[From the article, “Rein in the four horsemen of irreproducibility”, by Dorothy Bishop, published in Nature]
“More than four decades into my scientific career, I find myself an outlier among academics of similar age and seniority: I strongly identify with the movement to make the practice of science more robust.”
“It’s not that my contemporaries are unconcerned about doing science well; it’s just that many of them don’t seem to recognize that there are serious problems with current practices.”
“By contrast, I think that, in two decades, we will look back on the past 60 years — particularly in biomedical science — and marvel at how much time and money has been wasted on flawed research.”
To read the article, click here.
[From the working paper, “How Cluster-Robust Inference Is Changing Applied Econometrics” by James MacKinnon, posted as a Queen’s University Working Paper]
“Whenever the observations can plausibly be grouped into a set of clusters, it has become customary, indeed often mandatory, in many areas of applied econometrics to use clustered standard errors….Nevertheless, whether and how to account for clustered disturbances is still somewhat controversial.”
“I am making the (arguably very strong) assumptions that each observation belongs to one and only one cluster, that the investigator knows which cluster it belongs to, and that any correlation across observations occurs only within clusters.”
“For simplicity and concreteness, consider the linear regression model where y and u are Nx1 vectors of observations and disturbances, X is an NxK matrix of exogenous covariates, and β is a Kx1 parameter vector. With one-way clustering, which is currently the most common case, there are G clusters, indexed by g, where the gth cluster has Ng observations.”
where y and u are Nx1 vectors of observations and disturbances, X is an NxK matrix of exogenous covariates, and β is a Kx1 parameter vector. With one-way clustering, which is currently the most common case, there are G clusters, indexed by g, where the gth cluster has Ng observations.”
“This yields a cluster-robust variance estimator, or CRVE, of which the most widely-used version is
“CV1 can have rank at most G-1. This makes it impossible to test hypotheses involving more than G-1 restrictions using Wald tests based on (4). Moreover, for hypotheses that involve numbers of restrictions not much smaller than G-1, the finite-sample properties of Wald tests based on (4) are likely to be very poor.”
“Allowing the disturbances to be correlated fundamentally changes the nature of statistical inference, especially for large samples. This is most easily seen in the context of estimating a population mean. Suppose we have a sample of N uncorrelated observations, yi, each with variance Var(yi) that is bounded from below and above. Then the usual formula for the variance of the sample mean [ybar] is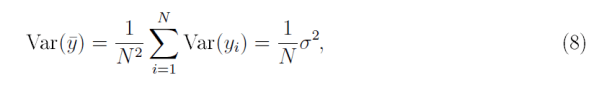
“From (8) it is easy to see that Var(ybar)→0 as N→∞. But this result depends crucially on the assumption that the yi are uncorrelated.”
“Without such an assumption, the variance of the sample mean would be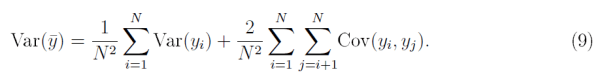
“…even if the Cov(yi;yj) are very small, the variance of ybar will never converge to zero as N→∞. Instead, it will ultimately converge to whatever the second term converges to.”
“…inference with clustered disturbances can be very different from inference with uncorrelated ones. When G is fixed, or increases less rapidly than N, the information contained in a sample grows more slowly than the sample size…. This implies that the amount of information about the parameters of interest contained in extremely large samples (such as the ones increasingly encountered in empirical microeconomics) may be very much less than intuition would suggest.”
“Much of the work on cluster-robust inference in recent years has focused on inference in finite samples. The meaning of finite is not the usual one, however. What matters for reliable inference is not the number of observations, N, but the number of clusters, G. In addition, both the way in which observations are distributed across clusters and the characteristics of the Xg matrices can greatly affect the reliability of finite-sample inference.”
“Suppose we are interested in one element of β, say βj . Then cluster-robust inference is typically based on the t statistic where βj0 is the value under the null hypothesis, and [Vhatjj] is the jth diagonal element of the CV1 matrix (4). The statistic tj is generally assumed to follow the Student’s t distribution with G-1 degrees of freedom.”
where βj0 is the value under the null hypothesis, and [Vhatjj] is the jth diagonal element of the CV1 matrix (4). The statistic tj is generally assumed to follow the Student’s t distribution with G-1 degrees of freedom.”
“Inference based on (11) and the t(G-1) distribution can sometimes work very well. It generally does so when there are at least 50 clusters and they are reasonably homogeneous, that is, similar in size and with reasonably similar Xg‘Xg and Xg‘ΩgXg matrices. However, there can be severe over-rejection when these conditions are not satisfied.”
“In most cases, the best way to perform tests of restrictions on the linear regression model (1) seems to be to use a particular version of the wild bootstrap. We first compute either a t statistic like tj or a Wald statistic … then compute a large number of bootstrap test statistics, and finally calculate a bootstrap P value that measures how extreme the actual test statistic is relative to the distribution of the bootstrap test statistics. For example, if 26 out of 999 bootstrap statistics were more extreme than the actual test statistic, the bootstrap P value would be 27/999 = 0.027.”
“The key issue for bootstrap testing is how to generate the bootstrap samples. In the case of (1), there are several plausible ways to do so. The best approach usually seems to be to use the restricted wild cluster bootstrap (WCR).”
“Provided the number of clusters is not too large, it is possible to generate a large number of wild cluster bootstrap test statistics very efficiently. This is what the Stata routine boottest does… Because using boottest is so inexpensive in most cases, it probably makes sense to employ the restricted wild cluster bootstrap by default whenever making cluster-robust inferences using Stata.”
“Reliable inference is particularly challenging when the parameter of interest is the coefficient on a treatment dummy variable, treatment is assigned at the cluster level, and there are very few treated clusters. This includes the case of difference-in-differences (DiD) regressions when all the treated observations belong to just a few clusters. It has been known for some time that using cluster-robust t statistics leads to serious over-rejection in such cases.”
[There is a] “…large and rapidly growing literature aimed at improving cluster robust inference in finite samples. A wide variety of methods is available, and it would often make sense to employ two or three of them. In many cases, but not all, the restricted wild cluster bootstrap works very well. Perhaps surprisingly, it can often be computed remarkably quickly using the Stata routine boottest.”
“As the empirical examples ,,, illustrate, inference can be very sensitive to how (and whether) the observations are clustered. In practice, investigators would therefore be wise to put a lot of thought into this. When there is more than one natural way to cluster, it generally makes sense to investigate all of them.”
[From the article, “The Meaningfulness of Effect Sizes in Psychological Research: Differences Between Sub-Disciplines and the Impact of Potential Biases” by Thomas Schäfer and Marcus Schwarz, published April 11, 2019 in Frontiers in Psychology]
“From past publications without preregistration, 900 effects were randomly drawn and compared with 93 effects from publications with pre-registration, revealing a large difference: Effects from the former (median r = 0.36) were much larger than effects from the latter (median r = 0.16). That is, certain biases, such as publication bias or questionable research practices, have caused a dramatic inflation in published effects…”
“As we have argued throughout this article, biases in analyzing, reporting, and publishing empirical data (i.e., questionable research practices and publication bias) are most likely responsible for the differences between the effect sizes from studies with and without pre-registration.”
To read the article, click here.
[From the article, “Publication bias examined in meta-analyses from psychology and medicine: A meta-meta-analysis” by Robbie van Aert, Jelte Wicherts, and Marcel van Assen, published April 12, 2019 in PlosONE]
“A large-scale data set was created with meta-analyses published between 2004 and 2014 in Psychological Bulletin and in the Cochrane Library to study the extent and prevalence of publication bias in psychology and medicine…”
“Results of p-uniform suggest that possible overestimation because of publication bias was at most minimal for subsets from Psychological Bulletin.”
“The results of our paper are not in line with previous research…Only weak evidence for the prevalence of publication bias was observed in our large-scale data set of homogeneous subsets of primary studies. No evidence of bias was obtained using the publication bias tests. Overestimation was minimal but statistically significant…”
“Based on these findings in combination with the small percentages of statistically significant effect sizes in psychology and medicine, we conclude that evidence for publication bias in the studied homogeneous subsets is weak, but suggestive of mild publication bias in both disciplines.”
To read the article, click here.
[From the preprint “Abandoning statistical significance is both sensible and practical” by Valentin Amrhein, Andrew Gelman, Sander Greenland, and Blakely McShane, available at PeerJ Preprints]
“Dr Ioannidis writes against our proposals to abandon statistical significance…”
“…we disagree that a statistical significance-based “filtering process is useful to avoid drowning in noise” in science and instead view such filtering as harmful.”
“First, the implicit rule to not publish nonsignificant results biases the literature with overestimated effect sizes and encourages “hacking” to get significance.”
“Second, nonsignificant results are often wrongly treated as zero.”
“Third, significant results are often wrongly treated as truth rather than as the noisy estimates they are, thereby creating unrealistic expectations of replicability.”
“Fourth, filtering on statistical significance provides no guarantee against noise. Instead, it amplifies noise because the quantity on which the filtering is based (the p-value) is itself extremely noisy and is made more so by dichotomizing it.”
“We also disagree that abandoning statistical significance will reduce science to “a state of statistical anarchy.” Indeed, the journal Epidemiology banned statistical significance in 1990 and is today recognized as a leader in the field.”
“The replication crisis in science is not the product of the publication of unreliable findings. … Rather, the replication crisis has arisen because unreliable findings are presented as reliable.”
[From the Center for Open Science]
The Center for Open Science is seeking graduate students, post docs, researchers and academic faculty to participate in a survey to investigate the factors that affect the perceived credibility and use of preprints.
Participation in this study involves:
– A time commitment of up to 20 minutes.
– Survey involving your qualitative, subjective evaluation of factors related to the credibility of preprints.
Currently using preprints (either uploading preprints or reading preprints) is not a prerequisite to participating in the study.
If you are interested in enrolling in this study, please click this link which will lead you directly to the survey. You must be 18 or older to participate.
If you would like more information, please contact this project’s research lead, Courtney Soderberg, by email (courtney@cos.io).
Thank you!
[From the paper “Consistency without Inference: Instrumental Variables in Practical Application” by Alwyn Young, posted on his university webpage at London School of Economics]
“I use Monte Carlo simulations, the jackknife and multiple forms of the bootstrap to study a comprehensive sample of 1359 instrumental variables regressions in 31 papers published in the journals of the American Economic Association.”
“I maintain, throughout, the exact specification used by authors and their identifying assumption that the excluded instruments are orthogonal to the second stage residuals. When bootstrapping, jackknifing or generating artificial residuals for Monte Carlos, I draw samples in a fashion consistent with the error dependence within groups of observations and independence across observations implied by authors’ standard error calculations.”
“Non-iid errors weaken 1st stage relations, raising the relative bias of 2SLS and generating mean squared error that is larger than biased OLS in almost all published papers.”
“Monte Carlo simulations based upon published regressions show that non-iid error processes adversely affect the size and power of IV estimates, while increasing the bias of IV relative to OLS, producing a very low ratio of power to size and mean squared error that is almost always larger than biased OLS.”
“In the top third most highly leveraged papers in my sample, the ratio of power to size approaches one, i.e. 2SLS is scarcely able to distinguish between a null of zero and the alternative of the mean effects found in published tables.”
“Monte Carlos show, however, that the jackknife and (particularly) the bootstrap allow for 2SLS and OLS inference with accurate size and a much higher ratio of power to size than achieved using clustered/robust covariance estimates. Thus, while the bootstrap does not undo the increased bias of 2SLS brought on by non-iid errors, it nevertheless allows for improved inference under these circumstances.”
“I find that avoiding the finite sample 2SLS standard estimate altogether and focusing on the bootstrap resampling of the coefficient distribution alone provides the best performance, with tail rejection probabilities on IV coefficients that are very close to nominal size in iid, non-iid, low and high leverage settings.”
“In sum, whatever the biases of OLS may be, in practical application with non-iid error processes and highly leveraged regression design, the performance of 2SLS methods deteriorates so much that it is rarely able to identify parameters of interest more accurately or substantively differently than is achieved by OLS.”
[From the paper “The practical alternative to the p-value is the correctly used p-value” by Daniël Lakens, posted at PsyArXiv Preprints]
“I do not think it is useful to tell researchers what they want to know. Instead, we should teach them the possible questions they can ask (Hand, 1994). One of these questions is how surprising observed data is under the assumption of some model, to which a p-value provides an answer.”
“The accusation that p-values are a cause of the problems with replicability across scientific disciplines lacks empirical support. Hanson (1958) examined the replicability of research findings published in anthropology, psychology, and sociology. One of the hypotheses examined was whether propositions advanced with explicit confirmation criteria, such as the rejection of a hypothesis at a 5% significance level, were more replicable than propositions made without such an explicit confirmation criterium. He found that ‘over 70 per cent of the original propositions advanced with explicit confirmation criteria were later confirmed in independent tests, while less than 46 per cent of the propositions advanced without explicit confirmation criteria were later confirmed.”
“There is also no empirical evidence to support the idea that replacing hypothesis testing with estimation, or p-values with for example Bayes factors, will matter in practice. …If alternative approaches largely lead to the same decisions as a p-value when used with care, why exactly is the p-value the problem?”
“Most problems attributed to p-values are problems with the practice of null-hypothesis significance testing. Many misinterpretations of single p-values have to do with either concluding a meaningful effect is absent after a non-significant result, or misinterpreting a significant result as an important effect.”
“I personally believe substantial improvements can be made by teaching researchers how to calculate p-values for minimal-effects tests and equivalence tests. Minimal-effects tests and equivalence tests require the same understanding of statistics as null-hypothesis tests, but provide an easy way to ask different questions from your data, such as how to provide support for the absence of a meaningful effect.”
“Teaching students that testing a range prediction is just as easy as testing against an effect size of 0 has almost no cost but might solve some of the most common misunderstandings of p-values.”
[From the blog “The replication crisis is good for science” by Eric Loken, published at The Conversation]
“Science is in the midst of a crisis: A surprising fraction of published studies fail to replicate when the procedures are repeated.”
“Is this bad for science? It’s certainly uncomfortable for many scientists whose work gets undercut, and the rate of failures may currently be unacceptably high. But, as a psychologist and a statistician, I believe confronting the replication crisis is good for science as a whole.”
“Awareness about the replication crisis appears to be promoting better behavior among scientists. Today, the stakes have been raised for researchers. They know that there’s the possibility that their study might be reviewed by thousands of opinionated commenters on the internet or by a high-profile group like the Reproducibility Project.”
“Finally, the replication crisis is helping improve scientists’ intuitions about statistical inference.”
“Researchers now better understand how weak designs with high uncertainty – in combination with choosing to publish only when results are statistically significant – produce exaggerated results.”
“The breathtaking possibility that a large fraction of published research findings might just be serendipitous is exactly why people speak of the replication crisis. But it’s not really a scientific crisis, because the awareness is bringing improvements in research practice, new understandings about statistical inference and an appreciation that isolated findings must be interpreted as part of a larger pattern.”
From the blog “Reflections of an open science convert. 1: Why I changed my research practices” (Part 1 of a 3-part series) by Ineke Wessel, posted at Mindwise]
“Five years after Stapel’s fraud first became known, I came across Brian Wansink’s blog posts about how exploring data in every possible way can get you publications. The scientific community responded with outrage. On the one hand, Wansink’s data-dredging seemed far more extreme than the post-hoc analyses I used to do. On the other hand, I wondered what exactly, apart from the scale (huge) and intent (find a positive result no matter what), the differences were between me and him.”
“As I browsed the internet, an online lecture by Zoltan Dienes caught my attention. Dienes described the problem that Gelman & Loken (2014) refer to as the garden of forking paths: the idea that every potential, often seemingly arbitrary decision in data analysis (e.g., how to construct a score; what to do with outliers) contributes to a different end-result. Indeed, it is like hiking: choosing either left or right at the first fork in the path (and the fork after that, and the one after that, etc.) will determine where you will have lunch ultimately.”
“Dienes used the example of one particular published study that implicitly harboured 120 plausible combinations of decisions … A plot of the 120 possible difference scores for one particular variable (i.e., a multiverse) showed that their confidence intervals could contain exclusively positive as well as exclusively negative values, and mostly hovered around zero (i.e., no difference). Thus, despite what seemed a convincing effect in the paper, considering the full array of outcomes for that one variable should lead to the conclusion that really nothing can be said about it.”
“I was stunned. So many possibilities, and precisely one of those rare statistically significant occurrences had made it into the literature! Perhaps by coincidence, perhaps because certain routes fit better with the authors’ hypothesis than other routes? But regardless of why this particular result ended up in the paper, how can readers even know about those other 119?”
“So, now I am working on changing my research practices.”
[From the article “Assessing citizen adoption of e-government initiatives in Gambia: A validation of the technology acceptance model in information systems success. A critical article review, with questions to its publishers” by Daniel Jung, published in Government Information Quarterly]
“The article is on Elsevier’s list of most cited articles from the Government Information Quarterly journal, and has become a key reference in the field of study, with nearly 250 citations (in Google scholar). However, it completely fails when it comes to overall linguistic expression, literature review, grounding in the field, citation practice, questionnaire design, data collection, rendering and interpreting others’ and own data, calculation, claims of user-centeredness and accounting for cultural differences, and the final assertion that all this leads to Gambia benefiting from TAM.”
“Its premise and findings are blatantly wrong: they are not valid, reliable, verifiable or reproducible in any way. No single part could be changed to achieve integrity, and for proper results, everything would have to be redone, starting with the questionnaire design, and ending with the conclusion.”
“This article is as close to a scientific hoax as one can possibly come, but I believe that it is just an unfortunate case of poor science, not a deliberate fraud as such, even if the Zambia/Gambia quote is hard to excuse as unintentional. In any case, this is an article that should obviously never have been published, and raises serious questions about the editorial rigor, the quality of the peer reviewing, and the revision process in the journal.”
To read the article, click here.

You must be logged in to post a comment.