[From the article “Make replication studies a normal part of science,” posted at the website of the Royal Netherlands Academy of Arts and Sciences]
“The systematic replication of other researchers’ work should be a normal part of science. That is the main message of the Academy advisory report Replication studies – Improving reproducibility in the empirical sciences. Funding agencies and scientific journals should also make it easier for researchers to carry out and publish replication studies. In addition, better research methods and more transparent study reporting will improve the reproducibility of research results.”
To read the report, click here.
[From the working paper, “Publication Bias and Editorial Statement on Negative Findings” by Cristina Blanco-Perez and Abel Brodeur]
Prior research points out that there is a selection bias in favor of positive results by editors and referees. In other words, research articles rejecting the null hypothesis (i.e., finding a statistically significant effect) are more likely to get published than papers not rejecting the null hypothesis. This issue may lead policymakers and the academic community to believe more in studies that find an effect than in studies not finding an effect.
Fortunately, innovations in social sciences are under way to improve research transparency. For instance, many scientific journals now ask the authors to share their codes and data to facilitate replication. Registration and pre-analysis plans are also becoming more popular for randomized controlled trials and lab experiments.
In this study, we test the impact of a simple, low-cost, new transparent practice that aims to reduce the extent of publication bias. In February 2015, the editors of eight health economics journals published on their journals’ websites an Editorial Statement on Negative Findings. In this statement, the editors express that: “well-designed, well-executed empirical studies that address interesting and important problems in health economics, utilize appropriate data in a sound and creative manner, and deploy innovative conceptual and methodological approaches […] have potential scientific and publication merit regardless of whether such studies’ empirical findings do or do not reject null hypotheses that may be specified.”
The editors point out in the statement that it: “should reduce the incentives to engage in two forms of behavior that we feel ought to be discouraged in the spirit of scientific advancement:
– Authors withholding from submission such studies that are otherwise meritorious but whose main empirical findings are highly likely `negative’ (e.g., null hypotheses not rejected).
– Authors engaging in `data mining,’ `specification searching,’ and other such empirical strategies with the goal of producing results that are ostensibly `positive’ (e.g., null hypotheses reported as rejected).”
We collect z -statistics from two of the eight health economics journals that sent out the editorial statement and compare the distribution of tests before and after the editorial statement. We find that test statistics in papers submitted and published after the editors sent out the editorial statement are less likely to be statistically significant. The figure below illustrates our results.

About 56%, 49% and 41% of z -statistics, respectively, are statistically significant at the 10%, 5% and 1% levels after the editorial in comparison with 61%, 55% and 49% of z -statistics before the editorial statement. Of note, we document that the impact of the statement intensifies over the time period studied.
As a robustness check, we look at whether there was a similar shift in the distribution of z -statistics at the time of the editorial statement for a non-health economics journal. On the contrary, we find that the distribution of z -statistics shifted to the right after the editorial statement for our control journal, possibly due to the increasing pressure to publish.
Overall, our results provide suggestive evidence that the decrease in the share of tests significant at conventional levels is due to both a change in editors’ preferences for negative findings and a change in authors and/or referees’ behavior.
Our results have interesting implications for editors and the academic community. They suggest that incentives may be aligned to promote a more transparent research and that editors may reduce the extent of publication bias quite easily.
Cristina Blanco-Perez is a Visiting Professor at the Economics Department of Ottawa. She can be contacted at cblancop@uottawa.ca. Abel Brodeur is Assistant Professor of Economics at the University of Ottawa. He can be contacted at abrodeur@uottawa.ca.
[From the recent working paper, “The statistical significance filter leads to overoptimistic expectations of replicability” by Vasishth, Mertzen, Jäger, and Gelman posted at PsyArXiv Preprints]
“…when power is low, using significance to decide whether to publish a result leads to a proliferation of exaggerated estimates in the literature. What is a reasonable alternative? …we can carry out a precision analysis (see chapter 13, Kruschke, 2014) before running an experiment to decide how much uncertainty of the estimate is acceptable. For example, a 95% credible interval of 40 ms is one option we chose in our final experiment, but this was only for illustration purposes; depending on the resources available, one could aim for even higher precision. For example, 184 participants in the Nicenboim et al. (2018) study had a 95% credible interval of 20 ms. Note that the goal here should not be to find an interval that does not include an effect of 0 ms; that would be identical to applying the statistical significance filter and is exactly the practice that we criticize in this paper. Rather, the goal is to achieve a particular precision level of the estimate.”
[From the recent working paper, “The Costs and Benefits of Replication Studies” by Coles, Tiokhin, Scheel, Isager, and Lakens, posted at psyarxiv.com/c8akj]
“The debate about whether replication studies should become mainstream is essentially driven by disagreements about their costs and benefits, and the best ways to allocate limited resources. Determining when replications are worthwhile requires quantifying their expected utility. We argue that a formalized framework for such evaluations can be useful for both individual decision-making and collective discussions about replication.”
[From the article “National Academies Launches Study of Research Reproducibility and Replicability” by Will Thomas, posted at FYI: Science Policy News from AIP (American Institute of Physics)]
“On Dec. 12 and 13, the National Academies convened the first meeting of a new study committee on “Reproducibility and Replicability in Science.” The National Science Foundation is sponsoring the study, which is expected to take 18 months, to satisfy a provision in the American Innovation and Competitiveness Act signed into law in January.”
“…In recent years, researchers, journalists, and policymakers have homed in on the reproducibility and replicability (R&R) of research results as a window into the health of the scientific enterprise. Many of them have taken widespread failures to replicate experimental results and to reproduce conclusions from data as a sign that, at least in certain fields, researchers’ experimental and statistical methods have become unreliable. To encourage better practices, those working to address such issues have been pressing to make research more transparent and to reform professional incentives.”
[From the article “Replication Studies” by David McMillan, Senior Editor of the journal Cogent Economics & Finance]
“Cogent Economics & Finance recognises the importance of replication studies. As an indicator of this importance, we now welcome research papers that focus on replication and whose ultimate acceptance depends on the accuracy and thoroughness of the work rather than seeking a “new” result. Cogent Economics & Finance has introduced a new replication studies article type that can be selected upon submission. We hope this will foster a great appreciation of replication studies and their significance, a stronger culture of verification, validity and robustness checking and an encouragement to authors to engage with such work, debate and discuss the best approaches to replication work and understand that an outlet for work of this kind exists.”
To see an updated list of economics journals that state that they publish replication studies, click here.
[From the working paper “Achieving Statistical Significance with Covariates and without Transparency” by Gabriel Lenz and Alexander Sanz]
“An important yet understudied area of researcher discretion is the use of covariates in statistical models. Researchers choose which covariates to include in statistical models and their choices affect the size and statistical significance of their estimates. How often does the statistical significance of published findings depend on nontransparent and potentially discretionary choices? We use newly available replication data to answer this question, focusing primarily on observational studies. In about 40%of studies, we find, statistical significance depended on covariate adjustments. The covariate adjustments lowered p-values to statistically significant levels, not primarily by increasing estimate precision, but by increasing the absolute value of researchers’ key effect estimates. In almost all cases, articles failed to reveal this fact.”
[From the article “The Replication Crisis in Science” by Shravan Vasishth at wired.com]
“There have been two distinct responses to the replication crisis – by instituting measures like registered reports and by making data openly available. But another group continues to remain in denial.”
In a previous post, I argued that lowering α from 0.05 to 0.005, as advocated by Benjamin et al. (2017) – henceforth B72 for the 72 coauthors on the paper, would do little to improve science’s reproducibility problem. Among other things, B72 argue that reducing α to 0.005 would reduce the “false positive rate” (FPR). A lower FPR would make it more likely that significant estimates in the literature represented real results. This, in turn, should result in a higher rate of reproducibility, directly addressing science’s reproducibility crisis. However, B72’s analysis ignores the role of publication bias; i.e., the preference of journals and researchers to report statistically significant results. As my previous post demonstrated, incorporating reasonable parameters for publication bias nullifies the FPR benefits of reducing α.
What, then, can be done to improve reproducibility? In this post, I return to B72’s FPR framework to demonstrate that replications offer much promise. In fact, a single replication has a sizeable effect on the FPR over a wide variety of parameter values.
Let α and β represent the rates of Type I and Type II error associated with a 5 percent significance level, with Power accordingly being given by (1-β). Let ϕ be the prior probability that H0 is true. Consider a large number of “similar” studies, all exploring possible relationships between different x’s and y’s. Some of these relationships will really exist in the population, and some will not. ϕ is the probability that a randomly chosen study estimates a relationship where none really exists. ϕ is usefully transformed to Prior Odds, defined as Pr(H1)/Pr(H0) = (1- ϕ)/ϕ, where H1 and H0 correspond to the hypotheses that a real relationship exists and does not exist, respectively. B72 posit the following range of Prior Odds values as plausible for real-life research scenarios: (i) 1:40, (ii) 1:10, and (iii) 1:5.
We are now in position to define the False Positive Rate. Let ϕα be the probability that no relationship exists but Type I error nevertheless produces a significant finding. Let (1-ϕ)(1-β) be the probability that a relationship exists and the study has sufficient power to identify it. The percent of significant estimates in published studies for which there is no underlying, real relationship is thus given by
(1) False Positive Rate(FPR) = ϕα / [ϕα +(1-ϕ)(1-β)] .
Table 1 reports FPR values for different Prior Odds and Power values when α = 0.05. The FPR values in the table range from 0.24 to 0.91. For example, given 1:10 odds that a studied effect is real, and assuming studies have Power equal to 0.50 – the same Power value that Christensen and Miguel (2017) assume in their analysis – the probability that a statistically significant finding is really a false positive is 50%. Alternatively, if we take a Power value of 0.20, which is about equal to the value that Ioannidis et al. (2017) report as the median value for empirical research in economics, the FPR rises to 71%.
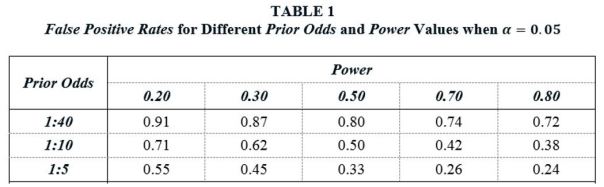
Table 1 illustrates the reproducibility problem highlighted by B72. The combination of (i) many thousands of researchers searching for significant relationships, (ii) relatively small odds that any given study is estimating a relationship that really exists, and (iii) a 5% Type I error rate, results in the published literature reporting a large number of false positives, even without adding in publication bias. In particular, for reasonable parameter values, it is very plausible that over half of all published, statistically significant estimates represent null effects.
I use this framework to show what a difference a single replication can make. The FPR values in Table 1 present the updated probabilities (starting from ϕ) that an estimated relationship represents a true null effect after an original study is published that reports a significant finding. I call these “Initial FPR” values. Replication allows a further updating, with the new, updated probabilities depending on whether the replication is successful or unsucessful. These new, updated probabilities are given below.
(2a) Updated FPR(Replication Successful) ) = InitialFPR∙α / [InitialFPR∙α +(1-InitialFPR)∙(1-β)] .
(2b) Updated FPR(Replication Unsuccessful) ) = InitiailFPR∙(1-α) / [InitialFPR∙(1-α) +(1-InitialFPR)∙β] .
Table 2 reports the Updated FPR values, depending on whether a replication is successful or unsuccessful, with Initial FPR values roughly based on the values in Table 1. Note that Power refers to the power of the replication studies.
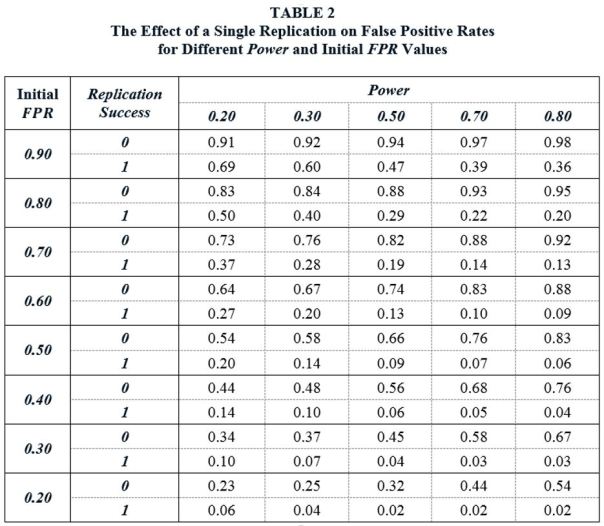
The Updated FPR values show what a difference a single replication can make. Suppose that the Initial FPR following the publication of a significant finding in the literature is 50%. A replication study is conducted using independent data drawn from the same population. If we assume the replication study has Power equal to 0.50, and if the replication fails to reproduce the significant finding of the original study, the FPR increases from 50% to 66%. However, if the replication study successfully replicates the original study, the FPR falls to 9%. In other words, following the replication, there is now a 91% probability that the finding represent a real effect in the population.
Table 2 demonstrates that replications have a sizeable effect on FPRs across a wide range of Power and Initial FPR values. In some cases, the effect is dramatic. For example, consider the case (Initial FPR = 0.80, Power = 0.80). In this case, a single, successful replication lowers the false positive rate from 80% to 20%. As would be expected, the effects are largest for high-powered replication studies. But the effects are sizeable even when replication studies have relatively low power. For example, given (Initial FPR = 0.80, Power = 0.20), a successful replication lowers the FPR from 80% to 50%.
Up to now, we have ignored the role of publication bias. As noted above, publication bias greatly affects the FPR analysis of B72. One might similarly ask how publication bias affects the analysis above. If we assume that publication bias is, in the words of Maniadis et al. (2017) “adversarial” – that is, the journals are more likely to publish a replication study if it can be shown to refute an original study – then it turns out that publication bias has virtually no effect on the values in Table 2.
This is most easily seen if we introduce publication bias to Equation (2a) above. Following Maniadis et al. (2017), let ω represent the decreased probability that a replication study reports a significant finding due to adversarial publication bias. Then if the probability of obtaining a significant finding given no real effect is InitialFPR∙α in the absence of publication bias, the associated probability with publication bias will be InitialFPR∙α∙(1-ω). Likewise, if the probability of obtaining a significant finding when a real effect exists is (1-InitialFPR)∙(1-β) in the absence of publication bias, the associated probability with publication bias will be (1-InitialFPR)∙(1-β)∙(1-ω). It follows that the Updated FPR from a successful replication given adversarial publication bias is given by
(3) Updated FPR(Replication Successful|Adversarial Publication Bias) = FPR∙α∙(1-ω) / [FPR∙α∙(1-ω) +(1-FPR)∙(1-β)∙(1-ω)] .
Note that the publication bias term in Equation (3), (1-ω), cancels out from the numerator and denominator, so that the Updated FPR in the event of a successful replication is unaffected. The calculation for unsuccessful replications is not quite as straightforward, but the result is very similar: the Updated FPR is little changed by the introduction of adversarial publication bias.
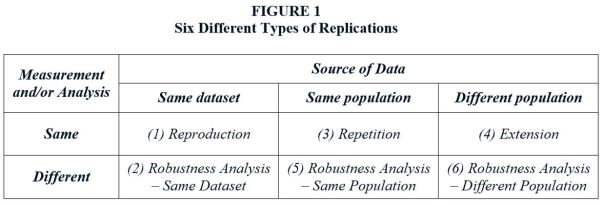
It needs to be pointed out that the analysis above refers to a special type of replication, one which reproduces the experimental conditions (data preparation, analytical procedures, etc.) of the original study, albeit using independent data drawn from an identical population. In fact, there are many types of replications. Figure 1 (see below) from Reed (2017) presents six different types of replications. The analysis above clearly does not apply to some of these.
For example, Power is an irrelevant concept in a Type 1 replication study, since this type of replication (“Reproduction”) is nothing more than a checking exercise to ensure that numbers are correctly calculated and reported. The FPR calculations above are most appropriate for Type 3 replications, where identical procedures are applied to data drawn from the same population as the original study. The further replications deviate from a Type 3 model, the less applicable are the associated FPR values. Even so, the numbers in Table 2 are useful for illustrating the potential for replication to substantially alter the probability that a significant estimate represents a true relationship.
There is much debate about how to improve reproducibility in science. Pre-registration of research, publishing null findings, “badges” for data and code sharing, and results-free review have all received much attention in this debate. All of these deserve support. While replications have also received attention, this has not translated into a dramatic increase in the number of published replication studies (see here). The analysis above suggests that maybe, when it comes to replications, we should take a lead from the title of that country-western classic: “A Little Less Talk And A Lot More Action”.
Of course, all of the above ignores the debate around whether null hypothesis significance testing is an appropriate procedure for determining “replication success.” But that is a topic for another day.
REFERENCES
[From the article, “Progress in Reproducibility” by Jeremy Berg, Editor-in-Chief Science Journals, published in the 5 January 2018 issue of Science]
“Over the past year, we have retracted three papers previously published in Science. The circumstances of these retractions highlight some of the challenges connected to reproducibility policies. In one case, the authors failed to comply with an agreement to post the data underlying their study. Subsequent investigations concluded that one of the authors did not conduct the experiments as described and fabricated data. Here, the lack of compliance with the data-posting policy was associated with a much deeper issue and highlights one of the benefits of policies regarding data transparency. In a second case, some of the authors of a paper requested retraction after they could not reproduce the previously published results. Because all authors of the original paper did not agree with this conclusion, they decided to attempt additional experiments to try to resolve the issues. These reproducibility experiments did not conclusively confirm the original results, and the editors agreed that the paper should be retracted. This case again reveals some of the subtlety associated with reproducibility. In the final case, the authors retracted a paper over extensive and incompletely described variations in image processing. This emphasizes the importance of accurately presented primary data.”
“As this new year moves forward, the editors of Science hope for continued progress toward strong policies and cultural adjustments across research ecosystems that will facilitate greater transparency, research reproducibility, and trust in the robustness and self-correcting nature of scientific results.”

You must be logged in to post a comment.