The Replication Network
Furthering the Practice of Replication in Economics
Exciting Collaboration Opportunity with the SCORE Team at COS
The SCORE team at the Center for Open Science (COS) is looking for committed individuals to help conduct data-analytic replications (DARs) and reproductions.
In general, DARs involve using new data and the same methodological and analytic approach that was used in the original study to replicate the claim identified by SCORE, producing the statistical evidence found in “claim 4” (one or more inferential tests or pieces of statistical evidence). For DARs, collaborators may use different data sources or the same data sources as the original study (e.g., longitudinal dataset, U.S. Census, etc), however the observations used in the replication must be distinct from the observations used in the original study (e.g., newer waves of the same longitudinal dataset, a newer version of the U.S. Census, etc).
Reproductions involve using the original data and the same analytic approach that was used in the original study to reproduce the inferential test(s) or statistical evidence identified by SCORE in “claim 4.”
Reproduction types
Within the SCORE program, there are 3 types of reproductions
1) Push Button Reproduction (PBR): Uses the original data and the original analytic code (either shared from the original authors or collected from an online repository/journal website). If a PBR fails to produce sensible output, you will conduct an Author-Data reproduction.
2) Author Data Reproduction (ADR): Uses the original data (either shared from the original authors or collected from an online repository/journal website) and new/revised analytic code generated by the SCORE collaborator.
3) Source Data Reproduction (SDR), applicable when the original study used existing data: The SCORE collaborator reconstructs the dataset used in the original analysis (by using information from the original paper and any additional information from the original author) and generates new analytic code.
The data-analytic replications and each of the three types of reproductions are further broken down based on the method of claim extraction:
– Single-trace papers: Only a single claim trace is extracted from the article which includes exactly one statistically significant inferential test result.
– Bushel papers: As many independent claim traces are extracted as possible, which may include non-inferential quantitative evidence, non-significant evidence, and multiple inferential test results in the same claim.
How to get involved
You will self select into a project-analysis type using the sign-up sheet linked below before completing a form to confirm your interest and timeline feasibility. You will see that the commitment form corresponding to each project is linked directly in the spreadsheet.
If you sign-up for a bushel reproduction/replication, you will commit to reproducing/replicating as many claims as possible, aiming for at least 5 unless fewer claims are included in the bushel claims spreadsheet.
If you are interested in executing a data-analytic replication (DAR) or a reproduction, please review the in-depth instructions linked below and claim papers using this SIGN-UP SHEET. When you claim a project, be sure to also complete the commitment form linked in the sign-up sheet. High priority projects are highlighted in green.
For bushel papers, the columns ‘has replication’ and ‘has reproduction’ indicate whether or not at least one analysis has already been performed within the context of the SCORE program. Those projects with ‘TRUE’ in this field will be easier to complete because we likely have relevant materials in hand.
If you would like to review what data and materials we’ve already collected for a given project, if anything, please let us know and we will provide a view-only link.
You may review general instructions and expectations for each project type linked below. When you complete the commitment form and are matched to a project, you will receive access to the corresponding OSF project, your preregistration form, and any other relevant materials.
Bushel claim spreadsheets can be found in the OSF project linked in the sign-up sheet. If you are interested, please follow the link, review the project wiki, and click the paper from among the full list of bushel papers included in the project.
Note that you should attempt to access all of the necessary data after signing up but before completing the commitment form. Please do not reach out to any of the original authors directly; if you suspect that the data is readily available but require assistance to access it (e.g., original author contact, funding to access the data, etc.) please reach out to us after you’ve added your name to the sign-up sheet.
Privacy Statement: Other teams are making predictions about the outcomes of many different studies, not knowing which studies have been selected for replication/reproduction. As a consequence, the success of this project requires full confidentiality of the research process. This includes privacy about which studies have been selected for replication and all aspects of the discussion about these replication designs.
IREE Scores a Top Score in TOP Factor
The International Journal for Re-Views in Empirical Economics (IREE) is the only journal in economics solely dedicated to publishing replications. Recently, IREE was evaluated by TOP Factor. TOP Factor is an initiative launched by the Center for Open Science to assess journals according to “a values-aligned rating of journal policies as a counterweight to metrics that incentivize journals to publish exciting results regardless of credibility” (see here). The assessment of IREE‘s journal policies resulted in a journal score of 13 points. This puts IREE in 4th place among all 136 economic journals rated by TOP Factor, ahead of the American Economic Review, Econometrica, Plos One, and Science.
TOP Factor provides an alternative to metrics such as the journal impact factor (JIF). It constitutes a first step towards evaluating journals based on their quality of process and implementation of scholarly values. “Too often, journals are compared using metrics that have nothing to do with their quality,” says Evan Mayo-Wilson, Associate Professor in the Department of Epidemiology and Biostatistics at Indiana University School of Public Health-Bloomington. “The TOP Factor measures something that matters. It compares journals based on whether they require transparency and methods that help reveal the credibility of research findings.” (see COS announcement of TOP factor, 2020).
TOP Factor is based on the Transparency and Openness Promotion (TOP) Guidelines, a framework of eight standards that summarize behaviors that can improve transparency and reproducibility of research such as transparency of data, materials, code, and research design, preregistration, and replication.
Editor Martina Grunow announced that she was very pleased with this rating, as TOP Factor reflects exactly what IREE stands for: reducing the publication bias towards literally incredible and non-reproducible results and the resulting “publish-or-perish” culture. Like TOP Factor, IREE promotes the reproducibility and transparency of published results and scientific discourse in economics based on high-quality and credible research results.
Fudging Data About Dishonesty
[Excerpts are taken from the blog “Evidence of Fraud in an Influential Field Experiment About Dishonesty” posted by Uri Simonsohn, Joe Simmons, Leif Nelson and anonymous researchers at Data Colada]
“This post is co-authored with a team of researchers who have chosen to remain anonymous. They uncovered most of the evidence reported in this post.”
“In 2012, Shu, Mazar, Gino, Ariely, and Bazerman published a three-study paper in PNAS reporting that dishonesty can be reduced by asking people to sign a statement of honest intent before providing information (i.e., at the top of a document) rather than after providing information (i.e., at the bottom of a document).”
“In 2020, Kristal, Whillans, and the five original authors published a follow-up in PNAS entitled, “Signing at the beginning versus at the end does not decrease dishonesty”.
“Our focus here is on Study 3 in the 2012 paper, a field experiment (N = 13,488) conducted by an auto insurance company … under the supervision of the fourth author. Customers were asked to report the current odometer reading of up to four cars covered by their policy.”
“The authors of the 2020 paper did not attempt to replicate that field experiment, but they did discover an anomaly in the data…our story really starts from here, thanks to the authors of the 2020 paper, who posted the data of their replication attempts and the data from the original 2012 paper.”
“A team of anonymous researchers downloaded it, and discovered … very strong evidence that the data were fabricated.”
“Let’s start by describing the data file. Below is a screenshot of the first 12 observations:”

“You can see variables representing the experimental condition, a masked policy number, and two sets of mileages for up to four cars. The “baseline_car[x]” columns contain the mileage that had been previously reported for the vehicle x (at Time 1), and the “update_car[x]” columns show the mileage reported on the form that was used in this experiment (at Time 2).”
“On to the anomalies.”
Anomaly #1: Implausible Distribution of Miles Driven
“Let’s first think about what the distribution of miles driven should look like…we might expect…some people drive a whole lot, some people drive very little, and most people drive a moderate amount.”
“As noted by the authors of the 2012 paper, it is unknown how much time elapsed between the baseline period (Time 1) and their experiment (Time 2), and it was reportedly different for different customers. … It is therefore hard to know what the distribution of miles driven should look like in those data.”
“It is not hard, however, to know what it should not look like. It should not look like this:”
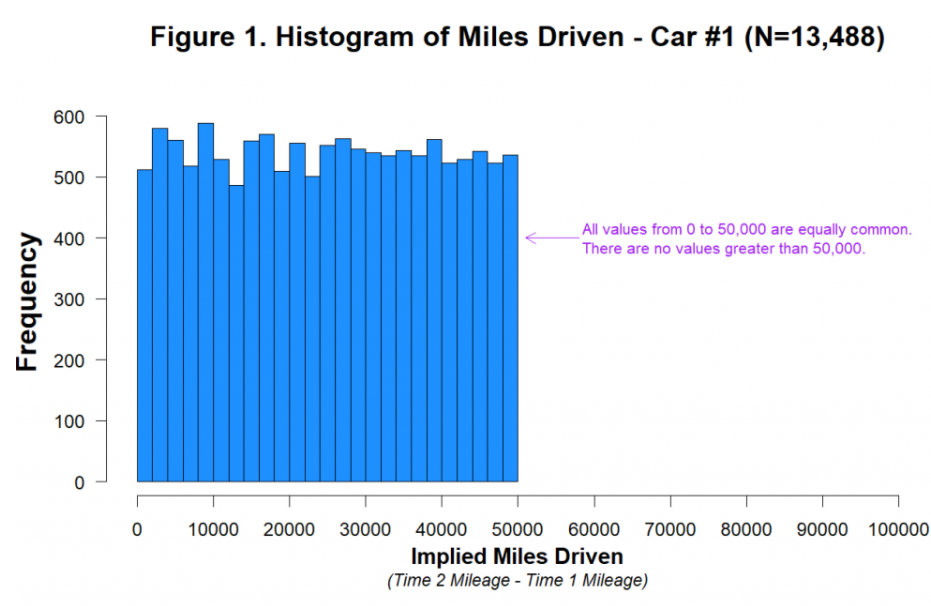
“First, it is visually and statistically (p=.84) indistinguishable from a uniform distribution ranging from 0 miles to 50,000 miles. Think about what that means. Between Time 1 and Time 2, just as many people drove 40,000 miles as drove 20,000 as drove 10,000 as drove 1,000 as drove 500 miles, etc. This is not what real data look like, and we can’t think of a plausible benign explanation for it.”
“Second, there is some weird stuff happening with rounding…”
Anomaly #2: No Rounded Mileages At Time 2
“The mileages reported in this experiment … are what people wrote down on a piece of paper. And when real people report large numbers by hand, they tend to round them.”
“Of course, in this case some customers may have looked at their odometer and reported exactly what it displayed. But undoubtedly many would have ballparked it and reported a round number.”
“In fact, as we are about to show you, in the baseline (Time 1) data, there are lots of rounded values.”
“But random number generators don’t round. And so if, as we suspect, the experimental (Time 2) data were generated with the aid of a random number generator (like RANDBETWEEN(0,50000)), the Time 2 mileage data would not be rounded.”

“The figure shows that while multiples of 1,000 and 100 were disproportionately common in the Time 1 data, they weren’t more common than other numbers in the Time 2 data.”
“These data are consistent with the hypothesis that a random number generator was used to create the Time 2 data.”
“In the next section we will see that even the Time 1 data were tampered with.”
Interlude: Calibri and Cambria
“Perhaps the most peculiar feature of the dataset is the fact that the baseline data for Car #1 in the posted Excel file appears in two different fonts. Specifically, half of the data in that column are printed in Calibri, and half are printed in Cambria.”
“The analyses we have performed on these two fonts provide evidence of a rather specific form of data tampering.”
“We believe the dataset began with the observations in Calibri font. Those were then duplicated using Cambria font. In that process, a random number from 0 to 1,000 (e.g., RANDBETWEEN(0,1000)) was added to the baseline (Time 1) mileage of each car, perhaps to mask the duplication.”
“In the next two sections, we review the evidence for this particular form of data tampering.”
Anomaly #3: Near-Duplicate Calibri and Cambria Observations
“…the baseline mileages for Car #1 appear in Calibri font for 6,744 customers in the dataset and Cambria font for 6,744 customers in the dataset. So exactly half are in one font, and half are in the other. For the other three cars, there is an odd number of observations, such that the split between Cambria and Calibri is off by exactly one (e.g., there are 2,825 Calibri rows and 2,824 Cambria rows for Car #2).”
“… each observation in Calibri tends to match an observation in Cambria.”
“To understand what we mean by “match” take a look at these two customers:”

“The top customer has a “baseline_car1” mileage written in Calibri, whereas the bottom’s is written in Cambria. For all four cars, these two customers have extremely similar baseline mileages.”
“Indeed, in all four cases, the Cambria’s baseline mileage is (1) greater than the Calibri mileage, and (2) within 1,000 miles of the Calibri mileage. Before the experiment, these two customers were like driving twins.”
“Obviously, if this were the only pair of driving twins in a dataset of more than 13,000 observations, it would not be worth commenting on. But it is not the only pair.”
“There are 22 four-car Calibri customers in the dataset. All of them have a Cambria driving twin…there are twins throughout the data, and you can easily identify them for three-car, two-car, and unusual one-car customers, too.”
“To see a fuller picture of just how similar these Calibri and Cambria customers are, take a look at Figure 5, which shows the cumulative distributions of baseline miles for Car #1 and Car #4.”
“Within each panel, there are two lines, one for the Calibri distribution and one for the Cambria distribution. The lines are so on top of each other that it is easy to miss the fact that there are two of them:”

Anomaly #4: No Rounding in Cambria Observations
“As mentioned above, we believe that a random number between 0 and 1,000 was added to the Calibri baseline mileages to generate the Cambria baseline mileages. And as we have seen before, this process would predict that the Calibri mileages are rounded, but that the Cambria mileages are not.”
“This is indeed what we observe:”

Conclusion
“The evidence presented in this post indicates that the data underwent at least two forms of fabrication: (1) many Time 1 data points were duplicated and then slightly altered (using a random number generator) to create additional observations, and (2) all of the Time 2 data were created using a random number generator that capped miles driven, the key dependent variable, at 50,000 miles.”
“We have worked on enough fraud cases in the last decade to know that scientific fraud is more common than is convenient to believe… There will never be a perfect solution, but there is an obvious step to take: Data should be posted.”
“The fabrication in this paper was discovered because the data were posted. If more data were posted, fraud would be easier to catch. And if fraud is easier to catch, some potential fraudsters may be more reluctant to do it. … All of our journals should require data posting.”
“Until that day comes, all of us have a role to play. As authors (and co-authors), we should always make all of our data publicly available. And as editors and reviewers, we can ask for data during the review process, or turn down requests to review papers that do not make their data available.”
“A field that ignores the problem of fraud, or pretends that it does not exist, risks losing its credibility. And deservedly so.”
To read the full blog, click here.
Replication Leads to High Profile Retraction
[Excerpts are taken from the article “Retracted: Risk Management in Financial Institutions” “ by Adriano Rampini, S. Viswanathan, and Guillaume Vuillemey, published in the Journal of Finance]
“The authors hereby retract the above article, published in print in the April 2020 issue of The Journal of Finance. A replication study finds that the replication code provided in the supplementary information section of the article does not reproduce some of the central findings reported in the article.”
“Upon reexamination of the work, the authors confirmed that the replication code does not fully reproduce the published results and were unable to provide revised code that does. Therefore, the authors conclude that the published results are not reliable and that the responsible course of action is to retract the article and return the Brattle Group Distinguished Paper Prize that the article received.”
Last Call for Metascience 2021 Submissions
FROM THE METASCIENCE 2021 ORGANIZING COMMITTEE:
You’re invited to submit an event or lightning talk proposal to the Metascience 2021 Conference by this Wednesday, June 30 to help contribute to the enrichment of attendees’ perspectives of the field of metascience. Take a moment to view full submission criteria and tips at metascience2021.org/submit.
Metascience 2021 will explore the themes of metascience and the scientific process through a global, interdisciplinary, cross-sector lens. This year’s virtual format takes place across time zones at peak hours to promote voices in metascience across regions.
Thank you for considering this opportunity to be a part of the global metascience discussion to advance scientific progress.

Open Invitation to the Webinar Launch of the InSPiR2eS International Research Alliance
InSPiR2eS is a new global research network primarily aimed at research training and capacity building, resting on a foundation theme of responsible science (for some more details, please refer to the 2-pager outline here).
Whether you are a current network member or not, you are warmly invited to the 1-hour webinar launch of the network taking place during the window, 22-24th June.
For your convenience, the Zoom launch is offered in 3 separate repeat events summarised below (please see here for a doc that gives more details confirming equivalent dates/times for your part of the world):
#1: Tuesday 22nd June at 18:00 Australian Eastern Standard Time (AEST)
Topic: Robert Faff’s Zoom Meeting #1 launching InSPiR2eS
Join from a PC, Mac, iOS or Android: https://bond.zoom.us/j/91798395671
#2: Wednesday 23rd June at 15:00 AEST
Topic: Robert Faff’s Zoom Meeting #2 launching InSPiR2eS
Join from a PC, Mac, iOS or Android: https://bond.zoom.us/j/99592757933
#3: Thursday 24th June at 06:00 AEST
Topic: Robert Faff’s Zoom Meeting #3 launching InSPiR2eS
Join from a PC, Mac, iOS or Android: https://bond.zoom.us/j/92796833442
If you are interested in joining the Zoom launch of InSPiR2eS, please register ASAP at the Google Docs link here.
Finally, please share this open invitation with whomever you think might be interested. Thank you!
repliCATS is Back!
About the repliCATS project
Based at the University of Melbourne, the repliCATS project team are part of a wider program called SCORE funded by DARPA. We are excited about reimagining peer review as a structured deliberation process. We’re testing this by crowdsourcing expert judgements about the credibility of published research in eight social science disciplines – criminology, education, economics, marketing, management, political science, psychology, public administration, and sociology.

repliCATS workshops – get paid to do post-publication peer review!
In workshops you will be asked to evaluate the credibility of two to three published papers within your domain expertise. We use a structured group deliberation approach called the IDEA protocol on a custom-built web-based platform which means you can participate from anywhere in the world! Working in small groups, you will be asked to evaluate papers across a number of credibility signals – from its comprehensibility, to its replicability, robustness and transparency.
Participants will first make private judgements about the paper, and then get to review and discuss their group’s responses before submitting their final judgements. For these workshops, we’ll group you by compatible time zones, and each group will have its own facilitator who will guide you through a short virtual discussion.
All participants are eligible for a US$200 assessment grant.
Your time commitment
Workshops will run over a period of 7 days, but you get to make your judgements when it suits you over that period. Here is how it works:
1) Consent & demographics, and create repliCATS platform account before the workshop: 20-25 minutes.
2) Workshop introduction: 45 mins, a number of live webinars run by the repliCATS team. Also recorded and can be watched on demand.
3) Assessment period: 45-70 minutes/paper at your own pace over the 7-day assessment period.
4) Group discussion: 30-45 minutes during the 7-day assessment period, dedicated facilitator will guide discussion.
5) Assessment grant administration: 5-10 minutes.
Sign-ups now open for July, August & September workshops
20-27 July – economics, marketing & management (35-40 participants)
24-31 August – Criminology, Political Science & Sociology (35-40 participants)
21-28 September – Criminology, Political Science, Public administration (government and law) & Sociology (35-40 participants)
Sign-up here: https://replicats.research.unimelb.edu.au/2021/06/02/express-interest-now-open-jul-sept-bushel-workshops/
Have questions? E-mail us at repliCATS-project@unimelb.edu.au
DUAN & REED: How Are Meta-Analyses Different Across Disciplines?
INTRODUCTION
Recently, one of us gave a workshop on how to conduct meta-analyses. The workshop was attended by participants from a number of different disciplines, including economics, finance, psychology, management, and health sciences. During the course of the workshop, it became apparent that different disciplines conduct meta-analyses differently. While there is a vague awareness that this is the case, we are unaware of any attempts to quantify those differences. That is the motivation for this blog.
We collected recent meta-analyses across a number of different disciplines and recorded information on the following characteristics:
– Size of meta-analysis sample, measured both by number of studies and number of estimated effects included in the meta-analysis
– Type of effect size
– Software package used
– Procedure(s) used to estimate effect size
– Type of tests for publication bias
– Frequency that meta-analyses report (i) funnel plots, (ii) quantitative tests for publication bias, and (iii) meta-regressions.
Unfortunately, given the large number of meta-analyses, and large number of disciplines that do meta-analyses, we were unable to do an exhaustive analysis. Instead, we chose to identify the disciplines that publish the most meta-analyses, and then analyse the 20 most recent meta-analyses published in those disciplines.
LITERATURE SEARCH
To conduct our search, we utilized the library search engine at our university, the University of Canterbury. This search engine, while proprietary to our university, allowed us to simultaneously search multiple databases by discipline (see below).

We conducted our search in January 2021. We used the keyword “meta-analysis”, filtering on “Peer-reviewed” and “Journal article”, and restricted our search depending on publication date. A total of 58 disciplines were individually searchable, including Agriculture, Biology, Business, Economics, Education, Engineering, Forestry, Medicine, Nursing, Physics, Political Science, Psychology, Public Health, Sociology, Social Welfare & Social Work, and Zoology.
Of the 58 disciplines we could search on, 18 stood out as publishing substantially more meta-analyses than others. These are listed below. For each discipline, we then searched for all meta-analyses/”Peer-reviewed”/”Journal article” that were published in January 2021, sorted by relevance. We read through the title and abstract until we found 20 meta-analyses. If January 2021 produced less than meta-analyses for a given discipline, we extended the search back to December 2020. In this manner, we constructed a final sample of 360 meta-analyses. The results are reported below.
NUMBER OF STUDIES
TABLE 1 below reports mean, median, and minimum number of studies for each sample of 20 meta-analyses corresponding to the 18 disciplines. Maximum values are indicated by green shading. Minimum values are indicated by blue.
The numbers indicate wide differences across disciplines in the number of studies included in a “typical” meta-analysis. Business meta-analysis tend to have the largest number of studies with mean and median values of 87.6 and 88 studies, respectively. Ecology and Economics also typically include large numbers of studies.
On the other side, disciplines in the health sciences (Dentistry, Diet & Clinical Nutrition, Medicine, Nursing, and Pharmacy, Therapeutics & Pharma) include relatively few studies. The mean and median number of studies included in meta-analyses in Diet & Clinical Nutrition are 13.9 and 11; and 14.8 and 10 for Nursing, respectively. We even found a meta-analysis in Dentistry that only included 2 studies.

NUMBER OF EFFECTS
Meta-analyses differ not only in number of studies, but the total number of observations/estimated effects they include. In some fields, it is common to include a representative effect, or the average effect from that study. Other disciplines include extensive robustness checks, where the same effect is estimated multiple times using different estimation procedures, variable specifications, and subsamples. Similarly, there may be multiple measures of the same effect, sometimes included in the same equation, and these produce multiple estimates.
Measured by number of estimated effects, Agriculture has the largest meta-analyses with mean and median sample sizes of 934 and 283. Not too far behind are Economics and Business. These three disciplines are characterized by substantially larger samples than other disciplines. As with number of studies, the disciplines with the smallest number of effects per study are health-related fields such as Dentistry, Diet & Clinical Nutrition, Medicine, Nursing, Pharmacy, Therapeutics & Pharma, and Public Health.

MEASURES OF EFFECT SIZE
Disciplines also differ in the effects they measure. We identified four main types of effects: (i) Mean Differences, including standardized mean differences, Cohen’s d, and Hedge’s g; (ii) Odds-Ratios; (iii) Risk Ratios, including Relative Risk, Response Ratios, and Hazard Ratios; (iiia) Correlations, including Fisher’s z; (iiib) Partial Correlations, and (iv) Estimated Effects.
We differentiate correlations from partial correlations because the latter primarily appear in Economics. Likewise, Economics is somewhat unique because the range of estimated effects vary widely across primary studies, with studies focusing on things like elasticities, various treatment effects, and other effects like fiscal multipliers or model parameters. The table below lists the most common and second most common effect sizes investigated by meta-analyses across the different disciplines.

We might ask why does it matter that meta-analyses differ in their sizes and estimated effects? In a recent study, Hong and Reed (2021) present evidence that the performance of various estimators depends on the size of the meta-analyst’s sample. They provide an interactive ShinyApp that allows one to filter performance measures by various study characteristics in order to identify the best estimator for the specific research situation. Performance may also depend on the type of effect being estimated (see here for some tentative experimental evidence on partial correlations).
ESTIMATION – Estimators
One way in which disciplines are very similar is on their reliance on the same estimators to estimate effect sizes. TABLE 4 reports the two most common estimators by discipline. Far and away the most common estimator is the Random Effects estimator that allows for heterogeneous effects across studies.
The second most common estimator is the Fixed Effects estimator, which is built on the assumption of a single population effect, whereby studies produce different estimated effects due only to sampling error. A close relative of the Fixed Effects estimator common in Economics is the Weighted Least Squares estimator of Stanley and Doucouliagos. This estimator produces coefficient estimates identical to the Fixed Effects estimator, but with different standard errors. Despite being the most common estimator, Hong and Reed (2021) show that Random Effects frequently underperforms relative to other meta-analytic estimators.

SOFTWARE PACKAGES
Another way in which disciplines differ is with respect to the software packages they use. These include a number of standalone packages such as MetaWin, RevMan (for Review Manager), and CMA (for Comprehensive Meta-Analysis); as well as packages designed to be used in conjunction with comprehensive software programs such as R and Stata.
A frequently used R package is metafor. Stata has a built-in meta-analysis suite called meta. In addition to these packages, many researchers have customized their own programs to work with R or Stata. As an example, in economics, Tomas Havránek has published a wide variety of meta-analyses using customized Stata programs. These can be viewed here.
TABLE 5 reports the most common software packages used by the studies in our sample. It is clear that R and Stata are the packages of choice for most researchers when estimating effect sizes.

ESTIMATION – Tests for Publication Bias
Another area where there is much commonality among disciplines is statistical testing for publication bias. While disciplines differ in how frequently they report such tests (see below), when they do, they usually rely on some measure of the relationship between the estimated effect size and its standard error or variance.
Egger’s test is the most common statistical test for publication bias. It consists of a regression of the effect size on the standard error of the effect size. Closely related is the FAT-PET (or its extension, FAT-PET-PEESE). FAT-PET stands for Funnel Asymmetry Test – Precision Effect Test. This is essentially the same as an Egger regression except that the regression is also used to obtain a publication-bias adjusted estimate of the effect size (“PET”, since this effect is commonly estimated in a specification where the mean effect size is measured by the coefficient on the effect size precision variable).
The rank correlation test, also known as Begg’s test or the Begg and Mazumdar rank correlation test, works very similarly except rather than a regression, it rank correlates the estimated effect size with its variance. Other tests, such as Trim and fill, Fail-safe N, and tests based on selection models, are less common.

OTHER META-ANALYSIS FEATURES
In addition to the characteristics identified above, disciplines also differ by how commonly they report information in addition to estimates of the effect size. Three common features are funnel plots, publication bias tests, and meta-regressions.
Funnel plots can be thought of as a qualitative Egger’s test. Rather than a regression relating the estimated effect size to its standard error, a funnel plot plots the relationship, providing a visual impression of potential publication bias. As is apparent from TABLE 6, not all meta-analyses report funnel plots. They appear to be particularly scarce in Agriculture, where only 15% of our sampled meta-analyses reported a funnel plot. For most disciplines, roughly half of the meta-analyses reported funnel plots. Funnel plots were most frequent in Medicine, with approximately 4 out of 5 meta-analyses showing a funnel plot.
TABLE 6 reports the most common statistical tests for publication bias conditional on such tests being carried out. While not all meta-analyses test for publication bias, most do. 15 of the 18 disciplines had a reporting rate of at least 50% when it comes to statistical tests of publication bias. Anatomy & Physiology and Diet & Clinical Nutrition had the highest rates, with 85% of meta-analyses reporting tests for publication bias. Agriculture had the lowest at 30%.
The last feature we focus on is meta-regression. A meta-regression is a regression where the dependent variable is the estimated effect size and the explanatory variables consist of various study, data, and estimation characteristics that the researcher believes may influence the estimated effect size. Technically speaking, an Egger regression is a meta-regression. However, here we restrict it to studies that attempt to explain differences in estimated effects across studies by relating them to characteristics of those studies beyond the standard error of the effect size.
Meta-regressions are very common in Economics, with almost 9 out of 10 meta-analyses including them. They are less common in other disciplines, with most disciplines having a reporting rate less than 50%. None of the 20 Agriculture meta-analyses in our sample reported a meta-regression.
Nevertheless, there are other ways that meta-analyses can explore systematic differences in effect sizes. Many studies perform subgroup analyses. For example, a study of the effect of a certain reading program may break out the full sample according to the predominant racial or ethnic characteristics of the school jurisdiction to determine whether there these characteristics are related to the effectiveness of the program.

CONCLUSION
While our results are based on a limited sampling of meta-analyses, the results indicate that there are important differences in meta-analytic research practices across disciplines. Researchers can benefit from this knowledge by appropriately accommodating their research if they are considering submitting their work to interdisciplinary journals. Likewise, being familiar with another discipline’s norms enables one to provide a fairer, more objective review when one is called to referee meta-analyses from journals outside one’s discipline.
As noted above, estimator performance may also be impacted by study and data characteristics. While some research has explored this topic, this is largely unexplored territory. Recognizing that meta-analyses from different disciplines have different characteristics should make one sensitive that estimators and practices that are optimal in one field may not be well suited in others. We hope this study encourages more research in this area.
Jianhua (Jane) Duan is a post-doctoral fellow in the Department of Economics at the University of Canterbury. She is being supported by a grant from the Center for Open Science. Bob Reed is Professor of Economics and the Director of UCMeta at the University of Canterbury. They can be contacted at jianhua.duan@pg.canterbury.ac.nz and bob.reed@canterbury.ac.nz, respectively.

You must be logged in to post a comment.