[From the article “’I Want to Burn Things to the Ground’: Are the foot soldiers behind psychology’s replication crisis saving science — or destroying it?” by Tom Bartlett]
“As you’ve no doubt heard by now, social psychology has had a rough few years. The trouble concerns the replicability crisis, a somewhat antiseptic phrase that refers to the growing realization that often the papers published in peer-reviewed journals — papers with authoritative abstracts and nifty-looking charts — can’t be reproduced. In other words, they don’t work when scientists try them again. If you wanted to pin down the moment when the replication crisis really began, you might decide it was in 2010, when Daryl Bem, a Cornell psychologist, published a paper in The Journal of Personality and Social Psychology that purported to prove that subjects could predict the future. Or maybe it was in 2012, when researchers failed to replicate a much-heralded 1996 study by John Bargh, a Yale psychologist, that claimed to show that reading about old people made subjects walk more slowly.”
“And it’s only gotten worse. Some of the field’s most exciting and seemingly rock-solid findings now appear sketchy at best. Entire subfields are viewed with suspicion. It’s likely that many, perhaps most, of the studies published in the past couple of decades are flawed. Just last month the Center for Open Science reported that, of 21 social-behavioral-science studies published in Science and Nature between 2010 and 2015, researchers could successfully replicate only 13 of them. Again, that’s Science and Nature, two of the most prestigious scientific journals around.”
“If you’re a human interested in reliable information about human behavior, that news is probably distressing. If you’re a psychologist who has built a career on what may turn out to be a mirage, it’s genuinely terrifying. The replication crisis often gets discussed in technical terms: p-values, sample sizes, and so on. But for those who have devoted their lives to psychology, the consequences are not theoretical, and the feelings run deep. In 2016, Susan Fiske, a Princeton psychologist, used the phrase “methodological terrorism” to describe those who dissect questionable research online, bypassing the traditional channels of academic discourse … Fiske wrote that “unmoderated attacks” were leading psychologists to abandon the field and discouraging students from pursuing it in the first place.”
[From the abstract to the article, “Quantifying Support for the Null Hypothesis in Psychology: An Empirical Investigation” by Aczel et al., recently published in Advances in Methods and Practices in Psychological Science]
“In the traditional statistical framework, nonsignificant results leave researchers in a state of suspended disbelief. In this study, we examined, empirically, the treatment and evidential impact of nonsignificant results. Our specific goals were twofold: to explore how psychologists interpret and communicate nonsignificant results and to assess how much these results constitute evidence in favor of the null hypothesis. First, we examined all nonsignificant findings mentioned in the abstracts of the 2015 volumes of Psychonomic Bulletin & Review, Journal of Experimental Psychology: General, and Psychological Science (N = 137). In 72% of these cases, nonsignificant results were misinterpreted, in that the authors inferred that the effect was absent. Second, a Bayes factor reanalysis revealed that fewer than 5% of the nonsignificant findings provided strong evidence (i.e., BF01 > 10) in favor of the null hypothesis over the alternative hypothesis. We recommend that researchers expand their statistical tool kit in order to correctly interpret nonsignificant results and to be able to evaluate the evidence for and against the null hypothesis.”
To read the article, click here.
[From the working paper “Why Too Many Political Science Findings Cannot be Trusted and What We Can Do About It” by Alexander Wuttke, posted at SocArXiv Papers]
“…this article reviewed the meta-scientific evidence with a focus on the quantitative political science literature. The main result of these meta-scientific inquiries is that a significant portion of examined studies do not meet one or several credibility criteria. Specifically, by not providing data and method transparency, many or most political science studies make themselves inaccessible to inter-subjective validity assessments and when put to a test, the empirical findings of many studies cannot be verified. Moreover, findings in published and unpublished research diverge strongly and systematically and the published studies show evidence of substantial underreporting. Altogether, meta-scientific evidence indicates deficiencies in the credibility of political science studies and suggests that the body of published political science findings is not an unbiased representation of the entire evidence base…”
[From the Research page of Gilad Feldman’s website.]
“In 2016, following recent developments in psychological science (the so called “replication crisis”) and gaining my academic independence, I decided to make serious changes to my research agenda to prioritize pre-registered replications and focus on the realm of judgment and decision making. I felt like I needed to revisit the research findings I once took for granted and re-establish the foundations on which I hope to build my research. I therefore decided that all my mentoring work with students will involve pre-registered replications, to examine the classics in the field. I chose to focus my efforts on judgment and decision making, because I felt that this literature has some of the strongest most established effects in the realm of psychology, with fairly simple and transparent research designs.”
“… This page aims to summarize the findings from my replication attempts so far.”
[This blog draws on the article “The statistical significance filter leads to overoptimistic expectations of replicability”, authored by Shravan Vasishth, Daniela Mertzen, Lena A. Jäger, and Andrew Gelman, published in the Journal of Memory and Language, 103, 151-175, 2018. An open access version of the article is available here.]
The Problem
Statistics textbooks tell us that the sample mean is an unbiased estimate of the true mean. This is technically true. But the textbooks leave out a very important detail.
When statistical power is low, any statistically significant effect that the researcher finds is guaranteed to be a mis-estimate: compared to the true value, the estimate will have a larger magnitude (so-called Type M error), and it could even have the wrong sign (so-called Type S error). This point can be illustrated through a quick simulation:
Imagine that the true effect has value 15, and the standard deviation is 100. Assuming that the data are generated from a normal distribution, an independent and identically distributed sample of size 20 will have power 10%. In this scenario, if you repeatedly sample from this distribution, in a few cases you will get a statistically significant effect. Each of those cases will have a sample mean that is very far away from the true value, and might even have the wrong sign. The figure below reports results from 50 simulations, ordered from smallest to largest estimated mean. Now, in the same scenario, if you increase sample size to 350, you will have power at 80%. In this case, whenever you get a statistically significant effect, it will be close to the true value; you no longer have a Type M error problem. This is also shown in the figure below.
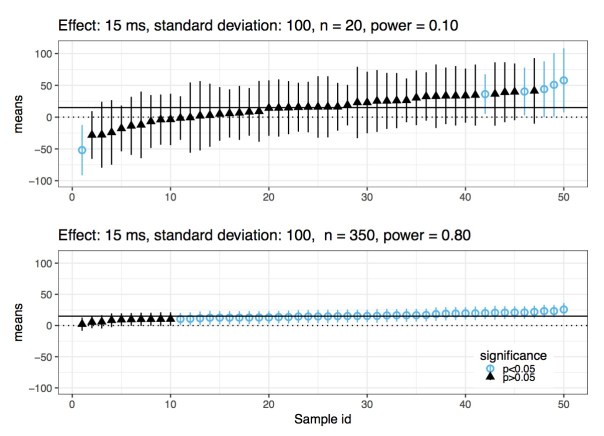
As the statistician Andrew Gelman put it, the maximum likelihood estimate can be “super-duper biased”(StanCon 2017, New York).
Given that we publish papers based on whether an effect is statistically significant or not, in situations where power is low, every one of those estimates that we see in papers will be severely biased. Surprisingly, I have never seen this point discussed in a mathematical statistics textbook. When I did my MSc in Statistics at the University of Sheffield (2011 to 2015), this important detail was never mentioned at any point. It should be the first thing one learns when studying null hypothesis significance testing.
Because this point is not widely appreciated yet, I decided to spend two years attempting to replicate a well-known result from the top ranking journal in my field. The scientific details are irrelevant here; the important point is that there are several significant effects in the paper, and we attempt to obtain similar estimates by rerunning the study seven times. The effects reported in the paper that we try to replicate are quite plausible given theory, so there is no a priori reason to believe that these results might be false positives.
You see the results of our replication attempts in the three figures below. The three blue bars show the results from the original data; the bars shown here represent 95% Bayesian credible intervals, and the midpoint is the mean of the posterior distribution. The original analyses were done using null hypothesis significance testing, which means that all the three published results were either significant or marginally significant. Now compare the blue bars with the black ones; the black bars represent our replication attempts. What is striking here is that all our estimates from the replication attempts are shrunk towards zero. This strongly implies that the original claims were driven by a classic type M error. The published results are “super-duper biased”, as Gelman would say.
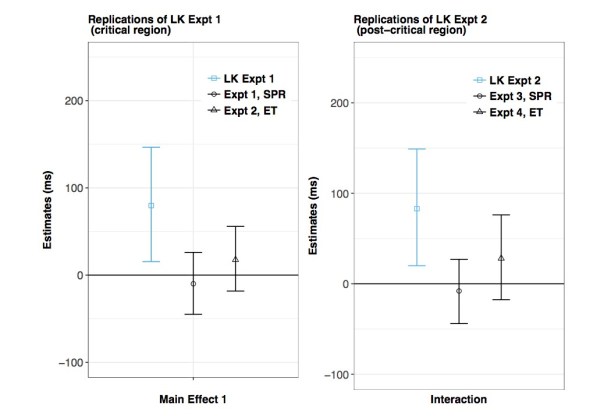
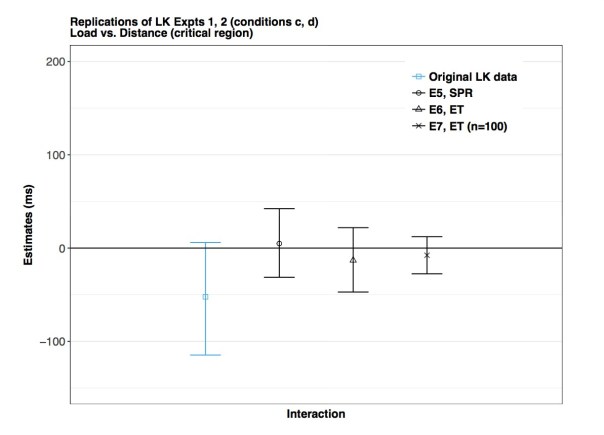
An important take-home point here is that the original data had significant or nearly significant effects, but the estimates also had extremely high uncertainty. We see that from the wide 95% credible intervals in the blue bars. We should pay attention to the uncertainty of our estimates, and not just whether the effect is significant or not. If the uncertainty is high, the significant effect probably represents a biased estimate, as explained above.
A Solution
What is a better way to proceed when analysing data? The null hypothesis significance testing framework is dead on arrival if you have insufficient power: you’re doomed to publish overestimates of the effects you are interested in.
A much more sensible way is to focus on quantifying uncertainty about your estimate. The Bayesian framework provides a straightforward methodology for achieving this goal.
1) Run your experiment until you achieve a satisfactorily low uncertainty of your estimate; in each particular domain, what counts as satisfactorily low can be established by specifying the range of quantitative predictions made by theory. In our paper, we discuss the details of how we do this in our particular domain of interest. We also explain how we can interpret these results in the context of theoretical predictions; we use a method that is sometimes called the region of practical equivalence approach.
2) Conduct direct replications to establish the robustness of your estimates. Andrew Gelman has called this the “secret weapon”. There is only one way to determine whether one has found a replicable effect: actual replications.
3) Preregistration, open access to the published data and code are critical to the process of doing good science. Surprisingly, these important ideas have not yet been widely adopted. People continue to hoard their data and code, often refusing to release it even on request. This is true at least for psychology, linguistics, some areas of medicine, and surprisingly, even statistics.
When I say all this to my colleagues in my field, a common reaction from them is that they can’t afford to run high-power studies. I have two responses to that. First, you need to use the right tool for the job. When power is low, prior knowledge needs to be brought into the analysis; in other words, you need Bayes. Second, for the researcher to say that they want to study subtle questions but they can’t be bothered to collect enough data to get an accurate answer is analogous to a medical researcher saying that he wants to cure cancer but all he has is duct tape, so let’s just go with that.
Is There Any Point In Discussing These Issues?
None of the points discussed here are new. Statisticians and psychologists have been pointing out these problems since at least the 1970s. Psychologists like Meehl and Cohen energetically tried to educate the world about the problems associated with low statistical power. Despite their efforts, not much has changed. Many scientists react extremely negatively to criticisms about the status quo. In fact, just three days ago, at an international conference I was delivered a message from a prominent US lab that I am seen as a “stats fetishist”. Instead of stopping to consider what they might be doing wrong, they dismiss any criticism as fetishism.
One fundamental problem for science seems to be the problem of statistical ignorance. I don’t know anybody in my field who would knowingly make such mistakes. Most people who use statistics to carry out their scientific goals treat it as something of secondary importance. What is needed is an attitude shift: every scientist using statistical methods needs to spend a serious amount of effort into acquiring sufficient knowledge to use statistics as intended. Curricula in graduate programs need to be expanded to include courses taught by professional statisticians who know what they’re doing.
Another fundamental problem here is that scientists are usually unwilling to accept that they ever get anything wrong. It is completely normal to find people who publish paper after paper over a 30 or 40-year career that seemingly validates every claim that they ever made in the past. When one believes that one is always right, how can one ever question the methods and the reasoning that one uses on a day-to-day basis?
A good example is the recently reported behavior of the Max Planck director Tania Singer. Science reports: “Scientific discussions could also get overheated, lab members say. “It was very difficult to tell her if the data did not support her hypothesis,” says one researcher who worked with Singer.”
Until senior scientists such as Singer start modelling good behaviour by openly accepting that they can be wrong, and until the time comes that people start taking statistical education seriously, my expectation is that nothing will change, and business will go on as usual:
1) Run a low-powered study
2) P-hack the data until statistical significance is reached and the desired outcome found
3) Publish result
4) Repeat
It has been a successful formula. It has given many people tenure and prestigious awards, so there is very little motivation for changing anything.
Shravan Vasishth is Professor of Linguistics, University of Potsdam, Germany. His biographical and contact information can be found here.
[From the Cambridge University Press website promoting Deborah Mayo’s new book, Statistical Inference as Severe Testing: How to Get Beyond the Statistics Wars]
“Mounting failures of replication in social and biological sciences give a new urgency to critically appraising proposed reforms. This book pulls back the cover on disagreements between experts charged with restoring integrity to science. It denies two pervasive views of the role of probability in inference: to assign degrees of belief, and to control error rates in a long run. If statistical consumers are unaware of assumptions behind rival evidence reforms, they can’t scrutinize the consequences that affect them (in personalized medicine, psychology, etc.). The book sets sail with a simple tool: if little has been done to rule out flaws in inferring a claim, then it has not passed a severe test. Many methods advocated by data experts do not stand up to severe scrutiny and are in tension with successful strategies for blocking or accounting for cherry picking and selective reporting. Through a series of excursions and exhibits, the philosophy and history of inductive inference come alive. Philosophical tools are put to work to solve problems about science and pseudoscience, induction and falsification.”
[From the article, “The statistical significance filter leads to overoptimistic expectations of replicability” by Shravan Vasishth, Daniela Mertzen, Lena Jäger, and Andrew Gelman, published in the Journal of Memory and Language]
Highlights:
“When low-powered studies show significant effects, these will be overestimates.”
“Significant effects from low-powered studies will not be replicable.”
“Seven experiments show that effects reported in Levy and Keller (2013) are not replicable.”
“Relying only on statistical significance leads to overconfident expectations of replicability.”
“We make several suggestions for improving current practices.”
To read the JML article, click here. (NOTE: Preprint can be found here.]
[From the article “Pre-results review at the Journal of Development Economics: Taking transparency in the discipline to the next level” by Aleksandar Bogdanoski and Keesler Welch, published at the blogsite of the Abdul Latif Jameel Poverty Action Lab (J-PAL)]
“J-PAL interviewed JDE Editor in Chief Andrew Foster, Co-editor Dean Karlan, and BITSS Faculty Director Edward Miguel, to get some early insights from the pilot thus far.”
[From the article, “The Landscape of Open Data Policies” by David Mellor, published at the Center for Open Science blogsite]
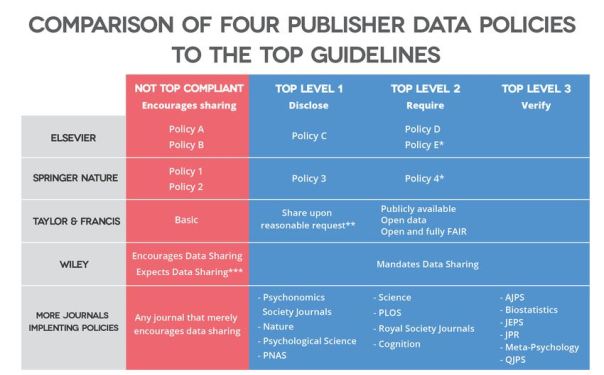
“TOP [Transparency and Openness Promotion] includes eight policies for publishers or funders to use to increase transparency. They include data transparency, materials and code transparency, design and citation standards, preregistration, and replication policies. For simplicity, this post will focus just on the Data Transparency policy. TOP can be implemented in one of three levels of increasing rigor:”
– “Level 1, Disclosure. Articles must state whether or not data underlying reported results are available and, if so, how to access them.”
– “Level 2, Mandate. Article must share data underlying reported results in a trusted repository. If data cannot be shared for ethical or legal constraints, authors must state this and provide as much data as can be reasonably shared.”
– “Level 3, Verify that shared data are reproducible. Shared data must be made available to a third party to verify that they can be used to replicate findings reported in the article.”
“Elsevier, Springer Nature, Taylor & Francis, and Wiley have all recently adopted tiered data sharing policies that make improvements in supporting transparency easier for the journals that they publish. Each shares some characteristics and rely on similar tiers: from encouragement to share data to increasingly strong mandates to do so.”

[From the blog “A manifesto for reproducible science” by Marcus Munafò, published at wonke.com]
“…several initiatives exist that can support universities keen to improve their research quality and culture. The Forum for Responsible Research Metrics promotes the better use of metrics, for example in recruitment and promotion procedures, and in 2018 hosted “The turning tide: a new culture of research metrics”. This highlighted that more effort is needed to embed relevant principles in institutions and foster more sensitive management frameworks. And in mid-September the University of Bristol will host a workshop for key stakeholders (funders, publishers, journals) to discuss the formation of a network of universities that will coordinate and share training and best practice.”
“This network will be an academic-led initiative, ensuring not only that efforts to improve research quality are coordinated, but also that they are evaluated (given that well-intentioned efforts may lead to unintended consequences), and designed with the needs of the academic research community in mind. It will allow the myriad of new initiatives across the UK to be brought together, and new initiatives to be developed. The current focus on the quality of scientific research is best understood not as a crisis but as an exciting opportunity to innovate and modernise. UK science has a well-deserved reputation for being world-leading, but to remain world leading we will need to embrace this opportunity.”

You must be logged in to post a comment.