Ankel-Peters, Fiala, and Neubauer (2023) in the context of the analysis above. Their main argument is represented by FIGURE 6 from their paper, reproduced below. The black line is the citations trend of original papers whose replications failed.
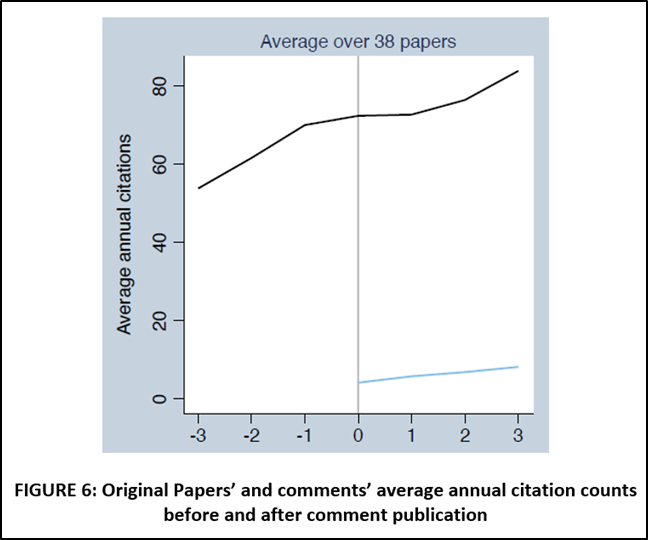
While they do not report this in their paper, my own analysis of AER “Comments” is that the AER rarely, very rarely, publishes successful replications. Given that almost all the replications in their dataset are failed replication, their paper can be understood as estimating the treatment effect exclusively from the solid black line in FIGURES 1 and 2; i.e., no dotted lines, no blue lines.
No PT Assumption: Approach #1
Of the 5 papers reviewed here, only two provide citation effect estimates without invoking the PT assumption. In addition to the model presented above, von Hippel estimates something he calls the “lagged model”:
(4) ln(YI,t>2015) = β0 + β1 ln(YI,t<2015) + β2 Failurei + β3 ln(YI,t<2015) x Failurei
where YI,t>2015 and YI,t<2015 are the total citations received by original study i in the years before and after the RPP replications were published in 2015. Despite its apparent similarity with a DID, the “treatment variable” in Equation (4) is NOT represented by the interaction term. The treatment effect is given by β2. The interaction term allows the citation trend for original studies with failed replications to have a different “slope” than those with successful replications.
No PT Assumption: Approach #2
Last but not least (there’s my bias slipping in!) is Coupé and Reed (2023). As discussed in the previous blog, they use a matching strategy to join the original studies with studies that have not been replicated but have near identical, pre-treatment citation histories. This identification strategy is easily placed within FIGURE 2.
Consider first original studies with failed replications. Since each of these is matched with control studies with near identical pre-treatment citation histories, one can think of two citation trends that lie on top of each other in the pre-treatment period. Accordingly, the solid black line in FIGURE 2 in the period T < T* now represents citation trends for both the original studies and their matched controls. Once we enter the post-treatment period, the two citation trends diverge.
The solid black line in the period T > T* represents the citation trend for the studies with failed replications after the results of the replication have been published. The dotted black line is the observed citation trend of the matched controls, which serve as the counterfactual for the original studies. The difference in slopes represents the treatment effect of a failed replication.
The same story applies to the studies with successful replications, which are now represented by the blue line in FIGURE 2. Note that the black and blue lines are allowed to have different, pre-treatment slopes. Thus Coupé & Reed’s matching strategies, like von Hippel’s lagged model, avoids imposing the PT assumption.
Coupé and Reed’s approach is not entirely free from potential problems. Because the replications were not selected “randomly”, there is concern that their approach may suffer from sample selection. However, the sample selection is not the obvious one of replicators choosing highly-cited papers that they think will fail because that brings them the most attention. That sample selection is addressed by matching on the pre-treatment citation history.
Rather, the concern is that even after controlling for identical pre-treatment citation histories, there remains some unobserved factor that (i) causes original studies and their matched controls to diverge after a replication has been published and (ii) is spuriously correlated with whether a paper has been successfully replicated. Having acknowledged that possibility, it’s not clear what that unobserved factor could be.
Summary
There is no silver bullet when it comes to identifying the citation effect of failed replications. Criticisms can be levelled against each of the 5 papers. This brings me to my conclusion about the current literature.
First, while all the studies have shortcomings, they collectively provide some insight into the relationship between replications and citations. None are perfect, but I don’t think their flaws are so great as to render their analyses useless. As an aside, because of their flaws, I think there is room for more studies like Hardwicke et al. (2021) that take a case study approach.
Second, while the evidence to date appears to indicate that neither psychology or economics is self-correcting when it comes to failed replications, there is room for more work to be done. This is, after all, an important question.
Comments welcome!
REFERENCES
Ankel-Peters, J., Fiala, N., & Neubauer, F. (2023). Is economics self-correcting? Replications in the American Economic Review. Ruhr Economic Papers, #1005. https://www.rwi-essen.de/fileadmin/user_upload/RWI/Publikationen/Ruhr_Economic_Papers/REP_23_1005.pd
Camerer, C. F., Dreber, A., Forsell, E., Ho, T. H., Huber, J., Johannesson, M., … & Wu, H. (2016). Evaluating replicability of laboratory experiments in economics. Science, 351(6280), 1433-1436.
Camerer, C. F., Dreber, A., Holzmeister, F., Ho, T. H., Huber, J., Johannesson, M., … & Wu, H. (2018). Evaluating the replicability of social science experiments in Nature and Science between 2010 and 2015. Nature Human Behaviour, 2(9), 637-644.
Coupé, T. & Reed, W.R. (2023). Do Replications Play a Self-Correcting Role in Economics? Mimeo, University of Canterbury. https://ideas.repec.org/p/cbt/econwp/22-16.html
Etz, A., & Vandekerckhove, J. (2016). A Bayesian perspective on the reproducibility project: Psychology. PloS One, 11(2), e0149794.
Hardwicke, T. E., Szűcs, D., Thibault, R. T., Crüwell, S., van den Akker, O. R., Nuijten, M. B., & Ioannidis, J. P. (2021). Citation patterns following a strongly contradictory replication result: Four case studies from psychology. Advances in Methods and Practices in Psychological Science, 4(3), 1-14.
Open Science Collaboration (2015). Psychology. Estimating the reproducibility of psychological science. Science, 349(6251), aac4716.
Schafmeister, F. (2021). The effect of replications on citation patterns: Evidence from a large-scale reproducibility project. Psychological Science, 32(10), 1537-1548.
Serra-Garcia, M., & Gneezy, U. (2021). Nonreplicable publications are cited more than replicable ones. Science Advances, 7(21), eabd1705.
von Hippel, P. T. (2022). Is psychological science self-correcting? Citations before and after successful and failed replications. Perspectives on Psychological Science, 17(6), 1556-1565.
FEATURED RESEARCH: 2 Recent Papers on the Role of the Media in Reproducibility
Two recent papers look at the influence of media on replications and retractions.
A paper by Eleonora Alabrese concludes that “media coverage shapes the auto-correcting process of science by reducing the amount of misinformation and increasing punishment for retracted authors.”

[The following are excerpts from the paper]
“…difference-in-differences estimates at the paper level show that retractions harm citations of retracted papers, and media coverage amplifies this effect (on average, media contributes to a ’20-28% further reduction in forward citations). This aggravating effect is present only in hard sciences… in the case of social sciences, there is no additional penalty associated to retracted papers with media attention.”
“Evidence suggests that articles with higher predicted media coverage are less likely to experience a retraction. The interpretation of this result is twofold. On the one hand, the fact that popular articles are retracted less often seems reassuring and could be due to experienced academics answering salient research questions. On the other, it could indicate that “interesting” research articles may be reviewed with a laxer standard.”
To read the paper, click here.
————————————————————————————
Another paper by Wu Youyou, Yang Yang, and Brian Uzzi in PNAS concludes that more media coverage means less reproducibility.

With regard to media coverage, the paper states:
“The media plays a significant role in creating the public’s image of science and democratizing knowledge, but it is often incentivized to report on counterintuitive and eye-catching results. Ideally, the media would have a positive relationship (or a null relationship) with replication success rates in Psychology. Contrary to this ideal, however, we found a negative association between media coverage of a paper and the paper’s likelihood of replication success.”
Other findings are:
“We found that experimental work replicates at significantly lower rates than non-experimental methods for all subfields, and subfields with less experimental work replicate relatively better. This finding is worrisome, given that Psychology’s strong scientific reputation is built, in part, on its proficiency with experiments.”
“…while replicability is positively correlated with researchers’ experience and competence, other proxies of research quality, such as an author’s university prestige and the paper’s citations, showed no association with replicability in Psychology.”
To read the paper, click here.
REED: Is Science Self-Correcting? Evidence from 5 Recent Papers on the Effect of Replications on Citations
NOTE: This is a long blog. TL;DR: I discuss 5 papers and the identification strategies each use in their effort to identify a causal effect of replications on citations.
One of the defining features of science is its ability to self-correct. This means that when new evidence or better explanations emerge, scientific theories and models are modified or even discarded. However, the question remains whether science really works this way. In this blog I review 5 recent papers that attempt to empirically answer this question. All five investigated whether there was a citation penalty from an unsuccessful replication. Although each of the papers utilized multiple approaches, I only report one or a small subset of results as representative of their analyses.
Three of the papers are published and from psychology: Serra-Garcia & Gneezy (2021), Schafmeister (2021), and von Hippel (2022). Two of the papers are from economics and are unpublished: Ankel-Peters, Fiala, & Neubauer (2023) and Coupé & Reed (2023).
All five find no evidence that psychology/economics are self-correcting. However, there are interesting things to learn in how they approached this question and that is what I want to cover in this blog.
The Psychology Studies
The three psychology studies rely heavily on replications from the Reproducibility Project: Psychology (Open Science Collaboration, 2015; henceforth RP:P). In particular, they exploit a unique feature of RP:P = RP:P “randomly” selected studies to replicate.
Specifically, they chose three leading journals in psychology. For each, they opened up to the first issue of 2008 and then selected experiments to replicate that met certain feasibility requirements. They did not choose experiments based on their results. RP:P was only concerned with selecting experiments whose methods could be reproduced with reasonable effort. They continued reading through the journals until they found 100 studies to replicate.
Because of RP:P’s procedure for selecting studies, one can view the outcome of their replications as random events since the decision to replicate an experiment was independent of expectations about whether the replication would be successful.
It is this feature that allows the three psychology studies to model the treatments “successful replication” and “unsuccessful replications” as random assignments. All three studies investigate whether “unsuccessful” replications adversely affect the original studies’ citations. I discuss each of them below.
Serra-Garcia & Gneezy (2021). Serra-Garcia & Gneezy draw replications from three sources, with the primary source being RP:P. The other two studies (“Economics”-Camerer et al., 2016; “Nature/Science”-Camerer et al., 2018) followed similar procedures in selecting experiments to replicate. Their main results are based on 80 replications and are presented in Figure 3 and Table 1 of their paper.
The vertical lines in the three panels of their Figure 3 indicate the year the respective replication results were published. The height of the lines represents the yearly citations for original studies that were successfully replicated (blue) and unsuccessfully replicated (black). If science were self-replicating, one would hope to see that citations for studies that failed to replicate would take a hit and decrease after the failure to replicate became known. Nothing of that sort is obvious from the graphs.

To obtain a quantitative estimate of the treatment effect (=”successful replication”), Serra-Garcia & Gneezy estimate the following specification:
Yit = β0i + β1Successit + β2AfterReplicationit + β3Success×AfterReplicationit + Year Fixed Effects + Control Variables
where:
Dependent variable = Google Scholar cites per year
Number of original studies = 80
Time period = 2010-2019
Estimation Method = Poisson/Random Effects
Control group = No
Their Table 1 reports the results of a difference-in-difference (DID) analysis (see below). The treatment variable is “Replicated x After publication of replication”. The estimated effect says that original studies that are successfully replicated receive approximately 1.2 more citations per year than those that are not. However, the effect is not statistically significant.

It is the random assignment of “successful replication” and “unsuccessful replication” that allow Serra-Garcia & Gneezy (2021) to claim they identify a causal effect. The other two psychology studies follow a similar identification strategy.
Schafmeister (2021). Schafmeister focuses solely on replication studies from RP:P. In particular, he selects 95 experiments that had a single replication and whose original studies produced statistically significant results.
He then constructs a control group of 329 articles taken from adjacent years (2007,2009) of the same three psychology journals used by RP:P. He uses the same criteria that RP:P used to select their replication studies except that these studies are used as controls. This allows him to define three treatments: “successful replication”, “unsuccessful replication”, and “no replication”. Because he uses the same criteria as RP:P in selecting his control group, he is able to claim that all three treatments are randomly assigned.
To obtain a quantitative estimate of the two treatment effects (=”successful replication” and “unsuccessful replication), Schafmeister estimates the following DID specification:
Yit = β0 + β1Successfulit + β2Failedit+ Study Fixed Effects + Year Fixed Effects + Control Variables
where “Successful” and “Failed” are binary variables that indicate that that the replication was successful/failed and that t > 2015, the year the replication result was published; and
Dependent variable = ln(Web of Science cites per year)
Number of original studies = 429 (95 RP:P + 329 controls)
Time period = 2010-2019
Estimation Method = OLS/Fixed Effects
Control group = Yes
Schafmeister’s Table 2 reports the results (see below). Focusing on the baseline results, studies that successfully replicate receive approximately 9% more citations per year (=0.037+0.051) than studies whose replications failed. Unfortunately, Schafmeister did not test whether this difference was statistically significant.

Von Hippel (2022). Similar to Schafmeister, von Hippel draws his replication entirely from RP:P, albeit with a slightly different sample of 98 studies. His Figure 2 provides a look at his main results. There is some evidence that successful replications gain citations relative to unsuccessful replications.
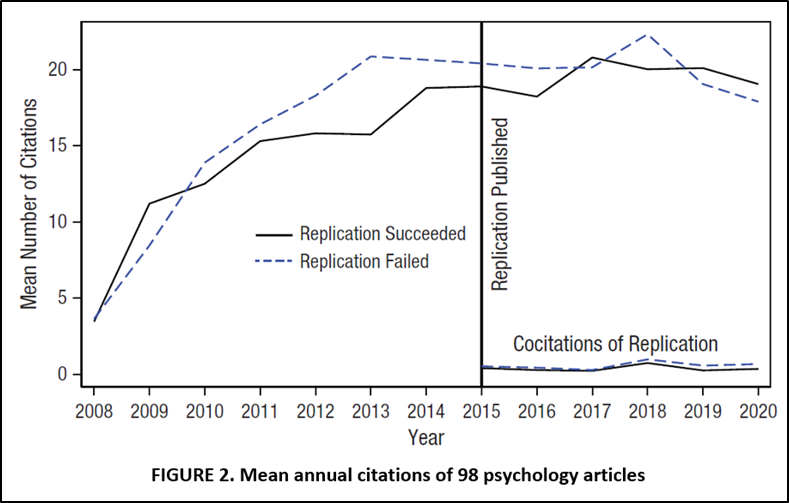
To obtain quantitative estimates of the treatment effect (“unsuccessful replication), von Hippel estimates the following DID specification:
Yit = β0 + β1AfterFailureit + Study Fixed Effects + Year Fixed Effects + Control Variables
where “AfterFailure” takes the value 1 if the original study failed to replicate and the year > 2015; and
Dependent variable = ln(Google Scholar cites per year)
Number of original studies = 95
Time period = 2008-2020
Estimation Method = Negative Binomial/Fixed Effects
Control group = No
He concludes that “replication failure reduced citations of the replicated studies by approximately 9%”, though the effect was not statistically significant.
In conclusion, all three psychology studies estimate that unsuccessful replication reduce citations, but the estimated effects are insignificant in two of the three studies and unreported in a third.
The Economics Studies
Once we get outside of psychology, the plot thickens. There is nothing of the scale of the RP:P to allow researchers to assume random assignment with respect to whether a replication is successful. Any investigation of whether economics is self-correcting must work with non-experimental, observational data. Two studies have attempted to do this.
Ankel-Peters, Fiala, & Neubauer (2023). Ankel-Peters, Fiala, & Neubauer focus on the flagship journal of the American Economic Association. They study all replications published as “Comments” that appeared in the American Economic Review (AER) from 2010-2020. Their AER sample comes with one big advantage and one big disadvantage.
The advantage lies in the fact that replications that appear in the AER are likely to be seen. A problem with replications that appear in lesser journals is that they may not have the visibility to affect citations. But that isn’t a problem for replications that appear in the AER. If ever one were to hope to see an adverse citation impact from an unsuccessful replication, one would expect to find it in the studies replicated in the AER.
The big disadvantage is that virtually all of the replications published by the AER are unsuccessful replications. This makes it impossible to compare the citation impact of unsuccessful replications with successful ones.
A second disadvantage is the relatively small number of studies in their sample. When Ankel-Peters, Fiala, & Neubauer try to examine citations for original studies that have at least 3 years of data before the replication was published and 3 years after, they are left with 38 studies.
Their main finding is represented by their FIGURE 6 below.

Ankel-Peters, Fiala, & Neubauer do not attempt to estimate the causal effect of an unsuccessful replication. Recognizing the difficulty of using their data to do that, they state, “…we do not strive for making a precise causal statement of how much a comment affects the [original paper’s] citation trend. The qualitative assessment of an absence of a strong effect is sufficient for our case” (page 15). That leaves us with Coupé & Reed (2023).
Coupé & Reed (2023). I note that one of the co-authors of this paper is Reed, who is also writing this blog. This raises the question of objectivity. Let the reader beware!
Unlike Ankel-Peters, Fiala, & Neubauer, Coupé & Reed attempt to produce a causal estimate of the effect of unsuccessful replications. Their approach relies on matching.
They begin with a set of 204 original studies that were replicated for which they have 3 years of data before the replication was published and 3 years of data after the replication was published. Approximately half of the replicated studies had their results refuted by their replications, with the remaining half receiving either a confirmation or a mixed conclusion.
They consider estimating the following DID specification:
Yit = β0 + β1Negativeit + Study Fixed Effects + Year Fixed Effects + Control Variables
Where Yit is Scopus citations per year and “Negative” takes the value 1 for an original study that failed to replicate and t > the year the replication was published. However, concern about the non-random assignment of treatment and the ability of control variables to adjust for this non-randomness causes them to reject this approach.
Instead, they pursue a two-stage matching approach. First, they use Scopus’ database and identify potential controls from all studies that were published in the same years as the replicated studies, appeared in the same set of journals that published the replicated studies, and belonged in the same general Scopus subject categories. This produced a pool of 112,000 potential control studies.
In the second stage, they matched these potential controls with the replicated studies on the basis of their year-by-year citation histories. Their matching strategy is illustrated in FIGURE 2.
If the original study was published 3 years before the replication study was published, they match on the intervening two years (Panel A). If the original study was published 4 years before the replication study was published, they match on the intervening 3 years (Panel B). And so on.

They don’t just match on the total number of citations in the pre-treatment period, but on the year-by-year history. The logic is that non-random assignment is better captured by finding other articles with identical citation histories than by adjusting regressions with control variables.
This gives them 3 sets of treateds and controls depending on the closeness of the match. For near perfect matches (“PCT=0%”), they have 74 replications and 7,044 controls. For two looser matching criteria (“PCT=10%” and “PCT=20%), they have 103 replications and 7,552 controls; and 142 replications and 11,202 controls, respectively.
For all original studies with a positive replication in a given year t, they define DiffPit = Ypit – Ypbarit, where Ypit is the associated citations for study i and YPbarit is the average of all the controls matched with study i. For all original studies i with a negative replication in a given year t, they define DiffNit = YNit – YNbarit, where YNit and YNbarit are defined analogously as above.
Coupé and Reed then pool these two sets of observations to get
Diffit = (Ypit – Ypbarit)×(1-Nit) + (YNit – YNbarit)×Nit = β0 + β1Negativeit
where Nit is a binary variable that takes the value 1 if the original study had a negative/failed replication.
They then estimate separate regressions for each year t = -3, -2, -1, 0, 1, 2, 3, where time is measured from the year the replication study was published.
β1 then provides an estimate of the difference in the citation effect from a negative replication compared to a positive or mixed replication. Their preferred results are based on quantile regression to address outliers and are reported in their Table 10 (see below).

They generally find a small, positive effect associated with negative replications of less than 2 citations/year. In all but one case (PCT=0%, t=2), the estimates are statistically insignificant. In no case do they find a negative and significant effect on citations and thus, they find no evidence of a citation penalty for failed replications.
Unlike psychology, any estimates of the causal effect of failed replications on citations in economics must deal with the problem of non-random treatment assignment. Reed and Coupé’s identification strategy relies on the fact that Ypbarit and YNbarit account for any unobserved characteristics associated with positive and negative replications, respectively. Since Ypbarit and YNbarit “predicted” the citation behaviour of the original studies before they were replicated, the assumption is that they represent an unbiased estimate of how many citations the respective original studies would have received if they had not been replicated. Under this assumption, β1 provides a causal estimate of the citation effect of a negative replication versus a positive one.
For psychology, the results are pretty convincing: a failed replication has a relatively small and statistically insignificant impact on a study’s citations.
In economics, the challenge is to find a way to address the problem that researchers do not randomly choose studies to replicate. Studies by Ankel-Peters, Fiala, & Neubauer (2023) and Reed & Coupé (2023) present two such approaches. Both studies fail to find any evidence of a citation penalty from unsuccessful replications. Whether one finds their results convincing depends on how well one thinks they address the problem of non-random assignment of treatment.
Bob Reed is Professor of Economics and the Director of UCMeta at the University of Canterbury. He can be contacted at bob.reed@canterbury.ac.nz, respectively.
REFERENCES
Ankel-Peters, J., Fiala, N., & Neubauer, F. (2023). Is economics self-correcting? Replications in the American Economic Review. Ruhr Economic Papers, #1005.
Coupé, T. & Reed, W.R. (2023). Do Replications Play a Self-Correcting Role in Economics? Mimeo, University of Canterbury.
Schafmeister, F. (2021). The effect of replications on citation patterns: Evidence from a large-scale reproducibility project. Psychological Science, 32(10), 1537-1548.
Serra-Garcia, M., & Gneezy, U. (2021). Nonreplicable publications are cited more than replicable ones. Science Advances, 7(21), eabd1705.
von Hippel, P. T. (2022). Is psychological science self-correcting? Citations before and after successful and failed replications. Perspectives on Psychological Science, 17(6), 1556-1565.
FEATURED RESEARCH (“Reassessing the Effects of a Communication-and-Resolution Program on Hospitals’ Malpractice Claims and Costs”) – Another Example of a Journal Behaving Badly
NOTE: According to the SCImago Journal Rankings, Health Affairs is ranked in the top quartile (Q1) of journals in the “Health Policy” and “Medicine (miscellaneous)” subject areas. It has an H-index of 190.
[Excerpts are taken from the article “Reassessing the Effects of a Communication-and-Resolution Program on Hospitals’ Malpractice Claims and Costs” by Florence LeCraw, Daniel Montanera, and Thomas Mroz in Econ Journal Watch.]
“All the evidence behind the present reassessment was available in the original article and hence to the editors and reviewers at Health Affairs, and two of the three major flaws we uncovered follow directly from only a moderately close examination of the paper’s tables….Such failure does not appear to be a rare event in health research, as indicated by several other investigations (Ebrahim et. 2014; Khan et al. 2020; Ito et al. 2021).”
“Most importantly, Health Affairs’ response to the uncovering of these errors, even after the external reviewers concurred with our reanalysis, was to offer only a reduced-visibility forum for the reanalysis.”
“…More concerning was a senior Health Affairs editor telling us that their policy is to not publish replication papers even when peer review errors are identified since their audience is not interested in this type of paper.”
“Unfortunately, burying or ignoring the uncovering of all but the most scandalous errors in published research seems to be the norm in health policy and medical journals. At the 2022 International Congress of Peer Review and Scientific Publication, four editors-in-chief of medical journals told one of us that they also did not publish replication studies. They all said they were concerned that publishing replication papers would negatively affect their impact factors.”
“Due to the attitudes of the editorial boards described above, most researchers perceive little or no reward for attempts to uncover such deficiencies in medical and healthcare papers. Medical journals, as well as academic institutions, should strongly encourage and reward replications and re-analyses of published papers.”
“We think of the paraphrasing of a sentiment often attributed to Mark Twain or Josh Billings: ‘It ain’t what you don’t know that gets you into trouble. It’s what you know for sure that just ain’t so.'”
To read the full article, click here.
FEATURED RESEARCH: Find Published Articles That Can Be Reproduced in Stata
Even papers for which data and code are available are not always easy to replicate (see, for example, Chang & Li, 2022). So when looking for a replicable paper for your class, you might need to try several papers before you find one that is actually replicable and hence can be used in class for a replication exercise.
To make your life easier, Sebastian Kranz has made a ShinyApp that automatically checks Stata code and data to compute the percentage of commands that run without error. An example is given below. Note particularly Article 5 where it says “Stata reproduction 84%”. This tells you that you are able to reproduce most of the results in the paper, which makes it a good candidate to give to your students for replication.

If you have better things to do than search through thousands of articles, you can focus your search by title and abstract keywords (see below)-
To search for articles, click here.
To read more about Sebastian Kranz’s ShinyApp, click here.
Reference

You must be logged in to post a comment.