[From the preprint, “What is Replication?” by Brian Nosek and Tim Errington, posted at MetaArXiv Preprints]
“According to common understanding, replication is repeating a study’s procedure and observing whether the prior finding recurs…This definition of replication is intuitive, easy to apply, and incorrect.”
“The problem is this definition’s emphasis on repetition of the technical methods–the procedure, protocol, or manipulated and measured events…If replication requires repeating the manipulated or measured events of the study, then it is not possible to conduct replications in observational research or research on past events.”
“We propose an alternative definition for replication that is more inclusive of all research, and more relevant for the role of replication in advancing knowledge. Replication is a study for which any outcome would be considered diagnostic evidence about a prior claim.”
“To be a replication two things must be true: outcomes consistent with a prior claim would increase confidence in the claim, and outcomes inconsistent with a prior claim would decrease confidence in the claim.”
“Replication is not about the procedures per se, but using similar procedures reduces uncertainty in the universe of possible units, treatments, outcomes, and settings that could be important for the claim. Because there is no exact replication, every replication is a test of generalizability.”
“This exposes an inevitable ambiguity in failures to replicate. Was the original evidence a false positive, the replication a false negative, or does the replication identify a boundary condition of the claim? We can never know for certain that earlier evidence was a false positive. It is always possible that it was “real” and we cannot identify or recreate the conditions necessary to replicate successfully.”
“But, that does not mean that all claims are true and science cannot be self-correcting. Persistent failures to replicate will narrow the universe of conditions to which the claim applies. That process may result in a much narrower, but precise set of circumstances in which evidence for the claim is replicable, or it may result in failure to ever establish conditions for replicability and relegate the claim to irrelevance.”
“Replication is characterized as the boring, rote, clean-up work of science. This misperception makes funders reluctant to fund it, journals reluctant to publish it, and institutions reluctant to reward it.”
“Replication is a central part of the iterative maturing cycle of description, prediction, and explanation. A shift in attitude that includes replication in funding, publication, and career opportunity will accelerate research progress.”
To read the preprint, click here.
[Excerpts are taken from the article “Can Smiling Really Make You Happier?” by Cathleen O’Grady, published at FiveThirtyEight.com]
“In 1988, social psychologist Fritz Strack published a study that…asked participants to…hold a pen in their mouths in a position that forced them either to bare their teeth in a facsimile of a smile or to purse their lips around the pen…When both groups were shown a set of newspaper comics…the teeth-barers rated the images as funnier than the lip-pursers did.”
“…Even though participants weren’t thinking about smiling or their mood, just moving their face into a smile-like shape seemed to affect their emotions…Decades of corroboration followed, as researchers published other experiments that also showed support for the facial feedback hypothesis.”
“But in 2016, all at once, 17 labs failed to replicate the pen study. Those 17 studies, coordinated by Dutch psychologist E.J. Wagenmakers, repeated the original study as closely as possible to see if its result held up, with just a few changes…When all 17 studies failed to replicate the original result, the effect was “devastating for the emotion literature,” said Nicholas Coles, a psychology grad student whose research focuses on the facial feedback effect.”
“But as powerful as multi-lab replication efforts like these are, they aren’t necessarily the last word.”
“When Wagenmakers and his colleagues published their replication study in 2016, Coles was digging deeply into the facial feedback literature. He planned to combine all of the existing literature into a giant analysis that could give a picture of the whole field. Was there really something promising going on with the facial feedback hypothesis? Or did the experiments that found a big fat zero cancel out the exciting findings? He was thrilled to be able to throw so much new data from 17 replication efforts into the pot.”
“He came up from his deep dive with intriguing findings: Overall, across hundreds of results, there was a small but reliable facial feedback effect. This left a new uncertainty hanging over the facial feedback hypothesis. Might there still be something going on — something that Wagenmakers’s replication attempt had missed?”
“Coles didn’t think that either Wagenmakers’s replication or his own study could put the matter to rest…So he set about designing a different kind of multi-lab collaboration. He wanted not just to replicate the original study, but to test it in a new way. And he wanted to test it in a way that would convince both the skeptics and those who still stood by the original result.”
“He started to pull together a large team of researchers that included Strack. He also asked Phoebe Ellsworth, a researcher who was testing the facial feedback effect as far back as the 1970s, to come on board as a critic.”
“Coles’s group, called the Many Smiles Collaboration…is based on the pen study from 1988, but with considerable tweaking. Through a lengthy back-and-forth between collaborators, peer reviewers and the journal editor, the team has refined the original plan, eventually arriving at a method that everyone agrees is a good test of the hypothesis. If it finds no effect, said Strack, ‘that would be a strong argument that maybe the facial feedback hypothesis is not true.’”
“An early pilot of the Many Smiles study…suggested that smiling can affect feelings of happiness. Later this year, all the collaborators will kick into gear to see if the pilot’s findings can be repeated across 21 labs in 19 countries. If they find the same results, will that be enough to convince even the skeptics that it’s not just a fluke?”
“Well … maybe. A study like Wagenmakers’s sounds, in principle, like enough to lay a scientific question to rest, but it wasn’t. A study like Coles’s sounds like it could be definitive too, but it probably won’t be. Even Big Science can’t make science simple.”
To read the article, click here.
[Excerpts taken from the article, “Developing a fully automated evidence synthesis” by John Brassey et al., published in BMJ Evidence-Based Medicine]
“Here, we describe a fully automated evidence synthesis system for intervention studies, one that identifies all the relevant evidence, assesses the evidence for reliability and collates it to estimate the relative effectiveness of an intervention. Techniques used include machine learning, natural language processing and rule-based systems…The idea was to explore how far the current technologies could go to help develop a fully automated form of evidence synthesis.”
“Cochrane, a prominent SR producer, reports: ‘Each systematic review addresses a clearly formulated question; for example: Can antibiotics help in alleviating the symptoms of a sore throat? All the existing primary research on a topic that meets certain criteria is searched for and collated, and then assessed using stringent guidelines, to establish whether or not there is conclusive evidence about a specific treatment.’”
“From the above, for a given clinical question, we can extract the following questions that would need answering in a successful system: 1. Can all the evidence be identified? 2. Can this evidence be assessed? 3. Can it be collated to establish if there is conclusive evidence? These were the core tasks of this project.”
“…we used the concept of PICO, an acronym, which highlights what the population, intervention, comparison and outcomes are. For this step, we only required the PIC elements….The aim of the PIC identification is to automatically extract the population (eg, men with asthma), the intervention (eg, treated with vitamin C) and its comparison (eg, receiving placebo)…”
“…we exploited commonly occurring linguistic patterns. For example, consider the sentence: The bioavailability of nasogastric versus trovafloxacin in healthy subjects. In this sentence, a possible pattern is ‘[…] of […] vs […] in […]’; in which the preposition ‘of’ indicates the start of the Intervention, ‘vs’ separates the Intervention from the Comparison and finally, ‘in’ indicates the start of the population.”
“Since the text patterns of RCTs are variable, it was necessary to identify multiple patterns that cover the most common cases. To create ground truth data for this task, we employed six human annotators (two linguists and four people from the medical domain) and asked them to manually label the PIC elements in the title and the abstract of 1750 RCTs.”
“After manual labelling, we used 80% of the labelled RCTs (training set) to derive the most frequently occurring patterns for PIC identification. Afterwards, we created an algorithm that checked if an input sentence conforms to one of the identified patterns; if so, the PIC information was extracted. An overview of the process is given in figure 1.”

“ASSESSING THE EVIDENCE: This involved multiple steps and techniques:”
– “Sentiment analysis—this allowed us to understand if the intervention had a positive or negative impact in the population studied.”
– “Risk of bias (RoB) assessment—to indicate if a trial was likely to be biassed or not.”
– “Sample size calculations—understanding how big the trial was, an indication of how reliable the results are likely to be.”
“…the results are displayed with the overall effectiveness on the y-axis. Each ‘blob’ corresponds to an evidence group, where the size of the blob represents the sample size while the shading reflects the overall RoB, see figure 2.”
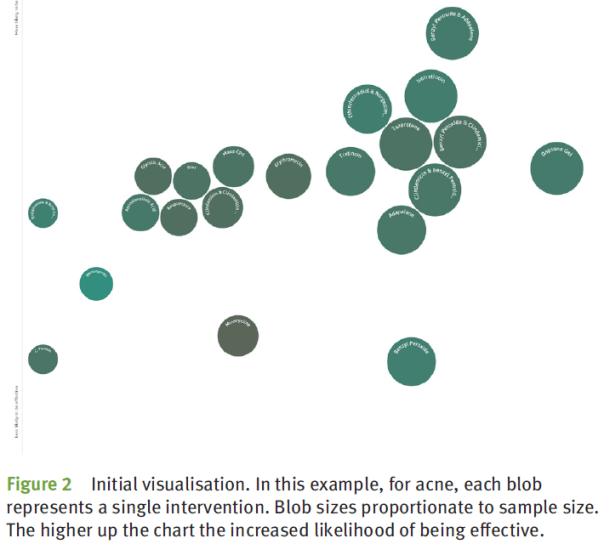
“To the best of our knowledge, this is the first publicly available system to automatically undertake evidence synthesis…As the system is fully automatic, it means that all RCTs and SRs are included in the syntheses meaning that all conditions and interventions are covered and, given the nature of the system, as new RCTs and SRs are published they are automatically added to the system ensuring it is always up to date.”
“The method described is much akin to vote counting, whereby the number of positive and negative studies are counted. However, the technique we used has overcome one major criticism of vote counting in that we take into account sample size of the trials and adjust the impact accordingly. In other words, a small trial is not counted as equal to a large trial. Similarly, with our ability to assess the RoB for a given RCT and SR, we are able to ensure that trials with higher risks of bias carry less weight than unbiased trials.”
“This autosynthesis project is very much in the development and is released as a ‘proof of concept’.”
To read the article, click here.
[Excerpts taken from an announcement posted on the BITSS website]
“‘Transparency, Reproducibility, and Credibility of Economics Research’” is a research symposium hosted collaboratively by the World Bank Development Impact Evaluation (DIME) group, BITSS, the International Initiative for Impact Evaluation (3ie), The Abdul Latif Jameel Poverty Action Lab (J-PAL), and Innovations for Poverty Action (IPA) on September 10, 2019 at the World Bank Headquarters in Washington, D.C.”
“The Symposium will feature presentations by the host organizations on current methods and innovations to advance transparency and reproducibility in economics, as well as expert panels on the following topics: 1) Definitions of Reproducibility; 2) Balancing Open Data and Privacy; and 3) Practical steps to improved Transparency, Reproducibility and Credibility in Economics.”
To read more, click here.
[Excerpts taken from the article “Do researchers trust each other’s work?” by David Matthews, published at Times Higher Education]
“…do researchers actually trust each other? The answer, according to data from a survey of more than 3,000 scholars across the world, is “sometimes”: a sizeable minority placed limited weight on their colleagues’ work.”
“A full 37 per cent of respondents said that during the past week, “about half” or less than half of the “research outputs” they “interacted with” or “encountered” were actually “trustworthy”. Only 14 per cent said that they trusted all the work that they had come across.”
“With scholars “overwhelmed” by the volume of research that they need to keep abreast of, it is “not a great surprise that researchers are doubting some of the material that’s out there”, said Adrian Mulligan, director of customer insights at the publisher Elsevier, which carried out the survey. “
“The results come with some caveats: “research outputs” can refer not just to articles in journals, but also to things like academic blogs, datasets, non-peer reviewed papers in preprint repositories, or, in some cases, news articles about findings, Mr Mulligan stressed.”
“Academics inclined to distrust may have been more likely to have taken the survey. And Elsevier has an interest in presenting academics as being flooded by potentially dubious work, as the publisher markets itself as being able to help scholars navigate this stream of information.”
“But the findings may still help illuminate an arguably poorly evidenced part of the scientific process. While statistics on public trust in science are plentiful, Mr Mulligan said that he was not aware of any other research on whether scholars trust each other.”
To read the article, click here. (NOTE: Article is behind a paywall.)
[Excerpts taken from the report “The Crowdsourced Replication Initiative: Investigating Immigration and Social Policy Preferences using Meta-Science” by Nate Breznau, Eike Mark Rinke, and Alexander Wuttke, posted at SocArXiv Papers]
“A burning question is what impact immigration and immigration-related events have on policy and social solidarity…This project employs crowdsourcing methods to address these issues.”
“This executive report provides short reviews of the area of social policy preferences and immigration, and the methods and impetus behind crowdsourcing. It details the methodological process we followed conducting the CRI and provides some descriptive statistics.”
“The project has three planned papers as follows. Paper I will include all participant co-authors; II and III just the PIs. Readers may follow the progress of these papers and find all details about the CRI on its Open Science Framework (OSF) project page.”
“I. “Does Immigration Undermine Social Policy? A Crowdsourced Re-Investigation of Public Preferences across Mass Migration Destinations”. The main findings of the project presenting a replication and extension based on original research of Brady and Finnigan (2014) titled, ‘Does Immigration Undermine Social Policy Preferences?’.”
“Given the sensitivity of small-N macro-comparative studies and that researchers might report only those models out of the thousands that gave the results they sought, reliance on a single replication study (or the original), even if it is deemed to perfectly reflect the underlying causal theory, is a flimsy means for concluding whether a study is verifiable. With a pool of researchers independently replicating a study we develop far more confidence in the results.”
“We hypothesize that there is researcher variability in replications even when the original study is fully transparent…To do this we randomly divided our researcher sample into an original group and an opaque group. The original received all materials including code from the original study while the opaque group received an anonymized version of the study, with only descriptive rather than numeric results and no code.”
“We had 216 researchers in 106 teams from 26 countries in 5 continents respond to our call for researchers as of its closing on July 27th, 2018…Figure 2. Gives the rates of participation throughout the course of the CRI.”
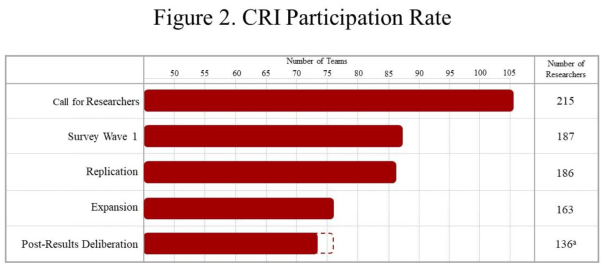
“The call for researchers promised co-authorship on the final published paper, similar to the Silberzahn et al (2018) study. For us this was an essential component to reduce if not remove publication or findings biases. We wanted to be clear that simply doing the tasks we assigned qualified them as equal co-researchers and co-authors, they needed not produce anything special, significant or ‘groundbreaking’, only solid work.”
“In the first group, labeled original version, we assign teams to assess the verifiability of the prominent B&F macro-comparative study. This group has minimal research design decisions to make, theoretically none…As the original study is very transparent with the authors sharing their analytical code (for the statistical software Stata) and country-level data, it is a least-likely case to find variation in outcomes.”
“We gave the second group a slightly artificial treatment. They replicate a derivation of the B&F study altered by us to render it anonymous and less transparent, labeled opaque version…offering them limited information about the original study, forcing them to make ‘tougher’ choices in how to replicate it…To do this we re-worded the study, gave no numeric results and provided no code to the replicators in this experimental group.”
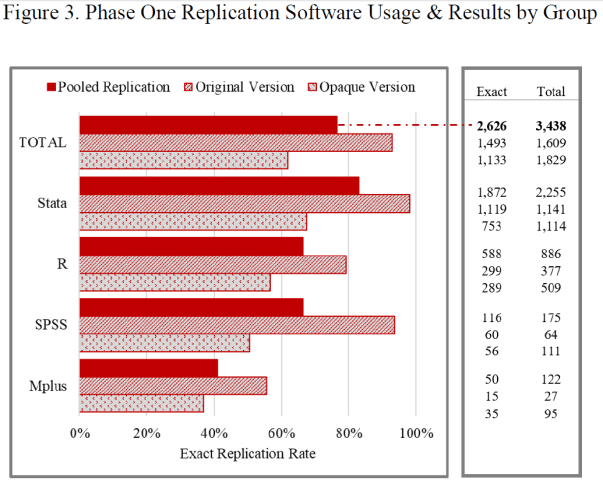
“Replicators reported odds-ratios following the estimates reported by B&F…We considered an odds-ratio to be an “exact” replication if it was within <0.01 of the original effect; this allows for rounding error. Figure 3 reports the ratio of exact replications by usage of software types and experimental group.”
“The expansion phase required teams to think about the B&F models and determine if they thought of improvements or alternatives. The idea was to challenge researchers to think about the data-generating model, or plausible alternatives…”
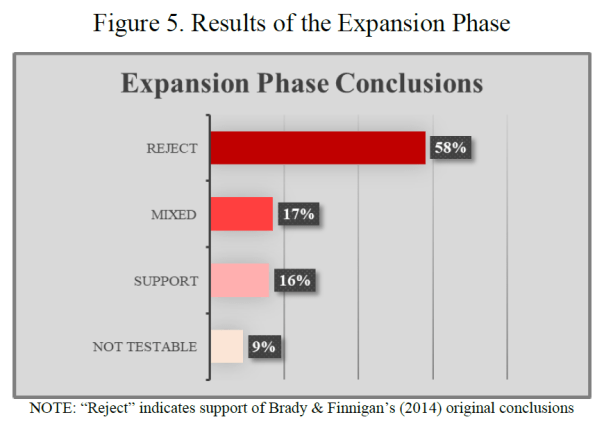
“…we asked each team for a subjective conclusion: “We ask that you provide a substantive conclusion based on your test of the hypothesis that a greater stock or a greater increase in the stock of foreign persons in a given society leads the general public to become less supportive of social policy…” Figure 5 offers the subjective conclusions of the researchers drawn based on their expansion analyses.”
“Our main conclusions will arrive in the three working papers we outlined in section 1.3. Here we provided only an overview.”
“We can say with some certainty that the original study of Brady and Finnigan (2014) is verifiable in our replications. The expansions also suggest that their conclusions are robust to a multiverse of data set up and range of alternative model specifications. This suggests there is not a ‘big picture’ finding that immigration erodes popular support for social policy or the welfare state as a whole. However, our findings cast enough suspicion into the equation that further scrutiny is necessary at this big picture level.”
To read the full report, click here.
[Excerpts taken from the preprint “Detection of data fabrication using statistical tools” by Chris Hartgerink, Jan Voelkel, Jelte Wicherts, and Marcel van Assen, posted at PsyArXiv Preprints]
“In this article, we investigate the diagnostic performance of various statistical methods to detect data fabrication. These statistical methods (detailed next) have not previously been validated systematically in research using both genuine and fabricated data.”
“We present two studies where we try to distinguish (arguably) genuine data from known fabricated data based on these statistical methods. These studies investigate methods to detect data fabrication in summary statistics (Study 1) or in individual level (raw) data (Study 2) in psychology.”
“In Study 1, we invited researchers to fabricate summary statistics for a set of four anchoring studies, for which we also had genuine data from the Many Labs 1 initiative…In Study 2, we invited researchers to fabricate individual level data for a classic Stroop experiment, for which we also had genuine data from the Many Labs 3 initiative.”
“Statistical methods to detect potential data fabrication can be based either on reported summary statistics that can often be retrieved from articles or on the raw (underlying) data if these are available. Below we detail p-value analysis, variance analysis, and effect size analysis as potential ways to detect data fabrication using summary statistics… Among the methods that can be applied to uncover potential fabrication using raw data, we consider digit analyses…and multivariate associations between variables.”
“…our studies have highlighted that variance- and effect size analysis and multivariate associations are methods that look promising to detect problematic data.”
“All presented results…pertain to relative comparisons between genuine and fabricated data. Hence, all statements about the performance of classification depends on the availability of unbiased genuine data to compare to… we agree with the call to always include a control sample when applying these statistical tools to studies that look suspicious…”
“We do advise to use some of the more successful statistical methods as screening tools in review processes and as additional tools in formal misconduct investigations where prevalence is supposedly higher than in the general population of research results…this should only happen in combination with evidence from other sources than statistical methods”
“…if any of these statistical tools are used, we recommend to solely use them to screen for indications of potential data anomalies, which are subsequently further inspected by a blinded researcher to prevent confirmation bias and using a rigorous protocol that involves due care and due process.”
To read the article, click here.
[Excerpts taken from the article “No Crisis but No Time for Complacency” by Wendy Wood and Timothy Wilson, published in Observer Magazine]
“The National Academies of Sciences, Engineering, and Medicine recently published a report titled Reproducibility and Replicability in Science. We both had the privilege of serving on the committee that issued the report, and this is a brief summary of how the committee came about and its main findings.”
“In response to concerns about replicability in many branches of science, Congress — via the National Science Foundation — directed the National Academies to conduct a study. The mandate was broad: to define reproducibility and replicability, assess what is known about how science is doing in these areas, review current attempts to improve reproducibility and replicability, and make recommendations for improving rigor and transparency in research — across all fields of science and engineering…”
“So, what did the committee conclude? Our job was first to define reproducibility and replicability…We defined reproducibility as computational reproducibility — obtaining consistent computational results using the same input data, computational steps, methods, code, and conditions of analysis. Replicability was defined as obtaining consistent results across studies that were aimed at answering the same scientific question, each of which obtained its own data. In short, reproducing research involves using the original data and code, whereas replicating research involves new data collection and methods similar to those used in previous studies.”
“Once we defined our terms, what did the committee conclude about the state of reproducibility and replicability in science?…The committee’s answer was, in short, ‘No crisis, but no complacency.’”
“We saw no evidence of a crisis, largely because the evidence of nonreproducibility and nonreplicability across all science and engineering is incomplete and difficult to assess.”
“…a key observation in the report, we believe, is that, “The goal of science is not, and ought not to be, for all results to be replicable” (p. 28), because there is a tension between replicability and discovery.”
“…the committee noted that nonreplicability can arise from a number of sources, some of which are potentially helpful to advancing scientific knowledge and others that are unhelpful.”
“Nonreplicability can be caused by limits in current scientific knowledge and technologies, as well as inherent but uncharacterized variabilities in the system being studied. When such nonreplicating results are investigated and resolved, it can lead to new insights, better characterization of uncertainties, and increased knowledge about the systems being studied and the methods used to study them.”
“Nonreplicability also may be due to foreseeable shortcomings in the design, conduct, and communication of a study. Whether arising from lack of understanding, perverse incentives, sloppiness, or bias, these unhelpful sources of nonreplicability reduce the efficiency of scientific progress.”
“Replicability and reproducibility are not the only ways to gain confidence in scientific results. Research synthesis and meta-analysis can help assess the reliability and validity of bodies of research…Meta-analytic tests for variation in effect sizes can suggest potential causes of nonreplicability in existing research — in individual studies that are outliers, in particular populations, or using certain methods. Of course, such analyses must take into account the possibility that published results are biased by selective reporting and, to the extent possible, estimate its effects.”
“We strongly endorse the broad conclusion from our meetings: No crisis, but no time for complacency!”
To read the article, click here.
The SCORE Project is looking to hire a part-time research scientist (PhD level) for the next six months. They are particularly interested in having an economist to complement the skill sets of other research scientists on the team.
You can check out the job advert here: http://cos.io/jobs
Pass the word.
[Excerpts taken from the article “Ted Miguel in conversation on “Transparent and Reproducible Social Science Research: How to Do Open Science” by Isabelle Cohen and Hagit Caspi, posted at the website of the Economics Department, University of California, Berkeley]
“Edward Miguel wants researchers in the social sciences to join the Open Science Movement. In his new book, Transparent and Reproducible Social Science Research: How to Do Open Science, Miguel and co-authors Jesse Freese (Stanford University) and Garret Christensen (U.S. Census Bureau) give readers the tools to do so.”
“What do you hope to accomplish with this book?”
“There are two goals here. The more obvious one is giving researchers (whether they’re students or practitioners) tools and practices that lead to better, more transparent research, such as pre-analysis plans and reproducible coding, so that they can improve their research from a technical standpoint.”
“On a more fundamental level, we wanted to provide readers with a new mindset about how to do research. I want them to understand that being a researcher isn’t just about learning statistical techniques, that it’s about a set of values and principles and a way of looking at the world in a very even handed-way.”
“You mention the File Drawer Problem in the book. Tell me more about that and how it translates to everyday research.”
“…A famous paper by Sterling in 1957 showed that over 97% of papers published in leading Psychology journals in the 1950s had statistically significant results, which meant that a lot of null results were just disappearing. The issue with that is that if we’re not seeing a large body of evidence then our understanding of the world is really incomplete…”
“That brings us to registries, which are a recent development from the past seven years, and an interesting solution. What is a registry and why should researchers register their projects?”
“A study registry is an attempt to make the universe of studies that have been conducted more accessible to researchers that fewer disappear. This is the product of deliberate action by the US government and National Institutes of Health (NIH) who, 20 years ago, established a registry and tried to encourage or forced grantees to sort to register their trials on the registry. That was motivated by various scandals in the eighties and nineties of pharmaceutical companies funding trials for drugs and then only selectively publishing the results that they liked. In the book, we talk about how applying this practice in the social sciences can help make null results more prevalent.”
“The idea of pre-analysis plans seems to compliment this effort to avoid “cherry picking” which studies are published.”
“Yeah, that’s right. So before we’ve analyzed the data, we post what our main hypotheses are, what our statistical models are with data we want to use will be. That has this great benefit of increasing accountability for scholars, who are then more likely to report the results of those pre-specified analyses. it constrains researchers in some way to make sure they are showing the analyses they said they would show.”
“One of my favorite quotes from the book is that “science prizes originality”. And yet, you call for replicating. Tell me why should we be replicating.”
“Scientific results that don’t replicate aren’t really scientific results. Replication means that a result would be the same if the experiment were to be conducted again. It increases our certainty and the validity of the result.”
“If there was one tool you would want researchers who read this book to take from it, what would it be?”
“It’s hard to choose, but I’d say that maintaining reproducible coding practices is a valuable tool. It pays huge dividends, whether it’s for you to reconstruct the data later or for shareability.”
“But there is a larger point here, which is that we hope to change the attitude towards what constitutes research quality. When people ask whether someone is a good student, or look at the quality of their work, the criteria shouldn’t be, “Oh, they’ve got two stars.” It should be, “They tackled this really important question around state capacity for tax collection in Uganda, which is a central issue in development. Without tax revenue, you can’t invest in social programs. So they tackled this really important question, with a great research design and a large sample and a clever experiment.” This puts the emphasis on the method, which in itself is reproducible, rather than the specific result.”
To read the full interview, click here.

You must be logged in to post a comment.