[From the blog “Registered Reports: Piloting a Pre-Results Review Process at the Journal of Development Economics” by Andy Foster, Dean Karlan, and Ted Miguel posted at Development Impact]
“…the Journal of Development Economics (JDE) now offers authors the opportunity to have their prospective empirical projects reviewed and approved for publication before the results are known. This track for article submissions will be available as part of a pilot project, which will allow us to better understand the extent to which pre-results review can be applied at the JDE, and possibly in economics as a whole. …To our knowledge, this appears to be among the first attempts to introduce pre-results peer review in an economics journal. However, more than 90 academic journals in biology, medicine, political science, psychology, and other disciplines are already implementing pre-results review, with the subsequent published articles usually called ‘Registered Reports’ (RRs). We have tried to learn from their efforts in preparation for this pilot, and are coordinating our activities with the Berkeley Initiative for Transparency in the Social Sciences (BITSS) to help support authors and referees during this pilot phase.”
[From the article, “Sliced and Diced: The Inside Story of How an Ivy League Food Scientist Turned Shoddy Data into Viral Studies” by Stephanie M. Lee in Buzzfeed]
“Brian Wansink won fame, funding, and influence for his science-backed advice on healthy eating. Now, emails show how the Cornell professor and his colleagues have hacked and massaged low-quality data into headline-friendly studies to ‘go virally big time.’”
[From the article, “How to make replication the norm” published by Paul Gertler, Sebastian Galiani and Mauricio Romero in Nature]
“To see how often the posted data and code could readily replicate original results, we attempted to recreate the tables and figures of a number of papers using the code and data provided by authors. Of 415 articles published in 9 leading economics journals in May 2016, 203 were empirical papers that did not contain proprietary or otherwise restricted data. We checked these to see which sorts of files were downloadable and spent up to four hours per paper trying to execute the code to replicate the results (not including code runtime).”
“We were able to replicate only a small minority of these papers. Overall, of the 203 studies, 76% published at least one of the 4 files required for replication: the raw data used in the study (32%); the final estimation data set produced after data cleaning and variable manipulation (60%); the data-manipulation code used to convert the raw data to the estimation data (42%, but only 16% had both raw data and usable code that ran); and the estimation code used to produce the final tables and figures (72%).”
“The estimation code was the file most frequently provided. But it ran in only 40% of these cases. We were able to produce final tables and figures from estimation data in only 37% of the studies analysed. And in only 14% of 203 studies could we do the same starting from the raw data (see ‘Replication rarely possible’).”
[From the working paper, “Replication in experimental economics: A historical and quantitative approach focused on public good game experiments” by Nicolas Vallois and Dorian Jullien]
The current “replication crisis” concerns the inability of scientists to “replicate”, i.e. to reproduce a great number of their empirical findings. Many disciplines are concerned. Yet things appear to be better in experimental economics (EE). 61,1% of experimental results were successfully replicated in a large, collaborative project recently published by eminent experimental economists in Science (Camerer et al., 2016). The authors suggest that EE’s results are relatively more reproducible and robust than in psychology, where a similar study found a replication rate of 38% (Collaboration et al., 2015).
In our article, “Replication in experimental economics: A historical and quantitative approach focused on public good game experiments”, we provide a different perspective on the place of EE within the replication crisis. Our methodological innovation consists of looking at what we call “baseline replication”. The idea is straightforward. Experimental results are usually reported as a significant difference between a so-called “baseline condition” (or “control group”) and a treatment condition (usually similar to the baseline expect for one detail). For a given type of experiments in economics, most studies will have a baseline condition that is similar or very close to another baseline condition, so that, overall, it make sense to check whether the observation in a given baseline condition is close to the average observation across all baseline conditions. “Baseline replication” refers to the fact that results in baseline conditions of similar experiments are converging toward the same level. In other words, while most studies investigate replications of “effects” between baseline and treatment conditions, we abstract from treatment conditions to look only at baseline replication.
Our observations are restricted to a specific type of economic experiments: public goods (PG) game experiments. We chose the PG game because the field is relatively homogeneous and representative of the whole discipline of EE. A typical PG game consists of a group of subjects, each of which has money (experimental tokens) that can be used either to contribute to a PG (yielding returns to all the subjects in the group) or to invest in a private good (yielding returns only to the investor).
Our data set consists of 66 published papers on PG game experiments. Sampling methods are described in the paper. We collected the baseline result of each study, i.e. mean contribution rate in the baseline condition. Figure 1 (below) provides a graphical display of our data.
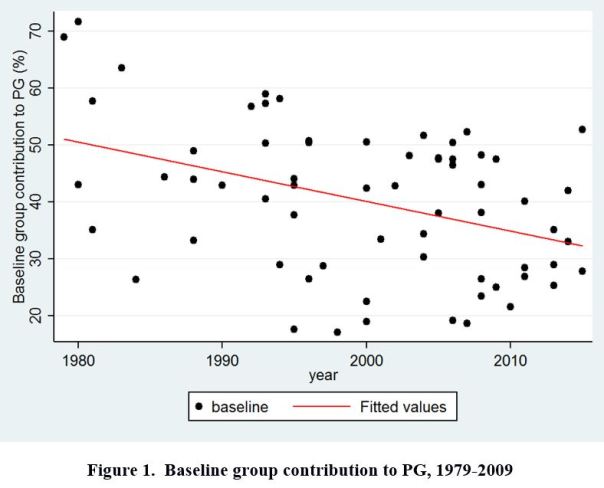 Our results are twofold:
Our results are twofold:
– First, there is a slight yet significant tendency for baseline results to converge over time. But the effect is very noisy and still allows for a substantial amount of between-studies variation in the more recent time period.
– Second, there is also a strongly significant decline of baseline results over time. The size effect is large: results in control conditions have decreased on average by 20% from 1979 to 2015.
The first result (slight convergence) suggests that baseline replication over time plays the role of a “weak constraint” on experimental results. Very high contribution rates (superior to 60%) are less likely to be found in the 2000’s-2010’s. But the fluctuation range remains important and a 50% baseline contribution rate might still seem acceptable in the 2010’s (where average baseline is 32,9%).
The second result (decrease of baseline results over time) was unexpected and seemingly unrelated to our initial question, since we were investigating convergence between experimental results, and not their decrease or increase over time. The 20% decrease in baseline contribution from 1979 to 2015 might suggest that early results were overestimated. A classical explanation for overestimation of size effect in empirical sciences is publication bias. Impressive results are easier to get published at first; once the research domain gets legitimized, publication practices favor more “normal” size effects
Hence, a first optimistic interpretation of both results is that lab experiments are “self-correcting” over time. Less and less exceptionally high control results are found in later time periods, meaning that initial overestimation of size effects is then corrected.
A second, less optimistic (though not pessimistic per se) interpretation, is that both convergence and decrease in baseline results are the effect of a tendency toward standardization in experimental designs. Experimental protocols in the 2000’s-2010’s for baseline conditions indeed seem to be more and more similar. Similar experiments can be expected to yield similar results. But it does not necessarily constitute a scientific improvement. More homogeneous experimental methods might be the result of mimetic dynamics in research and might not measure the “real” contribution to PG in the “real world”. If we suppose that the real rate is somewhere around 70%, initial high results in the 1980’s would be actually closer to the real size effect than the 32,91% average contribution rate found in the 2010’s
To test this hypothesis about “standardization”, we collected data about two important experimental parameters: the marginal per capita return (i.e., by how much each dollar contributed to the PG is multiplied before redistribution of the whole PG) and group size. We observe a clear tendency toward standardization from 1979 to 2015. After 2000, about two-third of PG games use the same basic experimental protocol with 4 or 5 persons-groups and a linear PG payoff yielding an exact and fixed return of 0,3 or 0,4 or 0,5; whereas those values were found only in approximately one experiment out of four in the 1980’s.
To conclude on our initial question, EE is not immune to the replication crisis. We found that baseline replication provides a “weak constraint” on experimental results. This might explain why EE performed relatively better than experimental psychology in the recent replication survey mentioned above (Camerer et al., 2016). We therefore agree with Camerer et al. on the “relatively good replication success” of EE (compared to psychology). Yet we disagree on the interpretation of this result. According to many experimental economists, EE’s results are more robust because they are based on more reliable methods: paying subjects and transparency in editorial practices. We provided evidence suggesting that better reproducibility in EE is not the effect of better methods but rather reflects a tendency to standardize experimental protocols. Such standardization does not necessarily imply that EE is relatively more scientifically advanced than experimental psychology. In this regard, it might be interesting for further research to compare the state of standardization in EE and experimental psychology.
To read the working paper, click here.
Nicolas Vallois is an economist at the CRIISEA – Centre de recherche sur les institutions, l’industrie et les systèmes économiques d’Amiens, Université de Picardie Jules Verne. He can be contacted at nicolas.vallois@u-picardie.fr. Dorian Jullien is a postdoctoral fellow at CHOPE (Center for the History of Political Economy), Duke University and a research associate at the GREDEG (Groupe de Recherche en Droit, Economie et Gestion), Université Côte d’Azur. His email is dorian.jullien@gredeg.cnrs.fr.
As of the start of 2018, the journal Cogent Economics and Finance is introducing a replication section. Cogent Economics and Finance is an open access journal publishing high-quality, peer-reviewed research. It is indexed in Scopus, Web of Science’s Emerging Sources Citation Index (ESCI), and has a B rating in the Australian Business Deans Council (ABDC) ranking. You can read more about the journal here.
As an online journal, it has the advantage of no page restrictions. This makes it advantageous for publishing replication studies, as many traditional journals are reluctant to publish these given scarce hard print, journal space.
But why introduce a replication section? Traditional journals in economics and finance are quick to dismiss replication studies. The question that every paper faces as it enters to review process is the ‘So what…?’ question – what is the contribution of this particular paper and is that contribution sufficient to merit publication – papers are rejected because the contribution is not sufficiently big, the paper is not novel, the results are similar to those reported elsewhere. Replication papers, therefore, do not stand a chance in this environment. Many papers will be consigned to lie in a bottom drawer, perhaps only given air in a classroom to compare results from published work to that with updated data
Why are replication studies important? Of course, papers that introduce new ideas, new econometric methodologies and new data sets are important. But so too are replication papers! Replication studies refer to those that replicate a previous piece of research but generally under a different situation e.g., with different data or over a different time period. These studies help determine if the key findings from the original study can indeed be applied to other situations.
Replication studies are important as they essentially perform a check on work in order to verify the previous findings and to make sure, for example, they are not specific to one set of data or circumstance. Hence, replication ensures that reported results are valid and reliable, are generalisable and can provide a sound base for future research. Replication studies thus provide robustness to the findings of research work and the interactions that they report. This matters as research can form the foundation of public policy, of regulatory acts and of corporate behaviour. New ideas formed in research today, end up in the textbooks of tomorrow and are taught to future generations. It is therefore important that such research and ideas are fully validated.
Why aren’t traditional journals more open to publishing replications? Even a brief look at the aims and scope of a range of journals in economics and finance (and no doubt beyond), reveal the words ‘original’, ‘new’, ‘meaningful insights’, ‘impact’, innovative’. All of these are, of course, laudable and desired but equally set a very high bar for replication studies, which may then encounter difficulty in finding an appropriate outlet.
Journals in economic and finance are also set in a journal ranking race – lists compiled by the Australian Business Deans Council, the Chartered Associated of Business Schools, the FT – determine the quality of journals, which affect the submission choices of authors as well as their promotion and job prospects. A journal that seeks to promote replication studies may find that such an approach does not help in these journal rankings, which are often determined by perception of quality and whether that journal publishes ground breaking work
The view taken by Cogent Economics and Finance is that it recognises the importance of replication studies and now seeks research papers that focus on replication and whose ultimate acceptance depends on the accuracy and thoroughness of the work rather than seeking a ‘new’ result. We believe such replications should not merely repeat existing work but to extend them through their application to, for example, updated data sets and to provide a comparison with the previously published work. It is not just pushing buttons on a computer software package, but involves a research-focused process, with all the academic rigour that entails.
We hope this will foster a great appreciation of replication studies and their importance, a stronger culture of verification, validity and robustness checking, and an encouragement to authors to engage with such work.
David McMillan is Professor Finance at the University of Stirling and a Senior Editor of Cogent Economics and Finance. He can be contacted at david.mcmillan@stir.ac.uk.
[From the article, “In Science, There Should Be a Prize for Second Place” published by Ed Yong in The Atlantic]
“This Monday, the editors of PLOS Biology—the flagship journal of Public Library of Science, a nonprofit publisher—published an editorial saying that they are now willing to publish papers that were scooped less than six months ago. And in a clever bit of rebranding, they’re abandoning the word “scooped” altogether in favor of calling these “complementary” papers.”
“The PLOS Biology editors argue that scooped—sorry, complementary—work is a kind of “organic replication.” After all, one team has effectively checked the work of another, albeit unintentionally. That should be a source of pride rather than shame. Both parties get independent confirmation that they were right. They should bump fists, rather than gnash teeth. “What’s perceived as a negative by the scientific community should be perceived as valuable research,” says Emma Ganley, the chief editor of PLOS Biology.”
[From the article “Robust research needs many lines of evidence” by Marcus Munafò and George Davey Smith, published in Nature]
“…replication alone will get us only so far. In some cases, routine replication might actually make matters worse. Consistent findings could take on the status of confirmed truths, when they actually reflect failings in study design, methods or analytical tools. We believe that an essential protection against flawed ideas is triangulation. This is the strategic use of multiple approaches to address one question. Each approach has its own unrelated assumptions, strengths and weaknesses. Results that agree across different methodologies are less likely to be artefacts.”
[From the article “Study that said hate cuts 12 years off gay lives fails to replicate”, posted at Retraction Watch]
“A highly cited paper has received a major correction as a result of the ongoing battle over attitudes towards gay people, when a prominent — and polarizing — critic showed it could not be replicated.”
“Stanford University Professor John Ioannidis, who has studied reproducibility but was not involved in either replication attempt … told us: ‘I suspect [coding errors are] a common problem, but it is rare for authors to go back and recheck what they did. A failed replication may be an incentive to go back and recheck the data and the analysis code, so this is one extra benefit from replication attempts.'”
[From the working paper, “How Often Should We Believe Positive Results? Assessing the Credibility of Research Findings in Development Economics” by Aidan Coville and Eva Vivalt]
Over $140 billion is spent on donor assistance to developing countries annually to promote economic development. To improve the impact of these funds, aid agencies both produce and consume evidence about the effects of development interventions to inform policy recommendations. But how reliable is the evidence that development practitioners use? Given the “replication crisis” in psychology, we may wonder how studies in international development stack up.
There are several reasons that a study could fail to replicate. First, there may be changes in implementation or context between the original study and the replication, particularly in field settings, where most applied development economics research takes place. Second, publication bias can enter into the research process. Finally, studies may simply fail to replicate due to statistical reasons. Our analysis focuses on this last issue, especially as it relates to statistical power.
Ask a researcher what they think a reasonable power level is for a study and, inevitably, the answer will be “at least 80%”. The textbook suggestion of “reasonable” and the reality are, however, quite different. Reviews for the medical, economic and general social sciences literature estimate median power to be in the range of 8% – 24% (Button et al., 2013; Ioannidis et al., forthcoming; Smaldino & McElreath, 2016). This reduces the likelihood of identifying an effect when it is present. Importantly, however, this also increases the likelihood that a statistically significant result is spurious and exaggerated (Gelman & Carlin, 2014). In other words, the likelihood of false negatives and false positives depends critically on the power of the study.
To explore this issue, we follow Wacholder et al. (2004)’s “false positive report probability” (FPRP), an application of Bayes’ rule that leverages estimates of a study’s power, the significance level, and the prior belief that an intervention is likely to have a meaningful impact to estimate the likelihood that a statistically significant effect is spurious. Using this approach, Ioannidis (2005) estimates that more than half of the significant published literature in biomedical sciences could be false. A recent paper by Ioannidis et al. (2017) finds 90% of the more general economic literature is under-powered. As further measures of study credibility, we explore Gelman & Tuerlinckx (2000)’s errors of sign (Type S errors) and magnitude (Type M errors), respectively the probability that a given significant result has the wrong sign and the degree to which it is likely exaggerated compared to the true effect.
In order to calculate these statistics for a particular study, an informed estimate of the underlying “true” effect of the intervention being studied is needed. The standard approach in the literature is to use meta-analysis results as the benchmark. This is possible in settings where a critical mass of evidence is available, but that kind of evidence is not always available, and meta-analysis results may themselves be biased depending on the studies that are included. As an alternative approach to estimate the likely “true” effect sizes of each study intervention, we gathered up to five predictions from each of 125 experts covering 130 different results across typical interventions in development economics. This was used to estimate the power and consequently false positive or negative report probabilities for each study. To focus on those topics that were the most well-studied within development, we looked at the literature on cash transfers, deworming programs, financial literacy training, microfinance programs, and programs that provided insecticide-treated bed nets.
Our findings in this subset of studies are less dramatic than estimates for other disciplines. The median power was estimated to be between 18% and 59%, largely driven by large-scale conditional cash transfer programs. Experts predict that interventions will have a meaningful impact approximately 60% of the time, across interventions. With these inputs, we calculate the median FPRP to be between 0.001 and 0.008, compared to the median significant p-value of 0.002. The likelihood of a significant effect having the wrong sign (Type S error) is close to 0 while the median exaggeration factor (Type M error) of significant results is estimated to be between 1.2 and 2.2.
In short, the majority of studies reviewed fair exceptionally well, particularly when referenced against other disciplines that have performed similar exercises. We must emphasize that other study topics in development economics not covered in this review may be less credible; conditional cash transfer programs, in particular, tend to have very large sample sizes and thus low p-values. The broader contribution of the paper is to highlight how analysis of study power and the systematic collection of priors can help assess the quality of research, and we hope to see more work in this vein in the future.
To read the working paper, click here.
Aidan Coville is an Economist in the Development Impact Evaluation Team (DIME) of the Development Research Group at the World Bank. Eva Vivalt is a Lecturer in the Research School of Economics at Australian National University. They can be contacted at acoville@worldbank.org and eva.vivalt@anu.edu.au, respectively.
[From an email sent on January 29, 2018 by Peter Rousseau, Secretary-Treasurer of the American Economic Association, to AEA Members ]
“The AEA has completed its search for the position of Data Editor, and is pleased to announce that Lars Vilhuber of Cornell University has been appointed. Lars will work with the AEA journal editors and Executive Committee to develop and implement methods to maximize replicability and reproducibility of research findings published in AEA journals. Such methods may involve some pre-publication verification of materials provided by authors, but will also encourage incorporating basic principles of replicability into researchers’ workflows and address the increasing reliance on restricted-access data. More information on Lars’ work can be found at http://lars.vilhuber.com.”

You must be logged in to post a comment.