As part of a major replication and robustness project of articles in the American Economic Review, this fall I assigned students in my Masters Macro course at the New Economic School (Moscow) to replicate and test robustness for Macro papers published in the AER. In our sample of AER papers, 66% had full data available online, and the replicated results were exactly the same as in the paper 72% of the time. However, in all the remaining cases where the data and code were available were the results in the replication approximately the same. The robustness results were a bit less sanguine: students concluded that 65% of the papers were robust (primarily doing reanalysis rather than extensions), while t-scores fell by 31% on average in the robustness checks. While this work should be seen as preliminary (students had to work under tight deadlines), the results suggest that more work needs to be done on replication and robustness, which should be an integral part of the scientific process in economics.
The Assignment
First, each student could choose their own paper and try to replicate the results. The students were allowed to switch papers for any reason, such as if the data was not available or the code didn’t work. Then they had to write referee reports on their papers, suggesting robustness checks. Lastly, after a round of comments and suggestions from myself, students were to implement their robustness checks and report their results. They were also required to submit their data and code.
Replication Results
24 papers had the full data available, while 12 did not, for an impressive two-thirds ratio (similar to what Chang and Li, who test whether economics research is replicable, find, 23/35 in their case). Unfortunately, this is almost certainly an upper-bound estimate, as there may be selection given that students likely chose papers which looked easy to replicate. In addition, seven students switched away from their first-choice papers without necessarily reporting why in the google spreadsheet, and others likely switched between several papers just before the deadline in search of papers which were easy to replicate.
Next, in 23 out of 32 cases, when there was full or partial data available, the replication results were exactly the same. In the other nine cases, the results were “approximately” the same, for a fairly impressive 100% replicability ratio. While this is encouraging, a pessimist might note that in just 18 out of 32 papers was there full data and code available that gave exactly the same results as were found in the published version of the paper, and in 24/32 cases were there approximately the same results and full data.
Robustness Results
While virtually all the tables that had data replicated well, it cannot necessarily be said that the results proved particularly robust. Of the troopers in my class who made it through a busy quarter to test for robustness and filled in their results in the google sheet, just 15 out of 23 subjectively called the results of the original AER “robust”, with the average t-score falling by 31% (similar to an Edlin factor).
While, admittedly, some students might have felt incentivized to overturn papers by hook or crook, for example by running hundreds of robustness tests, this does not appear to be what happened. This is particularly the case since many of the robustness checks were premeditated in the referee reports. On average, students who reversed their results reported doing so on the 8th attempt.
If anything, with an exception of one or two cases, students seemed to be cautious about claiming studies were non-robust. One diligent student found a regression in a paper’s .do file – not reported in the main paper — in which the results were not statistically significant. However, the student also noted that the sample size in that particular regression shrank by one-third, and thus still gave the paper the benefit of the doubt. Other students often found that their papers’ had clearly heterogenous impacts by subsample, and yet were cautious enough to still conclude that the key results were robust on the full sample, even if not on subsamples. And, indeed, having insignificant results on a subsample may or may not be problematic, but at a minimum suggests further study is warranted.
“Geographic” Data Papers: Breaking Badly?
For papers that have economic data arranged geographically, such as papers which look at local labor market effects of a particular shock, or cross-country data, or data from individuals in different areas, the results appeared to be more grim. It often happened that different geographic regions would yield quite different results (not unlike this example from the QJE). Thus if one splits the sample, and then tests out-of-sample on the remaining data, the initial model often does not validate well. It might not be that the hypothesis is wrong, but it does make one wonder how well the results would test out of sample. The problem here seems to be that geography is highly-nonrandom, so that regressing any variable y (say, cat ownership) on any other variable x (marijuana consumption), one will find a correlation. (This is likely the force which gave rise to the rainfall IV.) However, often these correlations will reverse signs on different regions. Having a strong intuitive initial hypothesis here is important.
For example, one student chose a paper which argued for a large causal effect of inherited trust on economic growth – which a priori sounded to me like a dubious proposition. The student found that a simple dummy for former communist countries eliminated the significance of the result when added to one of the richer specifications in the paper.
Concluding Thoughts
Would this result, that 65% of the papers in the AER are robust, replicate? One wonders if the students had had more time, particularly enough time to do extensions in addition to reanalaysis, or if the robustness checks had been carried out by experienced professionals in the field, whether as many papers would have proven robust. In addition, students were probably more likely to choose famous papers – which may or may not be more likely than others to replicate. Thus, in the future we would like to do a random selection of papers to test robustness. In addition, I suspected from the beginning that empirical macro papers are likely to be relatively low-hanging fruit in terms of the difficulty of critiquing the methodology. This suspicion proved correct. While some papers were hard to find faults in, other papers were missing intuitive fixed effects or didn’t cluster, and one paper ran a panel regression in levels of trending variables without controlling for panel-specific trends (which changed the results).
I do believe this is a good exercise for students, conditioned on not overburdening them, a mistake I believe I made. The assignment requires students to practice the same skills – coding, thinking hard about identification, and writing – that empirical researches use when doing actual research.
On the whole, research published in the AER appears to replicate well, but it is still an open jury as to how robust the AER is. In my view, a robustness ratio of 15/23 = 65% is actually very good, and is a bit better than my initial priors. The evidence from this Russian study does seem to suggest, however, that research using geographic data published in the American Economic Review is no more robust than the American electoral process. This is an institution in need of further fine-tuning.
Douglas Campbell is an Assistant Professor at the New Economic School in Moscow. His webpage can be found at http://dougcampbell.weebly.com/.
Economics has become an empirical discipline. Applied econometrics has replaced mathematical economics in all but a few niche journals, and economists are collecting primary data again. But publication practices are lagging behind. Replication of a theoretical paper has never been an issue. You get out your pencil and paper and work through the proof of this or that theorem. Replication of empirical papers requires more consideration.
Led by the American Economic Association, an increasing number of economics journals demand that empirical papers be replicable. Data and code are archived with the paper. Efforts are now underway, by Mendeley and others, to make data and code searchable – papers, of course, have been searchable for a long time.
But replicability is not replication. Economics papers are replicated all the time, but the results are the subject of classroom discussions, online gossip, and whispers at conferences – rather than published formally. The profession rewards original contributions and looks down at derivative research. The former sentiment is fine but the latter is not. Not every paper can break new ground. Not every economist can win a Nobel Prize. The numbers matter, particularly in policy advice, and checking someone else’s results is important for building confidence in the predictions we make about the impact of policy interventions.
Energy economics is a subdiscipline of applied economics. Reliable, affordable and clean energy is fundamental to economic activity, social justice, and environmental quality. The results published in Energy Economics inform and shape energy policy. The results therefore had better be right. In this regard, energy economics is not different from health economics, labour economics, or education economics. Energy Economics takes replication sufficiently seriously to incentivise it.
Inviting replication papers is dangerous. Anyone can download the .dta and .do files for a paper, click a few buttons, and claim success. At Energy Economics, we are still wondering how to report successful replications, how to reward replicators, and how to tell genuine claims of successful replication from trivial or fake ones.
For the special issue of Energy Economics, we therefore opted to stretch the notion of replication. We call for papers that replicate and update important, but outdated papers. We call for papers that encompass and explain contrasting findings in previously published papers. Thus defined, replication is still derivative – there is no escape from that – but it is not intellectually barren. Replicators have to make an effort to get the reward, a publication in the top field journal.
This is an experiment. We hope to attract interesting replications. While there certainly has been a lot of interest, we will have to carefully study whether the submitted papers meet our expectations.
The experiment is not limited to Energy Economics. Elsevier wants to foster a new surge in reproducibility and reproduction. There are some perceived barriers to disseminating replication studies, such as that they are only valuable if the results disagree with the original research, or that editors don’t want to publish these studies. We want to break these myths. Elsevier are now working on a range of initiatives that raise the bar on reproducibility and lower the barriers for researchers to publish replication studies, including a series of Virtual Special Issues, a new article type especially for replication studies, and various calls for papers (the first one in Energy Economics) to encourage submissions. By empowering researchers to share their methods and data, championing rigorous and transparent reporting and creating outlets for replication research, Elsevier is helping to make reproducibility and replication a reality.
Making sure (published) research can be reproduced is a massive step towards making it trustworthy and showing peers, funders and the public that science can be trusted. Publishing replication studies contributes to building this trust, ultimately safeguarding science.
Richard Tol is the Editor-in-Chief of Energy Economics. He teaches at the University of Sussex and the Vrije Universiteit Amsterdam. Donna de Weerd-Wilson is the Executive Publisher of Energy Economics, and manages one of the Economics portfolios at Elsevier.
[From the website of the Berkeley Institute of Transparency in the Social Sciences — BITSS] The ten recipients are:
— “Dr. ERIC-JAN WAGENMAKERS, Professor of Mathematical Psychology at the University of Amsterdam and widely recognized pioneer in promoting reproducible research”
— “Dr. LORENA BARBA, Associate Professor of Mechanical and Aerospace Engineering at George Washington University and creator of the lauded online course on numerical methods in scientific computing”
— “Dr. ZACHARIE TSALA DIMBUENE, a researcher at the African Population and Health Research Center (APHRC) in Kenya. Dr. Tsala Dimbuene led a transparency workshop as a BITSS Catalyst at the University of Kinshasa, and is advancing open science training efforts in francophone Africa.”
— “Dr. ABEL BRODEUR, Assistant Professor of Economics at the University of Ottawa, well-known for co-authoring “Star Wars: The Empirics Strike Back,” an analysis of p-value misallocation in economics”
— “Dr. FELIX SCHÖNBRODT, a post-doctoral researcher at Ludwig-Maximillians-Universität in Munich and leader in developing transparency and data sharing standards for psychologists”
— “Dr. ELAINE TOOMEY, a post-doctoral researcher at the National University of Ireland Galway focused on implementation fidelity in the health sciences”
— “Dr. GRAEME BLAIR, Assistant Professor of Political Science at UCLA and co-creator of DeclareDesign, a suite of research design evaluation software”
— “BETH BARIBAULT, a doctoral student in the Cognitive Sciences at UC Irvine whose research represents extraordinary dedication to transparency and replicability”
— “MICHÈLE NUIJTEN of Tilburg University and Dr. SACHA EPSKAMP of the University of Amsterdam whose development of statcheck has attracted attention from Nature“
To read more about the awards, click here.
Does it make sense for an academic to put effort in replicating another study? While reading a paper in Political Analysis (Katz, 2001[1]) in 2005, I noticed a strange thing. In that paper, the author uses simulations to check how biased estimates are if one estimates fixed effects in a logit model by including fixed effects dummies rather than doing conditional logit.
However, the way the author described the fixed effects in the paper suggested that he assumed all fixed effects were equal. This, in fact, means there are no fixed effects, as equal fixed effects are just like a constant term. The author’s Stata code confirmed he indeed generated a ‘true’ model without fixed effects and hence the article’s interpretation was different from what it was actually doing. I fixed the code, re-ran the simulation and wrote up a correction which was also published in Political Analysis (Coupé, 2005[2]). The author in his reply admitted the issue (Katz, 2005[3]).
These two articles, Katz (2001) and Coupé (2005) thus provide a clean experiment to assess how a successful replication affects citations of both the replication and the original paper. Both papers were published in the same journal. Katz’s reply (Katz, 2005) shows the author of the original paper agrees with the flaw in the analysis of Katz (2001) so there is no uncertainty about whether the replication or the original is incorrect. And the flaw is at the core of the analysis in Katz (2001). In most replications, only parts of the analyses are shown to be incorrect or not replicable so subsequent citations might refer to the ‘good’ parts of the paper.
I used Google search to find citations of Katz (2001) and Coupé (2005) and then eliminated the citations coming from multiple versions of the same papers. The table below gives the results.
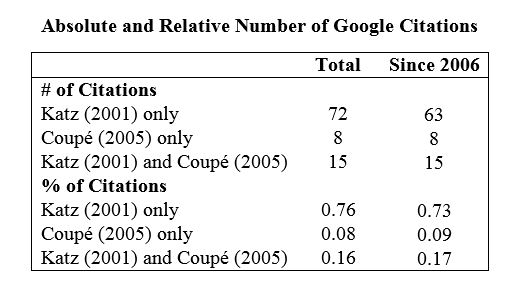
The table shows that even after publication of the correction, more than 70% of citing papers only cite the Katz study. This remains true even if one restricts the sample to citations from more than 5 years after the publication of the correction.
I also investigated how those papers that cite both Katz (2001) and Coupé (2005) cite these papers. I could find the complete text for 13 out of 15 such papers. None indicates the issue with the Katz (2001) study, instead both studies are used as examples of studies that find one can include fixed effects dummies in a logit regression if the number of observations per individual is sufficiently big. While both studies indeed come to that conclusion, the Katz (2001) study could not make that claim based on the analysis it did. This suggest that even those people who at least knew about the Coupé (2005) article also did not really care about this fact.
While the fact that many people continue to cite research that has been shown to be seriously flawed is possibly disappointing, this should not come as a surprise. Retraction Watch (2015) has a league table of citations given to papers after they have been retracted.
Further, my experience is consistent with the results of Hubbard and Armstrong (1994). They find that “Published replications do not attract as many citations after publication as do the original studies, even when the results fail to support the original studies.” In other words, even after the replication has been published, the original article continues to be cited more frequently than the replication. This is true even when the results from the original study were overturned by the replication.
Citations are only one measure of “worth.” But my experience, and the evidence from Hubbard and Armstrong (1994), suggest that replicated research is not valued as highly by the discipline as original research. Which may be one reason why so little replication research is done.
REFERENCES
Coupé, T. (2005). Bias in conditional and unconditional fixed effects logit estimation: A correction. Political Analysis, Vol. 13: 292-295.
Hubbard, R. and Armstrong, J.S. (1994). Replications and extensions in marketing – rarely published but quite contrary. International Journal of Research in Marketing, Vol. 11: 233-248.
Katz, E. (2001). Bias in conditional and unconditional fixed effects logit estimation. Political Analysis, Vol. 9: 379-384.
Katz, E. (2001). Response to Coupé. Political Analysis, Vol. 13: 296-296.
Tom Coupé is an Associate Professor of Economics at the University of Canterbury, New Zealand.
[1] Abstract of Katz (2001): “Fixed-effects logit models can be useful in panel data analysis, when N units have been observed for T time periods. There are two main estimators for such models: unconditional maximum likelihood and conditional maximum likelihood. Judged on asymptotic properties, the conditional estimator is superior. However, the unconditional estimator holds several practical advantages, and therefore I sought to determine whether its use could be justified on the basis of finite-sample properties. In a series of Monte Carlo experiments for T < 20, I found a negligible amount of bias in both estimators when T ≥ 16, suggesting that a researcher can safely use either estimator under such conditions. When T < 16, the conditional estimator continued to have a very small amount of bias, but the unconditional estimator developed more bias as T decreased.”
[2] Abstract of Coupe (2005). “In a recent paper published in this journal, Katz (2001) compares the bias in conditional and unconditional fixed effects logit estimation using Monte Carlo Simulation. This note shows that while Katz’s (2001) specification has ‘‘wrong’’ fixed effects (in the sense that the fixed effects are the same for all individuals), his conclusions still hold if I correct his specification (so that the fixed effects do differ over individuals). This note also illustrates the danger, when using logit, of including dummies when no fixed effects are present”.
[3] Katz’ (2005) reply. “I agree with the author’s main point. Although I tried to fit a fixed-effects model to the simulated data, those data were generated from a model without fixed effects. In my experiment, therefore, use of the unconditional estimator was perfectly confounded with misspecification of the model. I thank the author for catching this flaw.”
The journal Energy Economics announced it was putting on a special issue dedicated to replications. While all types of replications are invited, two types are of particular interest. First, replications of older research that has been widely cited or influential in policy making. This type of replication would investigate whether the original results are sustained when newer data are added and/or newer methods are applied. The second type of replication would attempt to reconcile findings from several papers that use similar data but reach different conclusions.
No deadline for the special issue was announced. In addition, Energy Economics also announced that it will now accept replications as a distinct submission type. To learn more, click here.
[From the blog, “Reproducibility Crisis Timeline: Milestones in Tackling Research Reliability” by Hilda Bastian at her PLoS blogsite, Absolutely Maybe] “It’s not a new story, although “the reproducibility crisis” may seem to be. For life sciences, I think it started in the late 1950s. Problems caused in clinical research burst into the open in a very public way then….Here are some of the milestones in awareness and proposed solutions that stick out for me.” To read more, click here.
[From the article “Peer review post-mortem: how a flawed aging study was published in Nature“, posted at the website, nrc.nl] “How could an article with numerous shortcomings be published in top-tier journal Nature? Hester van Santen reveals how the gate-keepers of science knowingly let flawed research slip through.” To read more, click here.
Data sources are regularly updated. Users typically assume that this means that new, more recent data are added and that errors are corrected. Newer data are better. But are they? And what are the implications for replication? This guest blog points out challenges and potential benefits of the existence of different data versions.
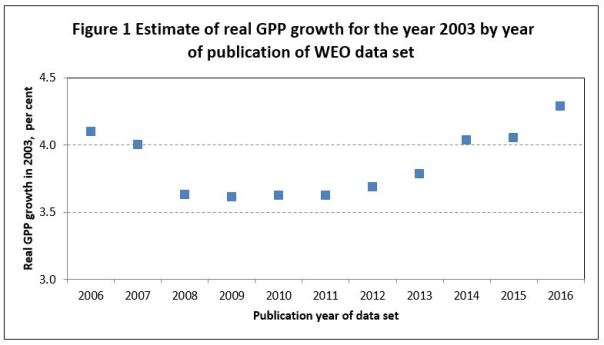
Often unnoticed, economic history is constantly being rewritten. This results in different vintages or versions of data. By way of illustration Figure 1 reports the real rate of growth of GPP (Gross Planet Product; see van Bergeijk 2013) for the year 2003. The 11 data versions have been reported in 2006-2016 alongside the IMF flagship publication World Economic Outlook (the so-called October version). The lowest number reported for 2003 was published in 2009 (3.61%). The highest value for the 2003 growth rate (4.29%) was published in 2016. The reported growth rate for the year 2003 varies thus by 0.68 percentage points between the different data versions. This is an economically relevant difference of 16 to 19% depending on whether one uses the highest or lowest growth rate to calculate the percentage.
Revising without and with transparency
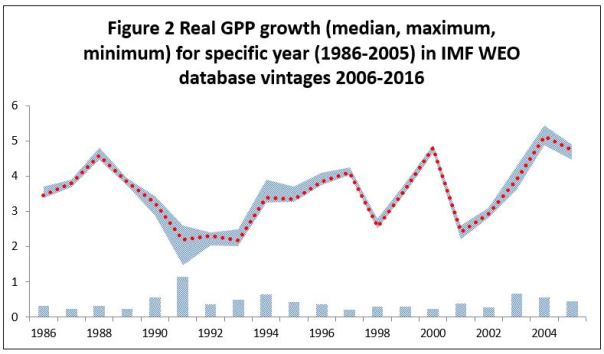
Figure 2 illustrates that this variation for historical data is a regular phenomenon in the IMF World Economic Outlook data base. Using the same 11 data versions above, the figure reports the minimum and maximum (bar and grey area) and the median GPP growth rate (dotted line) for the years 1986-2005. Consider the different GPP growth rates reported for the year 1991 across the different vintages. Despite the fact that all the data vintages were published at least 25 years after the event, the variation in reported GPP values for 1991 differ by as much as 1.1 percentage points (or 50% of the median value). While this is the largest variation in the figure, several of the ‘revisions’ for other years are also substantial.
The IMF’s opaqueness is perhaps exceptional. Other leading data sources such as the World Bank’s World Development Indicators or the Penn World Tables do report changes in methodology, estimates and underlying series transparently and in detail. The point is that these data that are used on a daily basis by many analysts and researchers are likely to change after an analysis has been done and published.
Challenges for replication research
Obviously the constant rewriting of historical data is a challenge for replication. For exact replication it is important to know which version of data was used. Although many authors report the data source, the version and the date accessed, other scientists may only report the source and, possibly, year of publication. In order to undertake an exact replication, replicating authors may need to contact authors of the original studies in order to use the identical vintage. For replication designs that want to test if the reported findings continue to hold for longer time spans (and include more recent data) a de-composition may be necessary to find out what part of the estimated effect is due to the new vintage and what to the more recent data.
Potential benefits for replication research
Variations between the different vintages of a data set are not necessarily problematic. Variations provide insight in the measurement error in the data source. A better understanding of measurement error may be helpful for establishing why a replication fails or succeeds. Moreover, performing replications over many different vintages can support the robustness of the original study’s findings. If all the data versions arrive at the same conclusion, this strengthens confidence in the replication’s verdict on the original study (be it positive or negative). It is not the difference of the data version that matters, but the similarity of findings across different data versions. As a result, different data versions can be turned into an important asset for replication research.
Reference
Bergeijk, P.A.G. van, Earth Economics: An Introduction to Demand Management, Long-Run Growth and Global Economic Governance, Edward Elgar: Cheltenham, 2013
Peter A.G. van Bergeijk is professor of international economics and macroeconomics at the Institute of Social Studies, Erasmus University. More information can be found here: http://www.petervanbergeijk.org/.
On September 29, a public debate was held on the campus of NYU. The subject of the debate was “Do Replication Projects Cast Doubt On Many Published Studies in Psychology?” The debate pitted Brian Nosek, director of the Center for Open Science and a leading advocate of the importance of replication, against Jason Mitchell, a professor in the Department of Psychology at Harvard. To read a summary of the debate, click here.
[From the article “Why Fake Data When You Can Fake a Scientist?”] “Hoss Cartwright, a former editor of the International Journal of Agricultural Innovations and Research, had a good excuse for missing the 5th World Congress on Virology last year: He doesn’t exist. Burkhard Morgenstern, a professor of bioinformatics at the University of Gottingen, dreamt him up, and built a nice little scientific career for him. He wrote Cartwright a Curriculum Vitae, describing his doctorate in Studies of Dunnowhat, his rigorous postdoctoral work at Some Shitty Place in the Middle of Nowhere, and his experience as Senior Cattle Manager at the Ponderosa Institute for Bovine Research. Cartwright never published a single research paper, but he was appointed to the editorial boards of five journals.” To read more, click here.
Fake Authors. Fake Data. Fake Journals. Fake Reviewers. Fake Citations. One could get discouraged. Maybe this is a good time to note that replications could help.

You must be logged in to post a comment.