A very nice and balanced discussion of the issues involved in criticizing other researchers’ work on social media can be found in the article “How Should We Talk About Amy Cuddy, Death Threats, and the Replication Crisis?” by Jesse Singal at nymag.com.
A tweet that appears in the article succinctly summarizes one of its messages: “1. Bullying/Threats: BAD; 2. Scientific criticism: healthy”. Tone matters. A lot. However, the article goes on to say more:
“The more open and transparent science is, the less time researchers and observers will spend on hopelessly subjective questions of tone and intent. To be clear, there will never be a time when the questions raised by the replication crisis can be answered or evaluated in a purely objective manner, of course. Even when everyone has access to the data underpinning a given controversy, reasonable people, again, can and do disagree on which claims are warranted on the basis of which evidence.”
“But the faster we can get to an age in which data sharing and transparency in general are established norms in psychology, the easier it will be to avoid getting mired in unanswerable debates about really subjective subjects like tone.”
When we perform a study, we would like to conclude there is an effect, when there is an effect. But it is just as important to be able to conclude there is no effect, when there is no effect. So how can we conclude there is no effect? Traditional null-significance hypothesis tests won’t be of any help here. If you observe a p > 0.05, concluding that there is no effect is a common erroneous interpretation of p-values.
One solution is equivalence testing. In an equivalence test, you statistically test whether the observed effect is smaller than anything you care about. One commonly used approach is the two-one-sided test (TOST) procedure (Schuirmann, 1987). Instead of rejecting the null-hypothesis that the true effect size is zero, as we traditionally do in a statistical test, the null-hypothesis in the TOST procedure is that there is an effect.
For example, when examining a correlation, we might want to reject an effect as large, or larger, than a medium effect in either direction (r = 0.3 or r = -0.3). In the two-sided test approach, you would test whether the observed correlation is significantly smaller than r = 0.3, and test whether the observed correlation is significantly larger than r = -0.3. If both these tests are statistically significant (or, because these are one-sided tests, when the 90% confidence interval around our correlation does not include the equivalence bounds of -0.3 and 0.3) we can conclude the effect is ‘statistically equivalent’. Even if the effect is not exactly 0, we can reject the hypothesis that the true effect is large enough to care about.
Setting the equivalence bounds requires that you take a moment to think about which effect size you expect, and which effect sizes you would still consider support for your theory, or which effects are large enough to matter in practice. Specifying the effect you expect, or the smallest effect size you are still interested in, is good scientific practice, as it makes your hypothesis falsifiable. If you don’t specify a smallest effect size that is still interesting, it is impossible to falsify your hypothesis (if only because there are not enough people in the world to examine effects of r = 0.0000001).
Furthermore, when you specify which effects are too small to matter, it is possible to find an effect is both significantly different from zero, and significantly smaller than anything you care about. In other words, the finding lacks ‘practical significance’, solving another common problem with overreliance on traditional significance tests. You don’t have to determine the equivalence bounds for every other researcher – you can specify which effect sizes you would still find worthwhile to examine, perhaps based on the resources (e.g., the number of participants) you have available.
You can use equivalence tests in addition to null-hypothesis significance tests. This means there are now four possible outcomes of your data analysis, and these four cases are illustrated in the figure below (adapted from Lakens, 2017). A mean difference of Cohen’s d = 0.5 (either positive or negative) is specified as a smallest effect size of interest in an independent t-test (see the vertical dashed lines at -0.5 and 0.5). Data is collected, and one of four possible outcomes is observed (squares are the observed effect size, thick lines the 90% CI, and thin lines the 95% CI).
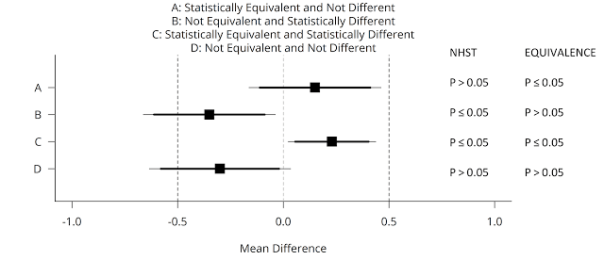
We can conclude statistical equivalence if we find the pattern indicated by A: The p-value from the traditional NHST is not significant (p > 0.05), and the p-value for the equivalence test is significant (p ≤ 0.05). However, if the p-value for the equivalence test is also > 0.05, the outcome matches pattern D, and we can not reject an effect of 0, nor an effect that is large enough to care about. We thus remain undecided. Using equivalence tests, we can also observe pattern C: An effect is statistically significant, but also smaller than anything we care about, or equivalent to null (indicating the effect lacks practical significance). We can also conclude the effect is significant, and that the possibility that the effect is large enough to matter can not be rejected, under pattern B, which means we can reject the null, and the effect might be large enough to care about.
Testing for equivalence is just as simple as performing the normal statistical tests you already use today. You don’t have to learn any new statistical theory. Given how easy it is to use equivalence tests, and how much they improve your statistical inferences, it is surprising how little they are used, but I’m confident that will change in the future.
To make equivalence tests for t-tests (one-sample, independent, and dependent), correlations, and meta-analyses more accessible, I’ve created an easy to use spreadsheet, and an R package (‘TOSTER’, available from CRAN), and incorporated equivalence test as a module in the free software jamovi. Using these spreadsheets, you can perform equivalence tests either by setting the equivalence bound to an effect size (e.g., d = 0.5, or r = 0.3) or to raw bounds (e.g., a mean difference of 200 seconds). Extending your statistical toolkit with equivalence tests is an easy way to improve your statistical and theoretical inferences.
Daniël Lakens is an Assistant Professor in Applied Cognitive Psychology at the Eindhoven University of Technology in the Netherlands. He blogs at The 20% Statistician and can be contacted at D.Lakens@tue.nl.
REFERENCES
Lakens, D. (2017). Equivalence tests: A practical primer for t-tests, correlations, and meta-analyses. Social Psychological and Personality Science. DOI: 10.1177/1948550617697177 https://osf.io/preprints/psyarxiv/97gpc/
Schuirmann, Donald J. (1987). A comparison of the two one-sided tests procedure and the power approach for assessing the equivalence of average bioavailability. Journal of Pharmacokinetics and Pharmacodynamics 15(6): 657-680.
[From the abstract of a new working paper by DANIEL SIMONS, YUICHI SHODA, and D. STEPHEN LINDSAY entitled “Constraints on Generality (COG): A Proposed Addition to All Empirical Papers”]
“A cumulative science depends on accurately characterizing the generality of findings, but current publishing standards do not require authors to constrain their inferences, leaving readers to assume the broadest possible generalizations. We propose that the discussion section of all primary research articles specify Constraints on Generality (a “COG” statement), identifying and justifying target populations for the reported findings. Explicitly defining the target populations will help other researchers to sample from the same populations when conducting a direct replication, and it will encourage follow-up studies that test the boundary conditions of the original finding. Universal adoption of COG statements would change publishing incentives to favor a more cumulative science.”
[From the article, “The ASA’s p-value statement, one year on”, which appeared in the online journal Significance, a publication of the American Statistical Association]
“A little over a year ago now, in March 2016, the American Statistical Association (ASA) took the unprecedented step of issuing a public warning about a statistical method. …From clinical trials to epidemiology, educational research to economics, p-values have long been used to back claims for the discovery of real effects amid noisy data. By serving as the acid test of “statistical significance”, they have underpinned decisions made by everyone from family doctors to governments. Yet according to the ASA’s statement, p-values and significance testing are routinely misunderstood and misused, resulting in “insights” which are more likely to be meaningless flukes. … Yet a year on, it is not clear that the ASA’s statement has had any substantive effect at all.”
The journal Economics: The Open Access, Open Assessment E-Journal is publishing a special issue on “The Practice of Replication.” This is how the journal describes it:
“The last several years have seen increased interest in replications in economics. This was highlighted by the most recent meetings of the American Economic Association, which included three sessions on replications (see here, here, and here). Interestingly, there is still no generally acceptable procedure for how to do a replication. This is related to the fact that there is no standard for determining whether a replication study “confirms” or “disconfirms” an original study. This special issue is designed to highlight alternative approaches to doing replications, while also identifying core principles to follow when carrying out a replication.”
“Contributors to the special issue will each select an influential economics article that has not previously been replicated, with each contributor selecting a unique article. Each paper will discuss how they would go about “replicating” their chosen article, and what criteria they would use to determine if the replication study “confirmed” or “disconfirmed” the original study.”
“Note that papers submitted to this special issue will not actually do a replication. They will select a study that they think would be a good candidate for replication; and then they would discuss, in some detail, how they would carry out the replication. In other words, they would lay out a replication plan.”
“Submitted papers will consist of four parts: (i) a general discussion of principles about how one should do a replication, (ii) an explanation of why the “candidate” paper was selected for replication, (iii) a replication plan that applies these principles to the “candidate” article, and (iv) a discussion of how to interpret the results of the replication (e.g., how does one know when the replication study “replicates” the original study).”
“The contributions to the special issue are intended to be short papers, approximately Economics Letters-length (though there would not be a length limit placed on the papers).”
“The goal is to get a fairly large number of short papers providing different approaches on how to replicate. These would be published by the journal at the same time, so as to maintain independence across papers and approaches. Once the final set of articles are published, a summary document will be produced, the intent of which is to provide something of a set of guidelines for future replication studies.”
Despite all the attention that economics, and other disciplines, have devoted to research transparency, data sharing, open science, reproducibility, and the like, much remains to be done on best practice guidelines for doing replications. Further, there is much confusion about how one should interpret the results from replications. Perhaps this is not surprising. There is still much controversy about how to interpret tests of hypotheses! At the very least, it is helpful to have a better understanding of the current state of replication practice, and how replicators understand their own research. It is hoped that this special issue will help to progress our understanding on these subjects.
To read more about the special issue, and how to contribute, click here.
[From an interview with Christopher Chartier and Randy McCarthy at Retraction Watch]
“Do researchers need a new “Craigslist?” We were recently alerted to a new online platform called StudySwap by one of its creators … The platform creates an “online marketplace” that previous researchers have called for, connecting scientists with willing partners – such as a team looking for someone to replicate its results, and vice versa.”
[From the article “Stop binning negative results, researchers told” at www.timeshighereducation.com] “A new Europe-wide code of research conduct has ordered academics and journals to treat negative experimental results as being equally worthy of publication as positive ones. … The new European Code of Conduct for Research Integrity frames the bias against negative results as an issue of research conduct, stipulating that ‘authors and publishers [must] consider negative results to be as valid as positive findings for publication and dissemination’.”
Reproducibility is not just an issue in economics. In a new book, “Rigor Mortis: How Sloppy Science Creates Worthless Cures, Crushes Hope, and Wastes Billions”, NPR science reporter Richard Harris describes and elaborates on the problem of irreproducibility for medical science. The website Retraction Watch caught up with Richard Harris to discuss his new book and his thoughts on the larger problem of “sloppy science.” To read the interview, click here.
[NOTE: This entry is based on the book “Corrupt Research: The Case for Reconceptualizing Empirical Management and Social Science” by Raymond Hubbard]
Psychology’s “reproducibility crisis” (Open Science Collaboration, 2015) has drawn attention to the need for replication research. However, focusing on the reproducibility of findings, while clearly important, is a much too narrow interpretation of replication’s role in the scientific enterprise. This account outlines some additional roles.
Based on the two dimensions of (1) data sources and (2) research methods, the table below lists six different kinds of replications, each with its own part to play.
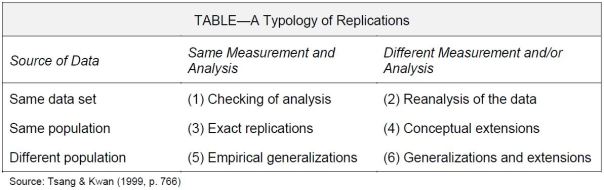
(1) Checking of Analysis: Determining the Accuracy of Results
Independent reexaminations of the original data, using the same methods of analysis. Are the results error-free?
(2) Reanalysis of Data: Determining Whether Results Hold Up Using Different Analytical Methods
Independent reexaminations of the original data, using different methods of analysis. Are the results the “same”?
Using the above approaches, many “landmark” results—e.g., the Hawthorne effect, J.B. Watson’s conditioning of Little Albert, Sir Cyril Burt’s “twins” research, and Durkheim’s theory of suicide—have been found to be invalid.
I do not consider (1) and (2) to be authentic forms of replication. They clearly, however, play a vital role in protecting the integrity of the empirical literature.
(3) Exact Replications: Determining Whether Results are Reproducible
An authentic form of replication, one which most people see as THE definition of replication. Here, we follow as closely as possible the same procedures used in the earlier study on a new sample drawn from the same population. This was the approach adopted by the Open Science Collaboration (2015) project.
(4) Conceptual Extensions: Determining Whether Results Hold Up When Constructs and Their Interrelationships are Measured/Analyzed Differently
These differences lie in how theoretical constructs are measured, and how they interrelate with other constructs. Conceptual extensions address the issue of the construct validity of the entities involved. This can only be done by replications assessing a construct’s (a) Convergent, (b) Discriminant, and (c) Nomological validities.
Otherwise expressed, replication research is crucial to theory development. First, it is replication research which is essential to the initial measurement, and further refinement, of the theoretical constructs themselves. Second, it is replication research which is responsible for monitoring the linkages (theoretical consistency) between these constructs. Third, it is replication research which judges the adequacy of this system of constructs for explaining some of what we see in the world around us.
(5) Empirical Generalizations: Determining Whether Results Hold Up in New Domains
Here the focus is on the external validity, or generalizability, of results when changes in persons, settings, treatments, outcomes, and time periods are made (Shadish, Cook, and Campbell, 2002). For example, Helmig, et al.’s (2012) successful replication using Swiss data of Jacobs and Glass’s (2002) U.S. study on media publicity and nonprofit organizations.
(6) Generalizations and Extensions: Determining Whether Results Hold Up in New Domains and With New Methods of Measurement and/or Analysis
Typically, these do not constitute authentic replications. Many of them are mainstream studies dealing with theory testing. That is, the emphasis is on theory extension, and not on extensions to previous empirical findings (Hubbard and Lindsay, 2002, p. 399).
Replication and Validity Generalization
Replication research underlies the validity generalization process.
Exact Replications allow appraisal of the internal validity of a study. They also enable the establishment of facts and the causal theories underlying them.
Conceptual Replications extend the development of causal theory by examining the validity of hypothetical constructs and their interrelationships. Specifically, they make possible the evaluation of a construct’s convergent, discriminant, and nomological validity. What could be more important than this?
Empirical Generalizations permit investigations of whether the same (similar) findings hold up across (sub)populations so addressing the neglected topic of a study’s external validity.
It is for good reason that replication research is said to be at the heart of scientific progress.
Raymond Hubbard is Thomas F. Sheehan Distinguished Professor of Marketing, Emeritus, at Drake University. Correspondence about this blog should be addressed to drabbuhyar@aol.com.
REFERENCES
Helmig, B., Spraul, K., & Tremp, K. (2012). Replication studies in nonprofit research: A generalization and extension of findings regarding the media publicity of nonprofit organizations. Nonprofit and Voluntary Sector Quarterly, 41, 360‑385.
Hubbard, R. (2016). Corrupt Research: The Case for Reconceptualizing Empirical Management and Social Science. (2016). Sage Publications: Thousand Oaks, CA.
Hubbard, R. & Lindsay, R.M. (2002). How the emphasis on “original” empirical marketing research impedes knowledge development. Marketing Theory, 2, 381‑402.
Jacobs, R.N. & Glass, D.J. (2002). Media publicity and the voluntary sector: The case of nonprofit organizations in New York City. Voluntas: International Journal of Voluntary and Nonprofit Organizations, 13, 235‑252.
Open Science Collaboration (2015). Estimating the reproducibility of psychological science. Science, 349, aac4716‑1‑8.
Shadish, W.R., Cook, T.D., & Campbell, D.T. (2002). Experimental and quasi-experimental designs for generalized causal inference. Houghton Mifflin: Boston, MA.
Tsang, E.W.K. & Kwan, K.-M. (1999). Replication and theory development in organizational science: A critical realist perspective. Academy of Management Review, 24, 759‑780.
It is well known that there is a bias towards publication of statistically significant results. In fact, we have known this for at least 25 years since the publication of De Long and Lang (JPE 1992):
“Economics articles are sprinkled with very low t-statistics – marginal significance levels very close to one – on nuisance coefficients. […] Very low t-statistics appear to be systematically absent – and therefore null hypotheses are overwhelmingly false – only when the universe of null hypotheses considered is the central themes of published economics articles. This suggests, to us, a publication bias explanation of our findings.” (pp. 1269-1270)
While statistically insignificant results are less “sexy”, they are often not less important. Failure to reject the null hypothesis can be interesting in itself, is a valuable data point in meta-analyses, or can indicate to future researchers where they are unlikely to find an effect. As McCloskey (2002) famously puts it:
“[…] statistical significance is neither necessary nor sufficient for a result to be scientifically significant.” (p. 54)
This problem is not unique to Economics but several other disciplines have moved faster than us to try and address it. For example, the following disciplines already have journals dedicated to publishing “insignificant” results:
Is it time for Economics to catch up? I suggest it is and I know that I am not alone in this view. In fact, a number of prominent Economists have endorsed this idea (even if they are not ready to pioneer the initiative). So, imagine… a call for papers along the following lines:
Series of Unsurprising Results in Economics (SURE)
Is the topic of your paper interesting, your analysis carefully done, but your results are not “sexy”? If so, please consider submitting your paper to SURE. An e-journal of high-quality research with “unsurprising” findings.
How does it work:
— We accept papers from all fields of Economics…
— Which have been rejected at a journal indexed in EconLit…
— With the ONLY important reason being that their results are statistically insignificant or otherwise “unsurprising”.
To document that your paper meets the above eligibility criteria, please send us all referee reports and letters from the editor from the journal where your paper has been rejected. Two independent referees will read these reports along with your paper and evaluate whether they indicate that: 1. the paper is of high quality and 2. the only important reason for rejection was the insignificant/unsurprising nature of the results. Submission implies that you (the authors) give permission to the SURE editor to contact the editor of the rejecting journal regarding your manuscript.
SURE benefits writers by:
— Providing an outlet for interesting, high-quality, but “risky” (in terms of uncertain results) research projects;
— Decreasing incentives to data-mine, change theories and hypotheses ex post, exclusively focus on provocative topics.
SURE benefits readers by:
— Mitigating the publication bias and thus complementing other journals in an effort to provide a complete account of the state of affairs;
— Serving as a repository of potential (and tentative) “dead ends” in Economics research.
Feedback is definitely invited! Please submit your comments here or email me at andrea.menclova@canterbury.ac.nz.
Andrea Menclova is a Senior Lecturer at the University of Canterbury in New Zealand.
REFERENCES:
De Long J. Bradford and Kevin Lang. 1992. “Are all Economic Hypotheses False?” Journal of Political Economy, 100:6, pp.1257-1272
McCloskey, Deirdre. 2002. The Secret Sins of Economics. Prickly Paradigm Press, Chicago.

You must be logged in to post a comment.